


Если ПТС дубликат, то чем это грозит
Главная » Разное
Хотите пройти тест по материалам статьи после ее прочтения?
ДаНет
При покупке машины может возникнуть достаточно сложностей и вопросов, и один из них: если ПТС дубликат (не оригинал), то чем это грозит будущему владельцу? Многие покупатели опасаются приобретать подержанный автомобиль с подобным документом, и это правильно.
Существует схема, по которой нечестные продавцы сбывают с рук авто, находящиеся под залогом или взятые в кредит.
Содержание
- В каких случаях выдается дубликат
- В чем опасность копии
- Как проверить машину с дубликатом при покупке
В каких случаях выдается дубликат
Если говорить кратко, то транспортные средства, на которые выданы дубликаты, могут быть в залоге у банка. При этом недобросовестные продавцы совершают мошеннические действия, легко реализуя машины с копией паспорта.
Однако может быть и другой, честный вариант, когда у автомобиля просто закончились свободные графы в ПТС, либо паспорт был на самом деле утерян. Например, копию выдают в случаях, когда:
Например, копию выдают в случаях, когда:
- ТС поменяло владельца и не было свободного места;
- паспорт был испорчен, украден, иным образом утрачен;
- сменилось место прописки собственника и не было свободного места для записи.
В чем опасность копии
Немного о том, чем грозит приобретение транспортного средства с копией ПТС. Когда машина состоит в залоге, то банк хранит оригинал паспорта у себя. Возвращает он его в случае погашения долговых обязательств. Но опытный человек легко может получить копию, написав заявление об утере в ГИБДД. Уже в этот же день ему выдадут дубликат с соответствующей пометкой. Имея подобный документ, мошенник может легко реализовать авто на вторичном рынке.
Купивший такую машину владелец столкнется с большими проблемами. С должника могут потребовать погашения долга через суд, а в случае невыплаты – возврата заложенного имущества финансово-кредитной организации. Суд всегда стоит за банки горой, а то, что нынешний владелец честно оплатил покупку, в расчет не принимается, ведь в любой ситуации купленное авто – это собственность банка, которой он распоряжается в полной мере.
В итоге покупатель теряет и деньги, и машину. Конечно при этом он вправе подать в суд на мошенника и вернуть деньги законным путем. Но ждать придется долго, а денег потратить много, если, конечно, продавец уже не испарился в неизвестном направлении.
Как проверить машину с дубликатом при покупке
Наличие копии ПТС должно насторожить покупателя. Для проверки транспортного средства с такой отметкой в паспорте существуют четыре варианта, которые обезопасят от мошеннических действий нечестных продавцов:
- Попросить проверить транспортное средство в ГИБДД. Если продавец не хочет этого делать, то что-то не так, лучше не рисковать, а отказаться от подобного приобретения, пусть даже и очень выгодного.
- Проверить авто в реестре залогов, зайдя на сайт Федеральной нотариальной палаты. Там необходимо ввести VIN-номер и узнать результат.
- Проверить на сайте ФССП, нет ли открытых исполнительных производств на собственника. Если есть, то продажа была незаконной, а значит недействительной.
 Но гарантировать полную чистоту таким способом нельзя. Исполнительные листы вбиваются в базу слишком долго, а за это время можно сбыть с рук залоговое имущество. Но для снижения рисков такой вариант подойдет.
Но гарантировать полную чистоту таким способом нельзя. Исполнительные листы вбиваются в базу слишком долго, а за это время можно сбыть с рук залоговое имущество. Но для снижения рисков такой вариант подойдет. - Позвонить в салон, если авто было куплено не так давно. Там предоставят информацию о том, кредитный ли это автомобиль или нет.
Продать машину, которая числится в собственности банка, дело непростое и рискованное, ведь продавца могут обвинить в афере и наказать в соответствии с КоАП. Поэтому при покупке авто с копией следует подстраховаться и обратить внимание на то, что, если у него слишком много бывших владельцев, то таким способом недобросовестные продавцы могут «заметать следы». Также не стоит покупать ТС с пробегом в автосалонах с проблемной репутацией и, тогда, когда собственник продает машину не только с дубликатом ПТС, но еще и по доверенности.
0 163 дубликат купля-продажа проверка документов проверка онлайн ПТС учет в ГИБДД
Максим Алексеевич/ автор статьи
Высшее юридическое образование. Более 20 лет опыт работы в органах внутренних дел.
Более 20 лет опыт работы в органах внутренних дел.
Понравилась статья? Сохраните для себя в социальных сетях::
Что делать при утере оригинала ПТС и как получить дубликат паспорта транспортного средства?
Паспорта, удостоверяющие личность, есть не только у людей. Каждый автомобиль также имеет свой собственный паспорт, который сокращенно называется ПТС. Как выглядит ПТС знает каждый водитель. Утеря паспорта транспортного средства ведет к невозможности нормально эксплуатировать машину. Ее нельзя поставить или снять с учета, пройти технический осмотр, продать. Неудивительно, что любой автовладелец сильно огорчается, когда обнаруживает утрату ПТС, ведь впереди непростая задача получения дубликата.
Оглавление
- 1 Что нужно делать при утрате ПТС?
- 2 Как получить дубликат ПТС?
- 3 Как выглядит дубликат ПТС?
- 4 Почему к дубликату ПТС люди относятся с недоверием?
- 5 Способы защиты дубликата ПТС
Что нужно делать при утрате ПТС?
Прежде чем отправляться в ГИБДД, рекомендуется тщательно обыскать машину, гараж (если имеется), дом. Возможно, утери документа не было, и он лежит где-нибудь за креслом или в бардачке, дожидаясь, когда хозяин его найдет.
Возможно, утери документа не было, и он лежит где-нибудь за креслом или в бардачке, дожидаясь, когда хозяин его найдет.
В том случае, если поиски все же не увенчаются успехом и подозрения на то, что документ украли, то нужно как можно быстрее отправиться в полицию и написать там заявление о краже. Полицейские возбудят уголовное дело, что сделает невозможным использование украденного ПТС в любых мошеннических схемах.
Если ПТС не был украден, то в полицию идти вовсе не стоит. Нужно обращаться сразу в МРЭО.
Некоторые «эксперты» советуют не обращаться в полицию, даже если оригинал ПТС был украден. Они аргументируют это тем, что дубликат не будет выдан до того момента, пока не полиция не закроет уголовное дело по заявлению автовладельца. На это уходит очень много времени. Не слушайте подобных советов. Заявление, поданное в полицию, защитит вас от мошеннических действий со стороны нарушителей и больших финансовых потерь.
Как получить дубликат ПТС?
Для получения дубликата паспорта транспортного средства нужно собрать небольшой пакет документов. Причем собрать их нужно до того, как автовладелец пойдет в ГИБДД или МРЭО. Перечень документов стандартный и не зависит от того, куда обратится человек, обнаруживший утрату ПТС.
Причем собрать их нужно до того, как автовладелец пойдет в ГИБДД или МРЭО. Перечень документов стандартный и не зависит от того, куда обратится человек, обнаруживший утрату ПТС.
- Документ, подтверждающий личность: паспорт, водительские права. Если эти документы были утрачены вместе ПТС, то нужно будет получить временное удостоверение. В нем обязательно должна быть вклеена фотография.
- Договор купли-продажи. Он будет служить доказательством того, что заявитель действительно является владельцем автомобиля. Если вместо ДКП имеется в наличии доверенность, то в ней должен быть пункт, указывающий на возможность совершения регистрационных действий с автомобилем.
- СТС.
- Полис ОСАГО. Его почти никогда не требуют, но лучше иметь его в наборе документов.
- Квитанция об оплате государственной пошлины.
- Заявление с указанием причины, по которой требуется получить дубликат ПТС.
Нередко при сдаче документов в МРЭО сотрудники ГИБДД просят дополнительно написать объяснительную на официальном бланке. Отказаться не получится. Поэтому для экономии собственного времени в объяснительной не вдавайтесь в подробности, описывая факт утраты ПТС.
Отказаться не получится. Поэтому для экономии собственного времени в объяснительной не вдавайтесь в подробности, описывая факт утраты ПТС.
Иногда сотрудники МРЭО просят принести дополнительные документы. Если это требование не подтверждено письменно, то оно является незаконным.
Перед выдачей дубликата сотрудники ГИБДД обязаны осмотреть транспортное средство. Это значит, владельцу нужно позаботиться о том, чтобы машина была чистой. Кроме того, нужно убедиться в том, что все номера агрегатов хороши читаются. В противном случае инспектор вправе отказаться от проверки.
Если все формальности соблюдены, владелец машины сможет получить дубликат ПТС через несколько дней.
Иногда автовладельцы получают отказ в получении дубликата. Причин тому может быть несколько:
- Сотрудники ГИБДД сомневаются в том, что автомобиль «чист» с юридической точки зрения.
- Выявлены нарушения в предоставленных документах.
- Инспектор, осматривающий автомобиль выявил нарушения.

Отказ в выдаче дубликата – не повод для огорчения. Его всегда можно опротестовать. Для этого нужно сделать копии документов, приложить к ним письменный отказ и с этими бумагами пойти к начальнику отделения ГИБДД. Если начальник не поможет, то можно попытаться решить проблему через суд.
Как выглядит дубликат ПТС?
Паспорт транспортного средства и его дубликат являются документами строгой отчетности. Эти бумаги печатаются на предприятиях «Гознака». По этой причине они оснащены несколькими этапами защиты. Внешне между оригиналом ПТС и копией различия нет. Различаются оба документа штампом, проставляемым на дубликате в процессе его выдачи. Синюю прямоугольную печать с надписью «дубликат» можно обнаружить в графе «особые отметки».
Что касается юридической силы оригинала и дубликата, то она одинакова. Дубликат ПТС позволяет совершать с автомобилем все те же действия, что и оригинал этого документа.
Большинство начинающих автовладельцев уверены, что оригинал паспорта транспортного средства сильно отличается от дубликата. Это не так. Как уже говорилось выше, разница заключается лишь в штампе. В дубликате имеются все те же 24 графы с указанием основной информации о машине и ее текущем хозяине. Правы новички лишь в одном – дубликат отличается от оригинала уровнем доверия.
Это не так. Как уже говорилось выше, разница заключается лишь в штампе. В дубликате имеются все те же 24 графы с указанием основной информации о машине и ее текущем хозяине. Правы новички лишь в одном – дубликат отличается от оригинала уровнем доверия.
Почему к дубликату ПТС люди относятся с недоверием?
На вторичном рынке к дубликатам ПТС люди относятся с большим недоверием. Объясняется многочисленными случаями мошенничества при продажах автомобилей, бывших в употреблении, с дубликатами ПТС. По новым законам для продажи машины вовсе не нужно снимать ее с учета и посещать ГИБДД. Значит, автомобиль не проверяется на возможные ограничения регистрационных действий. Соответственно, есть вероятность приобрести с машиной, на которую выписан дубликат транспортного средства, различные проблемы.
Конечно, проблемы с копией ПТС приходят далеко не всегда. Люди действительно теряют оригинал либо в нем заканчиваются свободные графы для записи новых владельцев машины. Однако, риск неприятностей сохраняется.
Однако, риск неприятностей сохраняется.
Чаще всего по дубликатам ПТС продают автомобили, находящиеся в залоге у кредитной организации. Как известно, до момента полной выплаты кредита ПТС на кредитный автомобиль находится у банка. Продать такую машину можно лишь получив дубликат ПТС. А поскольку особых условий для получения копии ПТС нет, то этим часто пользуются мошенники. При этом покупатель такой машины своими силами не сможет узнать полную ее историю. Впрочем, есть несколько советов, следуя которым можно избежать проблем с аферистами:
- Неважно по какой причине был выдан дубликат ПТС. Покупателю нужно обратить внимание на первого владельца машины. Чаще всего это автосалон. Нужно связаться с его представителями и уточнить информацию о покупаемой машине.
- Покупатель должен насторожиться, если автомобиль с копией паспорта транспортного средства продается по слишком низкой цене, но при этом имеет отличное состояние.
- Нужно пользоваться достижениями технического прогресса.
 В интернете множество сервисов, позволяющих проверить автомобиль по VIN -номеру на ряд важных параметров.
В интернете множество сервисов, позволяющих проверить автомобиль по VIN -номеру на ряд важных параметров.
Если продавец показывает копию ПТС, но машина вам нравится, а неприятностей не хочется, то можно предложить продавцу проехать в ГИБДД, где сотрудники ГАИ проведут проверку машины. В этом случае риск быть обманутым станет минимальным.
Перед покупкой тщательно сверяйте номера и маркировки всех агрегатов с теми, что указаны в ПТС. Дело в том, что мошенники могут предоставить непросто дубликат ПТС, а подделку. При этом на машине обязательно будут перебиты номера. По такой схеме реализуются угнанные автомобили.
Способы защиты дубликата ПТС
Знание этой информации в большинстве случаев позволяет избежать проблем при покупке авто с дубликатом паспорта транспортного средства на вторичном рынке.
- Дубликат всегда печатается на шероховатой бумаге. Фальшивки в большинстве случаев имеют глянцевую поверхность.
- У водяных знаков на оригинальном документе размыты края.
 Если в дубликате они четкие, то ,вероятнее всего, перед вами подделка.
Если в дубликате они четкие, то ,вероятнее всего, перед вами подделка. - Голографический штамп на оригинальной бумаге обладает ярко выраженным глянцем. Цвета на нем меняется при любом угле наклона. На фальшивках голографический штамп слегка тусклый и матовый. Звездочки в нем крупнее чем в оригинальном документе.
Покупая, машину изучите каждую запись о владельцах в дубликате. Буквы не должны быть затерты или исправлены. В обязательном порядке нужно обращать внимание на «особые отметки». Например, отметка о снятии с учета для последующей утилизации делает невозможной дальнейшую законную эксплуатацию автомобиля.
Как измерить повторяющиеся показатели
Специальное демонстрационное издание Апрель 2013 г.
Как измерять коэффициент дублирования
Майк Бассет
Для протокола
Vol. 25 № 7 стр. 18
25 № 7 стр. 18
Существует ли единственное решение? Специалисты отрасли обсуждают различные нюансы, связанные с расчетом «лишних» медицинских карт.
Большинство медицинских учреждений давно осознали, что их основные индексы пациентов (MPI) имеют проблемы, связанные с качеством данных, особенно связанные с дублированием записей.
Коэффициент дублирования MPI — это число, имеющее большое значение. Например, высокий показатель означает, что в учреждении могут возникнуть проблемы с отсутствием клинической информации, повторными тестами и лечением, задержками с выставлением счетов и дебиторской задолженностью, а также с повышенным риском медицинских ошибок.
По данным AHIMA, средний уровень дублирования в больничных условиях составляет примерно 10%. В идеале, оптимальная частота дублирования, в зависимости от настройки, должна быть менее 5%. Что приводит к вопросам: как рассчитывается этот показатель и что представляет собой это число?
По словам Лу Энн Видеманн, MS, RHIA, FAHIMA, CDIP, CPEHR, директора по совершенствованию практики HIM в AHIMA, рекомендации ассоциации по вычислению фактической частоты дублирования записей в одной базе данных включают деление общего количества записей о пациентах в базе данных. базу данных MPI в общее количество отдельных записей-дубликатов пациентов, умноженное на 100. Общее количество отдельных записей-дубликатов — это количество дополнительных записей по сравнению с исходными записями. Например, если у каждого из 50 пациентов по две записи, количество дублирующихся записей будет равно 509.0007
базу данных MPI в общее количество отдельных записей-дубликатов пациентов, умноженное на 100. Общее количество отдельных записей-дубликатов — это количество дополнительных записей по сравнению с исходными записями. Например, если у каждого из 50 пациентов по две записи, количество дублирующихся записей будет равно 509.0007
Виктория Уитли, MS, RHIA, вице-президент по обслуживанию клиентов для решений доступа пациентов в поставщике программного обеспечения для здравоохранения QuadraMed, подписывается на модель, которая влечет за собой поиск записей, участвующих в любом дублировании. В паре дубликатов одна запись обозначается как «уцелевшая», а другая — как «удаленная» и считается дубликатом для целей расчета коэффициента. Но она добавляет, что некоторые методы расчета определяют дубликаты как общее количество записей, вовлеченных в дублирование, независимо от того, считается ли запись оригиналом или дубликатом.
Но она добавляет, что некоторые методы расчета определяют дубликаты как общее количество записей, вовлеченных в дублирование, независимо от того, считается ли запись оригиналом или дубликатом.
Линч указывает, что могут быть сценарии, которые поднимают вопрос о том, как считать исходную запись, если она имеет несколько дубликатов. Должен ли он учитываться один или два раза, если у него есть два дубликата? Он говорит, что использование методологического подхода «Шесть сигм» для расчета коэффициента может внести некоторую ясность в процесс, а также помочь измерить более широкое определение целостности данных.
В подходе «Шесть сигм» организация здравоохранения указывает, что каждая запись в MPI должна представлять одного пациента и быть уникальной и отличимой от всех других записей. Следовательно, «дефект» MPI — это любая запись, которая представляет того же пациента, что и другая запись. «Каждый директор HIM хочет, чтобы каждая запись в его базе данных представляла одного отдельного пациента, — говорит Линч.
Использование такой методологии имеет несколько преимуществ, говорит Линч. «Мы считаем, что коэффициент дублирования не должен быть единственной мерой качества, которая должна применяться к MPI, и что должно быть более широкое определение качества, определяемое как целостность данных», — говорит он. «И по мере того, как вы расширяете определение того, что такое дефект, и применяете его к таким вещам, как отсутствующие или неправильные номера социального страхования или информация об изображениях, это может быть интегрировано в общую меру целостности данных. Мы думаем, что это довольно интересный взгляд на проблему, и его легко понять».
Сьюзен Симс, менеджер проекта MPI компании Evrichart, соглашается, указывая, что это также лучший способ измерения степени неэффективности, существующей в MPI. Например, «Сколько строк данных нужно будет проверить, чтобы доказать или опровергнуть двуличность?» она спрашивает. «Я могу думать, что у меня есть 30% дубликатов из 100 элементов, основанных на рекомендациях AHIMA, но на самом деле нужно проверить 60 строк».
Например, «Сколько строк данных нужно будет проверить, чтобы доказать или опровергнуть двуличность?» она спрашивает. «Я могу думать, что у меня есть 30% дубликатов из 100 элементов, основанных на рекомендациях AHIMA, но на самом деле нужно проверить 60 строк».
Seams считает, что метод «Шесть сигм» обеспечивает «более точный взгляд» на количество строк данных и процентную долю данных, содержащихся в MPI, которые необходимо изучить.
Правдивое чтение
Действительно ли организации здравоохранения знают свои показатели дублирования? Уитли так не думает. «Многие из них так думают, потому что они используют отчеты из больничных информационных систем», — говорит она. «Но, как правило, они занижают проблему, потому что инструменты для обнаружения дубликатов и создания отчетов в большинстве существующих стандартных систем довольно рудиментарны».
Однако это может измениться, говорит Уитли, поскольку организации здравоохранения, особенно крупные, более внимательно следят за коэффициентами дублирования, когда проводят аттестацию значимого использования, подключаются к обмену медицинской информацией или внедряют новые клинические системы.
Существуют и другие причины, по которым учреждения должны иметь строгий контроль над уровнем дублирования. «Поскольку организации здравоохранения вкладывают значительные средства в информационные системы здравоохранения, они хотят иметь возможность измерять окупаемость своих инвестиций», — говорит Дэн Сидон, главный технический директор NextGate, поставщика корпоративных решений для управления идентификацией. «Вы хотите придумать значимую метрику, чтобы показать, как данные улучшались с течением времени», — отмечает он.
Переизбыток дубликатов записей может иметь серьезные финансовые последствия. Сайдон говорит, что исследования показали, что затраты организации могут достигать 20 долларов за дубликат записи из-за связанной с этим административной нагрузки. Уитли говорит, что один клиент провел оценку затрат на внедрение программного обеспечения и обнаружил, что ежегодно тратит 250 000 долларов на повторяющиеся исправления. «Мы говорим нашим клиентам, что в зависимости от того, что мы учитываем в стоимости, она может составлять от 5 до 10 долларов за дубликат, если вы просто учитываете канцелярское время [вовлеченное], и до тысяч долларов за дубликат клинического исследования.
Сайдон говорит, что если значение может быть присвоено дублирующейся записи, «умножьте его на некоторый коэффициент, представляющий, сколько долларов вы используете [для исправления ошибки], и вы сможете четко объяснить руководству, какую отдачу от инвестиций они получают, не заставляя административный персонал искать записи, которые отделены друг от друга».
Скорость также сообщает провайдеру, в какой степени у него есть проблема с качеством данных, и может помочь ему определить, какой план действий ему необходимо разработать. «Он должен сообщать организации, сколько ресурсов ей нужно потратить на свой MPI и дублирование», — говорит Видеманн.
Более конкретно, уровень дублирования сообщит организации об уровне риска, в котором она работает, поскольку дублирование записей вызывает множество проблем в таких областях, как клиническая помощь, возмещение расходов и внедрение клинических систем, по словам Уитли.
Если организации известны масштабы проблемы, добавляет она, она может определить не только необходимость какого-либо вмешательства, но и определить приоритетность реагирования, чтобы быстро решить определенные проблемы, такие как отсутствующие элементы данных.
Частота проверок на наличие ошибок
Как часто следует рассчитывать показатели дублирования? Линч говорит, что конкретного отраслевого стандарта нет, но рекомендует проводить его не реже одного раза в месяц в зависимости от средств контроля, реализованных на уровне регистрации пациентов. «Если у вас есть действительно хорошие средства контроля и вы не создаете много дубликатов, вам нужно делать это реже, чем в тех учреждениях, которые не имеют таких хороших средств управления», — объясняет он.
Сайдон говорит, что некоторые организации еженедельно отслеживают уровень дублирования, чтобы улучшить процессы и получить немедленную обратную связь по любым из этих последующих усилий. Это должен быть довольно простой процесс, говорит он, указывая на то, что «в нашей системе [статистические данные] хранятся в базе данных, к которой очень легко получить доступ с помощью любого количества инструментов отчетности».
На исполнительном уровне, по словам Сайдона, администраторы хотят ежеквартально получать дублирующую информацию о скорости, чтобы иметь представление о качестве данных в MPI. В результате они могут определить, приносят ли их усилия по управлению информацией желаемую отдачу от инвестиций.
Уитли говорит, что организации здравоохранения всегда должны следить за уровнем дублирования. «Я предвзята, поскольку работаю в компании, которая продает программное обеспечение и услуги, но это должен быть непрерывный процесс», — говорит она. «Однажды я сказал отделу управления медицинской информацией, что какой бы инструмент у вас ни был — плохой он или самый лучший, который можно купить за деньги, — вы должны использовать его для наблюдения за коэффициентами дублирования, чтобы иметь возможность оставаться на вершине на регулярной основе. основа. Если вы не будете следить за этим каждый день, дубликаты будут создаваться каждый день».
основа. Если вы не будете следить за этим каждый день, дубликаты будут создаваться каждый день».
— Майк Бассетт — независимый писатель из Холлистона, штат Массачусетс.
Ошибка MPI становится личной для супервайзера HIM
Хотя дублирование записей в основном каталоге пациентов может иметь серьезные последствия для организации здравоохранения, воздействие на отдельных пациентов может быть столь же, если не более серьезным, серьезным. Сьюзан Бэйли, RHIT, супервайзер HIM в больнице на западе США, может говорить на эту тему и как поставщик, и как потребитель. За последние 10 лет она четыре раза становилась жертвой ошибочной идентификации пациентов.
Большинство инцидентов были довольно незначительными по своему характеру, например, получение уведомления о льготах за посещение хиропрактики, которое так и не произошло. Но одна путаница связана с КТ-обследованием, которое она не проходила по поводу хронического заболевания, которого нет в ее медицинской карте.
Во время консультации врач заметил, что в карте Бейли указано, что она недавно прошла компьютерную томографию. «Я сказала ему: «Я много лет не заходила в отделение радиологии, разве что для того, чтобы причинить им горе», — говорит она. «И он сказал: «О, вот почему я всегда спрашиваю пациентов о новых обследованиях, чтобы убедиться, что они их».
Мало того, что информация была неверной, она заставила Бэйли задуматься о том, что может случиться, если она окажется в отделении неотложной помощи и получит лекарство от заболевания, которого у нее нет. «Это немного пугает, — говорит она.
Бейли предполагает, что каждая из проблем возникла из-за ошибок, допущенных при регистрации пациентов. Это неудивительно — спросите специалистов HIM о том, как создается большинство повторяющихся записей, и они начнут с проблем, связанных с именами пациентов.
«Некоторые элементы данных изначально плохо структурированы, — говорит Дэн Сайдон, технический директор NextGate. «Возможно, при первой встрече пациент называет свое имя Лиз Смит, а при второй — Элизабет. То же самое касается адресов. Существуют тысячи способов представления адреса. Все это в конечном итоге приводит к записям, которые очень трудно сопоставить друг с другом, если у вас нет очень сложного, точно настроенного алгоритма для решения таких проблем с данными».
То же самое касается адресов. Существуют тысячи способов представления адреса. Все это в конечном итоге приводит к записям, которые очень трудно сопоставить друг с другом, если у вас нет очень сложного, точно настроенного алгоритма для решения таких проблем с данными».
Хотя причину проблемы легко объяснить, решение далеко не простое, говорит Бэйли. «Устранение этих проблем — просто огромная проблема, — говорит она. «Я не думаю, что люди действительно понимают, насколько это сложно на самом деле. Большая часть ответа должна зависеть от получения точной идентификации пациента заранее, потому что, когда эта [неточная] информация попадает в [основной список пациентов], получить ее становится сущим кошмаром».
— МБ
11 Расширенные способы идентификации и дедупликации данных клиентов
Если вы отвечаете за управление данными клиентов, почти наверняка вы сталкивались с головной болью, связанной с дублированием данных. Независимо от того, оказались ли эти дубликаты данных в вашей системе в результате заполнения форм клиентами, ввода вашей командой данных вручную или импорта с внешних платформ — последствия этих дубликатов данных одинаковы и довольно дорогостоящи.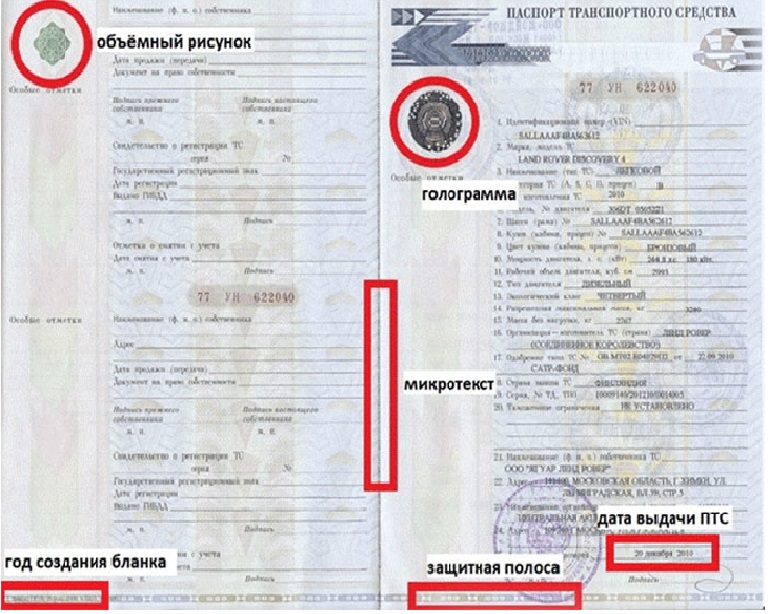
На самом деле затраты, связанные с дублированием данных, выше, чем вы можете себе представить. Проблемы с качеством данных ежегодно обходятся американским предприятиям в более чем 600 миллиардов долларов. Дублирование контактов, компаний и сделок в вашей CRM может быть проблемой данных, наиболее тесно связанной с этими затратами, связанными с качеством данных. Они вредят отношениям с клиентами. Они распространены в большинстве баз данных CRM, и их влияние на ваши инициативы в области маркетинга, продаж и поддержки часто легко заметить.
Дубликаты критически сказываются на отделах продаж. В базах данных с высоким уровнем дублирования торговые представители вынуждены изменить свои стандартные процессы продаж, включив в них проверку на наличие дубликатов, иначе они рискуют привлечь потенциальных клиентов и клиентов, упустив жизненно важный контекст, что навредит отношениям с клиентами.
Они наносят ущерб вашей автоматизации маркетинга, вызывая неловкие ошибки, которые наносят ущерб репутации вашего бренда и истощают ваш маркетинговый бюджет. 40% лидов содержат неверные данные. Поскольку 33% компаний имеют более 100 000 записей о клиентах в своей CRM, исправление этих проблем представляет собой существенную возможность для роста.
40% лидов содержат неверные данные. Поскольку 33% компаний имеют более 100 000 записей о клиентах в своей CRM, исправление этих проблем представляет собой существенную возможность для роста.
Повторяющиеся записи контактов также отрицательно сказываются на вашей способности предлагать качественное обслуживание клиентов. Если клиент связывается с вашей поддержкой по телефону, электронной почте или в чате, ваша поддержка будет медленнее и менее эффективной, когда им придется копаться в нескольких записях клиентов, чтобы найти правильный профиль клиента. Быстрый доступ к этим данным клиентов имеет решающее значение для их работы.
Тем не менее, любой, кто занимался очисткой дубликатов данных, знает, что использование простых значений точного соответствия для выявления дубликатов оставляет много мяса на костях. На самом деле, вы можете оставить большинство дубликатов в вашей базе данных.
Чтобы по-настоящему освоить дедупликацию данных в CRM, вам нужно копнуть глубже.
Когда вы начинаете заглядывать вглубь поверхностных дубликатов, вы начинаете обнаруживать, что в средней базе данных CRM есть много таких, которые выходят за рамки очевидных дубликатов с точным соответствием, где вода более мутная.
Эти менее традиционные сценарии с дубликатами гораздо более распространены, чем думает большинство людей, и о них необходимо подумать, если вы хотите удалить дубликаты из своей базы данных.
В этой статье мы рассмотрим некоторые из более сложных типов дубликатов записей, которые вы, вероятно, найдете в своих базах данных CRM.
К ним относятся:
Расширенная дедупликация данных клиентов Содержание
- Общие термины, выраженные по-разному
- Краткие имена и прозвища
- Опечатка
- Заголовки и суффиксы
- Рекомендации по URL-адресу веб-сайта
- Сопоставление по сходству (фаззинговое сопоставление)
- Идентификаторы внешней системы
- Обнаружение дубликатов «того или иного»
- Телефонные номера в разных форматах
- Проверка по похожим полям
- Частичные совпадения
- Insycle — Расширенное обнаружение повторяющихся записей
1.
 Общие термины, выраженные по-разному
Общие термины, выраженные по-разномуОдним из наиболее распространенных способов скрыть дублирование данных о клиентах в базе данных является использование общих терминов, выраженных по-разному.
Рассмотрим несколько примеров.
Допустим, вы запустили процесс дедупликации контактных данных в HubSpot и используете название компании как один из основных способов сопоставления повторяющихся записей в базе данных.
Ну, название компании может быть выражено по-разному в отдельных записях о клиентах, которые на самом деле являются дубликатами.
Например:
- Microsoft Inc.
- Корпорация Майкрософт
Если название компании выражается по-разному, это может привести к тому, что вы пропустите повторяющиеся записи, даже если тот факт, что они могут быть избыточными данными, очевиден.
Рассмотрим другой пример — названия должностей.
- Генеральный директор
- ГЕНЕРАЛЬНЫЙ ДИРЕКТОР
- Главный исполнительный директор
Вот почему так важна стандартизация данных. В противном случае выявление повторяющихся данных о клиентах практически невозможно. Если у вас нет процессов стандартизации, ваша CRM наверняка будет иметь такие дубликаты записей.
В противном случае выявление повторяющихся данных о клиентах практически невозможно. Если у вас нет процессов стандартизации, ваша CRM наверняка будет иметь такие дубликаты записей.
Связанные статьи Как объединить дубликаты в HubSpot и Salesforce и обеспечить их синхронизацию Распространенные проблемы с качеством данных HubSpot и способы их устранения Как дубликаты контактов HubSpot наносят ущерб вашей маркетинговой команде и истощают ваш бюджет |
2. Краткие имена и прозвища
Люди часто известны под несколькими именами. Они могут использовать более короткую, более обычную версию своего имени, псевдоним или использовать инициалы.
Например, если человека звали Джонатан Пол Джонсон, вы можете увидеть его имя, представленное разными способами в нескольких повторяющихся записях контактов CRM:
- Джонатан Джонсон
- Джон Джонсон
- Джон Пол Джонсон
- Джонатан Пол Джонсон
- Дж.
 П. Джонсон
П. Джонсон - Дж. П. Джонсон
Кроме того, у него может быть прозвище вроде «Бад», «Младший» или что-то неожиданное. В любом из этих случаев было бы очень легко пропустить дубликат записи, используя обычные процедуры обнаружения дубликатов.
3. Опечатки
Опечатки всегда присутствуют, когда за ввод данных отвечает человек. Поэтому, если у вас есть формы для клиентов или сотрудников (это означает, что вы не собираете все данные с помощью автоматических средств), вы можете быть уверены, что в вашей базе данных есть дубликаты данных, которые пропускают ваши проверки из-за этих опечаток.
Средняя частота ошибок при вводе данных человеком составляет 1%. Это означает, что одно из каждых сотен нажатий клавиш, вероятно, будет неправильным.
Источник: Datapine
У вас могут возникнуть проблемы с такими компаниями, как:
- Microsoft
- Микросифт
Или с именами, например:
- Джейн
- Джейм
Любое поле , в котором используются вводимые человеком данные, будет иметь проблемы, особенно в больших клиентских базах данных. Эти проблемы затрудняют поиск повторяющихся данных о клиентах.
Эти проблемы затрудняют поиск повторяющихся данных о клиентах.
4. Названия и суффиксы
Контактные данные с суффиксом наименования также могут привести к тому, что вы пропустите очевидные повторяющиеся записи в базе данных клиентов.
Используя наш предыдущий пример с человеком по имени Джонатан Джонсон, у вас могут быть повторяющиеся записи, которые выглядят так:
- Доктор Джонатан Джонсон
- Доктор Джон Джонсон
- г-н Джонатан Джонсон
- Джонатан Джонсон младший
- Джонатан Джонсон III
- Джонатан Джонсон, эсквайр.
Название и суффикс учитываются независимо от того, откуда были получены данные — были ли они введены самим человеком или получены из стороннего списка.
5. Соображения относительно URL-адреса веб-сайта
Использование URL-адреса веб-сайта для поиска повторяющихся записей является обычным делом для компаний в CRM.
Между двумя записями клиентов поле может включать или не включать «www». или «http://» в URL-адресе, из-за чего вы пропустите повторяющиеся записи.
или «http://» в URL-адресе, из-за чего вы пропустите повторяющиеся записи.
Или разные записи клиентов могут иметь разные домены верхнего уровня. Например, microsoft.com и microsoft.co.uk
Еще одна распространенная причина пропуска повторяющихся записей — субдомены. Например, в университете может быть много факультетов, ведущих к множеству различных доменных путей как в виде перечисленных URL-адресов, так и доменов электронной почты — math.school.edu, english.school.edu, physics.school.edu и т. д.
Все эти веб-сайты Необходимо проверить URL-адреса, чтобы убедиться, что ваша база данных не содержит потенциальных проблем.
6. Сопоставление по сходству (AKA Fuzzy Matching)
Если полагаться только на идентификацию «точное совпадение», в вашей CRM всегда останется много дубликатов. Слишком много вариаций, которые могут быть во многих полях, чтобы это было эффективно.
«Нечеткое сопоставление» или приблизительное сопоставление строк — это программный метод анализа данных и выявления записей о клиентах, которые похожи, но не являются точными совпадениями. Он работает, анализируя «близость» двух разных точек данных.
Он работает, анализируя «близость» двух разных точек данных.
Близость определяется путем измерения количества изменений, необходимых для совпадения двух точек данных. Это известно как «расстояние редактирования», которое рассматривает количество различий вставки, удаления и замены, необходимых для точного совпадения двух разных точек данных.
- вставка: бар → b a r n
- удаление: ba r n → бар
- замена: бар n → бар k
Без аналогичных и нечетких процессов сопоставления вы никогда не найдете все дубликаты в большой базе данных.
В маркетинге и продажах на основе учетной записи это может привести к тому, что ваша команда упустит возможность взаимодействия с важными заинтересованными сторонами в рамках учетной записи и приведет к упущенным продажам.
Нечеткое сопоставление повторяющихся данных клиентов применимо практически к любому полю в вашей CRM. В вашей базе данных вы найдете всевозможные тонкие различия, о большинстве из которых вы даже не подумали бы, пока не увидели их в действии.
В вашей базе данных вы найдете всевозможные тонкие различия, о большинстве из которых вы даже не подумали бы, пока не увидели их в действии.
Когда вы увидите, насколько распространена эта проблема, вы, естественно, начнете задаваться вопросом, сколько из этих проблем есть в вашей CRM и какое влияние они оказывают на вашу прибыль.
7. Идентификаторы внешней системы
Внешние идентификаторы необходимы для интеграции и синхронизации двух разъединенных платформ для корреляции записей о клиентах в разных системах. Процессы дедупликации данных часто должны учитывать эти идентификаторы внешних систем, чтобы убедиться, что синхронизация контактных данных не нарушена.
Например, вы хотите использовать автоматизацию маркетинга для отправки электронных писем своим потенциальным клиентам и клиентам. Ну, вы хотите, чтобы это также отражалось в вашей CRM-системе продаж, чтобы представители имели полный контекст для своих взаимодействий.
Интеграция HubSpot и Salesforce может вызвать множество проблем с данными между двумя платформами.
То же самое верно для интеграции между любыми двумя CRM или разными платформами, которые собирают разные типы данных или используют разные имена полей для представления одной и той же информации.
В любой популярной CRM одним из полей будет идентификационный номер, который используется для идентификации записи. Это поле идеально подходит для выявления повторяющихся записей, которые часто упускают из виду при очистке данных.
Например, вы можете использовать идентификатор контакта Salesforce для выявления повторяющихся записей контактов в HubSpot. Изменения в ваших данных в HubSpot могли привести к тому, что синхронизация создала две разные записи, хотя на самом деле она должна была добавить или обновить данные в исходной записи.
8. Обнаружение дубликатов «того или иного»
Одна большая проблема заключается в том, что многие записи о клиентах-дубликатах ускользают из виду, потому что компания сосредоточена на выявлении дубликатов с помощью заданных полей, не применяя никаких вторичных проверок, чтобы убедиться, что они не повторяются. не пропустите ни одного.
не пропустите ни одного.
Например, вы можете в первую очередь идентифицировать дубликаты по имени, фамилии и номеру телефона. Вы поймаете большую часть своих дубликатов записей, проверив эту комбинацию полей.
Но ввод вторичной проверки, когда первая не может определить дубликат, такой как Имя, Фамилия, Адрес, может помочь вам найти и исправить свободно плавающие дубликаты, которые в противном случае были бы пропущены.
9. Телефонные номера в различных форматах
Телефонные номера часто используются для идентификации повторяющихся контактов и учетных записей в CRM.
Логично. Контакт с двумя повторяющимися записями, скорее всего, ввел бы один и тот же номер телефона для обеих. Кроме того, маловероятно, что организации будут часто менять свои основные номера, поэтому это может служить надежным полем для обнаружения дубликатов.
Однако есть некоторые проблемы с использованием телефонных номеров в качестве основного поля для этой цели.
Во-первых, есть много способов отформатировать телефонный номер в вашей базе данных. Например:
Например:
- 1234567890
- 123-456-7890
- (123)-456-7890
- 123.456.7890
- 1-123-456-7890
- 123 456 7890
- и т. д.
Обычно это означает, что использование поля номера телефона оставит в базе данных много неопознанных дубликатов.
Это поле также может содержать много опечаток и других ошибок. Это означает, что они могут содержать пробелы или неправильные числа. Они могут включать добавочный номер, что приводит к включению «#» в некоторые поля вашего телефона.
10. Проверка в похожих полях
Ваша CRM может собирать данные в полях, которые похожи друг на друга, что повышает вероятность неуместных или избыточных данных в вашей системе.
Например, вы можете собрать несколько разных типов телефонных номеров для контакта:
- Номер телефона
- Номер мобильного телефона
- Номер телефона компании
- Факс
Случаются ошибки, и вы можете обнаружить, что номер мобильного телефона контакта введен в дублирующую запись номера телефона компании. Такие повторяющиеся записи будет трудно обнаружить, если вы не проанализируете повторяющиеся данные в нескольких похожих полях.
Такие повторяющиеся записи будет трудно обнаружить, если вы не проанализируете повторяющиеся данные в нескольких похожих полях.
11. Частичные совпадения
Это проблема с дублированием данных, которую очень сложно обнаружить с помощью функций Excel и функции ВПР.
Рассмотрим пример. Допустим, у вас в CRM есть контакт из крупной организации, например университета. Контакты в разных отделах должны обрабатываться по-разному, потому что решения принимаются независимо в каждом отделе.
Вы можете использовать частичное совпадение для выявления дубликатов, которые имеют сходство друг с другом. Например, вы можете использовать частичное совпадение, чтобы обнаружить повторяющуюся запись для потенциального клиента, работодатель которого указан несколькими способами:
- Вашингтонский университет
- Школа бизнеса Вашингтонского университета
- Школа бизнеса Вашингтонского университета
Когда вы взаимодействуете с этим человеком, вы хотите убедиться, что вы взаимодействуете с ним с полным пониманием того, кто он и как с ним связаться. Это может повлиять на их рейтинг потенциальных клиентов и приоритеты потенциальных клиентов, предоставить критический контекст для отделов продаж и определить маркетинговые кампании, которые они получат.
Это может повлиять на их рейтинг потенциальных клиентов и приоритеты потенциальных клиентов, предоставить критический контекст для отделов продаж и определить маркетинговые кампании, которые они получат.
Insycle — Расширенное обнаружение дубликатов
Insycle предлагает расширенное обнаружение дубликатов и интеллектуальное слияние для популярных CRM, таких как HubSpot, Salesforce, Intercom и Pipedrive.
Используя Insycle, вы можете использовать наши готовые шаблоны для выявления дубликатов, используя различные комбинации полей, включая:
- То же имя
- То же имя, тот же домен
- То же название, похожая компания
- Та же фамилия и домен
- То же имя, тот же телефон
- И многие другие, включая ваши собственные свойства
На самом деле Insycle Customer Data Health Assessment проверяет ваши данные на наличие распространенных ошибок данных при регистрации и автоматически отслеживает несколько различных типов дубликатов.
Insycle позволяет операционным группам массово устранять проблемы с качеством данных CRM и автоматизировать процессы обслуживания данных. Без Insycle стоимость неверных данных является основным слепым пятном для руководителей отдела маркетинга и продаж и препятствием для выполнения их командами.
Insycle включает в себя десятки готовых шаблонов для выявления повторяющихся контактов, компаний и сделок в популярных платформах CRM.
Insycle также включает шаблоны для «похожих» или «нечетких совпадений», разработанные для того, чтобы помочь вам выявить больше потенциально дублирующихся записей в вашей базе данных. Многие записи о клиентах действительно являются дубликатами, но их никогда не идентифицируют с помощью стандартных алгоритмов сопоставления.
Большинство процессов дедупликации требуют стандартизации данных перед началом. Это упрощает выявление потенциальных дубликатов с помощью функций, которые обычно ищут дубликаты с точным соответствием.
Однако Insycle может обнаруживать дубликаты, которые в противном случае были бы пропущены. Например, когда мы обсуждали «общие термины, выраженные по-разному», мы привели следующий пример:
- Microsoft Inc.
- Корпорация Майкрософт
Эти значения представляют одну и ту же компанию, но не будут обнаружены процессами дедупликации с точным соответствием.
Insycle может идентифицировать и сопоставлять дубликаты, игнорируя общие термины в значениях. В этом случае общим термином будет «Inc.» и «Incorporated», а Insycle может соответствовать «Microsoft Inc.» и «Microsoft Incorporated», несмотря на несоответствия в соглашении об именах компаний.
Эта функция также не ограничивается названиями компаний. То же самое можно сделать и с телефонными номерами, где Insycle может сравнивать цифры в поле, игнорируя пробелы, символы и форматирование.
Стандартизация данных очень важна. Это критически важно для управления данными и улучшения качества обслуживания клиентов.