


что изменилось и как с этим жить :: Autonews
С 1 апреля 2020 года Российский союз автостраховщиков (РСА) пересчитал для всех водителей коэффициент «бонус-малус» (КБМ), от которого напрямую зависит стоимость полиса ОСАГО. Впервые с момента введения новой системы расчета КБМ определятся за календарный год, а не за год действия полиса, как было ранее, при этом для многих водителей полисы стали дешевле.
Что такое КБМ и зачем вообще его менять
Бонус-малус — это система тарифных коэффициентов, которые применяются для расчета страховой премии в зависимости от аварийной истории водителя. Коэффициент зависит от того, сколько ДТП совершил водитель по своей вине в течение года, и варьируется от 0,5 до 2,45. Те, кто в течение нескольких лет не попадал в аварии, имеют минимальную стоимость страховки, а самым беспечным водителям полис ОСАГО обойдется почти в пять раз дороже.
Еще два года назад Центробанк собирался кардинально поменять принцип расчета коэффициента бонус-малус, но потом было принято более мягкое решение: рассчитывать КБМ на каждый календарный год, а не на период действия полиса, и привязывать его значение к водителю, а не к автомобилю. Это позволило исправить целый ряд недостатков старой системы.
Во-первых, у одного водителя в базе данных РСА могло быть несколько КБМ, если он был вписан в разные полисы ОСАГО на несколько машин. Во-вторых, если водитель совершал аварию на автомобиле с полисом без ограничения допущенных к управлению лиц, то такое ДТП никак не влияло на его личный коэффициент. Наконец, при смене автомобиля водитель полностью терял скидку за безаварийность, если прежде ездил по полису без ограничений.
Еще одной проблемой являлся срок давности — накопленный КБМ сгорал, если водитель в течение года не заключал новый договор ОСАГО. Это, с одной стороны, давало возможность аварийным водителям обнулять свой коэффициент, а с другой — лишало законной скидки тех, кто не садился за руль больше года.
Как это работает сейчас
Новая система позволяет избежать задвоения КБМ и путаницы при оформлении полиса, если у водителя были какие-либо ДТП. Сейчас один и тот же коэффициент действует в течение года независимо от происходящих аварий. «Больше всего жалоб страховщики получали именно на неправильный расчет КБМ. У человека могло быть несколько коэффициентов, потому что он мог быть вписан в несколько полисов. В итоге его КБМ мог меняться в течение года», — объяснил автоэксперт и главный редактор радио «Автодор» Игорь Моржаретто.
Фото: Момотюк Сергей / Фотобанк Лори
Фактически новая система расчета коэффициентов вступила в силу еще с 1 апреля 2019 года, причем водители, у которых числилось несколько КБМ, получили своего рода амнистию — им присвоили единое наименьшее значение КБМ, то есть разом уменьшили стоимость полиса.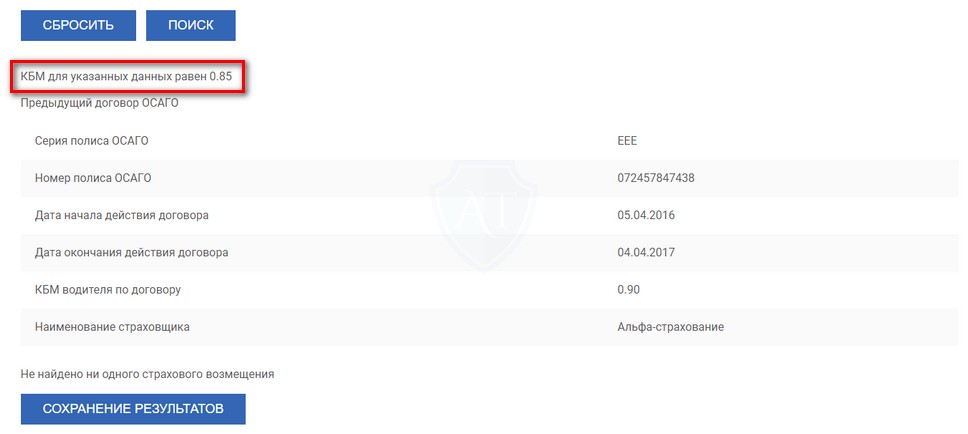 Календарный год потребовался на накопление статистики по каждому водителю, и сейчас все они впервые получили новые актуальные коэффициенты, объясняет директор департамента обязательных видов страхования «АльфаСтрахование» Денис Макаров.
Календарный год потребовался на накопление статистики по каждому водителю, и сейчас все они впервые получили новые актуальные коэффициенты, объясняет директор департамента обязательных видов страхования «АльфаСтрахование» Денис Макаров.
По его словам, главная новация заключается в том, что теперь обновление значения КБМ происходит только один раз в год — 1 апреля. При расчете коэффициента учитывается информация об аварийности водителя за период с 1 апреля по 31 марта предыдущего года. То есть, например, авария, произошедшая после 1 апреля 2020 года, будет учтена в значении КБМ только в 2021 году.
Автосервисы Autonews
Искать больше не нужно. Гарантируем качество услуг.Всегда рядом.
Выбрать сервисКроме того, новая система КБМ закрепляет страховую историю за водителем, которая не обнуляется даже в случае перерыва в вождении: все накопленные скидки или повышающие коэффициенты будут сохраняться, добавил Денис Макаров: «В результате этой новации система определения КБМ стала еще более справедливой и прозрачной для автовладельцев. Кроме того, такой подход позволяет исключить случаи задвоения КБМ, а также снизить риск возможных ошибок или злоупотреблений при его применении».
Кроме того, такой подход позволяет исключить случаи задвоения КБМ, а также снизить риск возможных ошибок или злоупотреблений при его применении».
Как изменилась стоимость полиса
По данным РСА, после пересчета и чистки двойных коэффициентов КБМ число водителей, получивших скидку на ОСАГО, выросло на 5% — до 89%, то есть абсолютное большинство водителей сейчас платят меньше стандартной цены полиса. «Модернизация расчетов осуществлена для удобства автовладельцев. Новая система уже показала свою эффективность — количество жалоб на страховщиков в ЦБ снизилось практически наполовину», — прокомментировал президент РСА Игорь Юргенс.
Страховщики согласны с тем, что в среднем стоимость полиса снизилась довольно заметно, причем помимо перерасчетов КБМ на нее повлияло и прошлогоднее изменение тарифного коридора базовых ставок на 20% вверх и вниз, что позволило страховщикам давать больше скидок. «Вместе с расширением тарифного коридора это изменение уже привело к снижению стоимости ОСАГО в 2019 г.
Фото: Norbert Michalke / Global Look Press
Как карантин повлияет на работу ОСАГО
На текущий момент все технологические процессы полностью отлажены, система работает в автоматическом режиме и не требует личного участия персонала, заверили в РСА. Опрошенные Autonews.ru страховщики подтвердили, что КБМ по каждому водителю рассчитывается автоматически электронной системой, к которой подключены все агенты.
Кроме того, РСА продолжает модернизацию базы данных в расчете на увеличение числа клиентов в будущем. Как заявил Игорь Юргенс, следующий этап доработок намечен на лето, когда будут введены новые протоколы контроля актуальности данных.
Что делать если рса не подтверждает данные. Пользователь не прошел проверку в РСА — причины и как их исправить? Оформление электронного полиса
Можно оформить страховку онлайн. Среди миллионной аудитории автолюбителей страховку онлайн уже купили несколько тысяч водителей. Однако очень часто пользователи сталкиваются с проблемой – система выдает ошибку «Не получено подтверждение от централизованных систем РСА». Автолюбители должны знать, почему происходит подобный сбой, и что делать, если автомобиль не прошел проверку в РСА.
Не проходит проверку РСА, откуда появляется ошибка
В страховом агентстве при покупке полиса ОСАГО страховщик «забивает» в базу данные по вашему автомобилю. Вся введенная информация достоверна (агент несет персональную ответственность за это) и хранится в единой базе АИС РСА.
Внимание! Продление договора ОСАГО возможно не ранее чем за 60 дней до завершения срока страхования, но не позже даты его окончания.
Сегодня можно купить полис ОСАГО онлайн. В этом случае водитель сам вводит всю требуемую информацию, а система делает сверку с базой данных (страховой агент внес ее во время покупки вами последнего страхового полиса).
Если агент допустил ошибку при введении данных (буква, запятая, неточно указан литраж и т.д.), то вы увидите на экране ошибку, которая не позволяет пройти проверку в РСА. Возможно, вы сами были невнимательны при заполнении анкеты – перепроверьте все еще раз.
Важно! Не путайте ошибку «проверки по базе РСА» и другие «непредвиденные ошибки». Если сайт после всех ваших исправлений в неверно заполненных полях окончательно сообщил о том, что автомобиль не проходит проверку в РСА, то проблема именно в ваших данных (электронная система не виновата) – придется посетить страховую компанию.
Не проходит проверку РСА – что при этом делать
Если ваш автомобиль не проходит проверку РСА, нужно знать о том, какие меры уместно предпринять при обнаружении ошибки в системе:
Если в системе есть фактическая ошибка, попробуйте ввести свои данные снова (при этом наберите ту же опечатку, что и в базе).
Внимание! Если вы хотите быть абсолютно уверенными в законности полиса с фактической ошибкой, то лучше всего после покупки полиса онлайн обратиться в страховой офис с просьбой исправить ваши данные в системе.
Если ваша страховка еще действительна, но вы уже обнаружили ошибку в электронной системе, навестите страховщиков и требуйте обновления информации по вашему ТС. Помните! У вас есть право присутствовать при внесении данных, таким образом, вы сами сможете проконтролировать весь процесс исправлений на сайте. Спустя несколько дней, когда база данных обновится, можно сделать повторную попытку пройти проверку в РСА.
Внимание! Внесение поправок по телефону не желательно (да и не все агенты на это идут).
Опечатка в заполнении формы
Одной из причин, почему машина не проходит проверку РСА, является наличие неточностей в тексте или цифрах. Самой распространенной причиной выдачи ошибки является наличие опечатки в заполнении формы. Просмотрите внимательно все заполненные поля. На сайтах многих страховых компаний сомнительные места подсвечивают желтым цветом или сразу перечисляют (в виде текста) найденные ошибки.
Просмотрите внимательно все заполненные поля. На сайтах многих страховых компаний сомнительные места подсвечивают желтым цветом или сразу перечисляют (в виде текста) найденные ошибки.
Если опечатка выявлена по вашей вине – можно ее исправить при повторной попытке введения данных, но если опечатку сделал страховой агент при внесении информации в единый реестр – придется посетить свою страховую фирму и попросить об исправлении данных в базе.
Неверный стаж
Не проходит регистрация
Не состоялась регистрация – вот вам и ответ, почему вы не можете пройти проверку в РСА. Если не удается зарегистрироваться, то, возможно, вы неправильно ввели логин или пароль. Вернитесь на «вход» и повторно внимательно вводите логин и пароль для входа в личный кабинет. Если опять неудача – воспользуйтесь формой «восстановить пароль».
Если опять неудача – воспользуйтесь формой «восстановить пароль».
Раз происходит подобная ошибка, значит, вам придется посетить страховую компанию – на сайте должны исправить ошибки (у вас доступа в систему с правом исправления ошибок/опечаток нет). Подобную ошибку система выдает в случае первичной покупки ОСАГО (ведь на текущий момент ваши данные в электронной базе отсутствуют). Вам нужно обратиться в офис для оформления бланка ОСАГО,
Не проходят марка и модель автомобиля
Возможно, марка и модель вашего авто не соответствуют информации в базе данных. Вам следует сверить данные с прошлогодним полисом (пункт 2) или паспортом транспортного средства и СОР (это свидетельство о регистрации вы всегда возите с собой).
Внимание! Если электронная система запрашивает один номер (а вы не понимаете, какой именно), то вписывать в форму онлайн нужно тот номер ПТС (или номер СОР), который вам вписали в прошлогодний полис.
Свидетельство регистрации ТС и номер ПТС, вводим наоборот
Одной из причин, почему не проходит проверка в РСА, может быть то, что вы неправильно ввели номер СОР и ПТС. Посмотрите внимательно на заполняемые графы – может быть, их просто нужно поменять местами (ввести наоборот: сначала номер СОР, а потом ПТС).
Посмотрите внимательно на заполняемые графы – может быть, их просто нужно поменять местами (ввести наоборот: сначала номер СОР, а потом ПТС).
С 2013 года Союзом автостраховщиков РФ (РСА) введена в работу база данных, используемая при проверке коэффициента «бонус-малус» (КБМ). Указанный параметр в обязательном порядке должен использоваться страховыми компаниями при расчете тарифа по страхованию (ОСАГО).
Учитывая собственную страховую историю, водители могут рассчитывать на понижение тарифа за счет бонусов (5% за каждый год) за безаварийное вождение в предыдущий страхованию год. Если в ходе последних двух лет имело место ДТП по вине клиента, то размер тарифа увеличивается (малус).
В чем преимущества метода?
Для клиента выгода от единой базы данных состоит в том, что стоимость полиса должна ему объявляться сотрудником СК только после выполнения запроса в базу РСА и выявления права на получение скидки по стоимости. Ранее расчет часто производился по базовому тарифу без учета имеющегося бонуса.
Для страховой компании положительным моментом является возможность получения реальной картины по водительской истории клиента. Ранее водитель, узнав о повышении тарифа из-за ДТП, переходил на обслуживание в другую СК, которая была не в курсе о происшествии, и страховался по обычной стоимости. Теперь в любой организации будет видна его история, поэтому тариф будет везде одинаковый, то есть повышенный из-за нарушений ПДД и ДТП.
Почему нет сведений в базе?
Персональные данные в единой страховой базе могут отсутствовать по нескольким причинам:
- когда страховая компания по разным причинам не передала информацию об истории вождения клиента;
- когда переданы не правильные данные в РСА, а с ошибками, поэтому они не привязаны в базе к конкретному водителю;
- когда произошел технический сбой в работе программы и какие-то участки с данными оказались поврежденными;
- когда клиент произвел обмен водительского удостоверения, но информация в базе осталась привязанной к устаревшим данным;
- когда клиент только получил права и оформляет самый первый страховой договор.

Что делать при отсутствии информации в базе РСА?
Чтобы убедиться в том, что действительно нет данных в РСА о КБМ, следует направить письменный запрос в Союз автостраховщиков. Если не найдут подтверждения факты передачи сведений страховщиками за предыдущие периоды, водитель должен предпринять следующие действия:
- Подготовить старые страховые полисы ОСАГО. При их отсутствии обратиться в СК, где ранее оформлялись договора, и выяснить номера документов, период их действия и дату выдачи.
- По месту оформления предыдущего полиса получить справку для перехода в другую СК с указанием данных о страховом стаже клиента и страховых случаях (если таковые были).
- Полученную справку отнести в СК, где планируется оформление нового страхового соглашения.
Если договор уже оформлен, то на основании предоставленной справки стоимость полиса должна быть пересчитана, и возвращена часть оплаченной премии при наличии права на скидки (по КБМ).
Покупка электронного ОСАГО может оказаться под вопросом, если документы на транспорт не проходят проверку в базе Союза автостраховщиков. Причин проблемы может быть множество. Но важно отыскать и исправить ошибку, ведь страховку необходимо оформить вовремя, чтобы не потерять скидку, не стать нарушителем. О том, почему не проходит проверка РСА, читайте в статье.
Причин проблемы может быть множество. Но важно отыскать и исправить ошибку, ведь страховку необходимо оформить вовремя, чтобы не потерять скидку, не стать нарушителем. О том, почему не проходит проверка РСА, читайте в статье.
Причины для проведения проверки РСА
Для оформления ОСАГО надо вводить данные страхователя, допущенных к управлению водителей, транспортного средства. Точность важна потому, что информация содержится в единой электронной базе. И путаница нежелательна. Ведь полис покупают ежегодно. А его цена зависит от страховой истории водителя, то есть количества аварий за время действия предыдущего ОСАГО и более ранний период.
Страховку может проверить и сотрудник ГИБДД. В последнее время это делается по электронной базе РСА, так что водителю нет нужды возить с собой бумажный полис. Но если в систему внесена непроверенная информация, документ не найдут, и водителя заставят платить штраф. А при попадании автомобилиста в тех же обстоятельствах в ДТП материальная ответственность за последствия целиком ляжет на него.
Почему не проходит проверка РСА при получении полиса ОСАГО онлайн
Многие автомобилисты пользуются удобной возможностью приобрести электронный полис автострахования. Но после оплаты и получения документа может обнаружиться, что он не отражается в личном кабинете и отсутствует в базе. Фактически ОСАГО не проходит проверку в РСА. Что служит причиной:
- данные еще не отображены в системе, так как прошло мало времени с момента оформления документа;
- в базе есть технические проблемы.
К
оличество услуг, которые можно оформить онлайн, увеличивается с каждым годом в геометрической прогрессии. Не так давно, у владельцев автомобилей появилась возможность оформить полис обязательного страхования, не выходя из собственной квартиры. Хотя, как и везде, при онлайн оформлении могут возникнуть проблемы, например, ошибка при проверке по базе АИС РСА. В данной статье мы рассмотрим возможные сложности и способы их устранения при электронном оформлении полиса ОСАГО.
Причины проблемы
На самом деле, единственная проблема, которая может возникнуть при онлайн оформлении полиса – некорректное введение данных. Либо внесена неверная информацию, либо она внесена в неправильном формате.
Крупные страховые компании, при разработке электронного сервиса, учли пожелания клиентов. Поэтому поля с некорректно введенными данными подсвечиваются. Это существенно облегчает процесс ввода данных и поиска ошибки.
Другая возможная проблема – внесение некорректной информации. Обычно эта проблема возникает в случае, если данные переносятся не в точности как указано в ПТС, а по памяти или с других документов. Но бывают и случаи, когда сотрудник страховой компании при первичном оформлении полиса допустил ошибку. Независимо от того, когда возникла неточность – при оформлении полиса в первый раз или сейчас, Вы должны добиться идентичности данных. Если есть возможность, то можно просто переписать все данные с полиса, оформленного ранее.
Что делать?
Если Вы обнаружили ошибку, опечатку или неточность в оформлении полиса, у Вас есть несколько вариантов действий.
Во-первых, Вы можете оформить новый полис ОСАГО с той же ошибкой, что и в предыдущий раз. Достаточно внести все данные, как в прошлом документе. Однако, при возникновении страхового случая Вы рискуете. Страховые компании неохотно оплачивают компенсацию ущерба и неправильно оформленный полис может стать причиной для отказа. Даже если ошибку допустил страховой агент. Если ошибка незначительна, например, вместо седана Ваш автомобиль записан как универсал, то добиться выплаты страхового возмещения Вы можете через суд. Доказав, что ошибка в оформлении документов произошла по вине страховой компании и все остальные данные внесены корректно. Но, это потребует от Вас дополнительных временных затрат и усилий.
Во-вторых, Вы можете обратиться в службу поддержки страховой компании и попросить их об исправлении ошибки. Многие компании, заботясь о своей репутации и ориентируясь на помощь и поддержку клиентов, пойдут навстречу и попросят прислать необходимые скан-копии документов, подтверждающие данные. После чего самостоятельно исправят возникшую ранее ошибку. Затем Вы сможете оформить полис на сайте уже как положено, без ошибок.
После чего самостоятельно исправят возникшую ранее ошибку. Затем Вы сможете оформить полис на сайте уже как положено, без ошибок.
Также вы можете воспользоваться сервисами нашей компании:
На нашей платформе вы сможете оформить полис Е-ОСАГО самостоятельно в одной из 9 страховых компаний. Все что Вам нужно сделать — зарегистрироваться. И нажать кнопку создать полис. Оплата происходит напрямую в страховую компанию. После оформления вы получите кешбек — 5%.
Но возможна ситуация, когда представители страховой компании потребуют Вашего личного присутствия в офисе компании с оригиналами документов для внесения исправлений.
Однако и в этом случае, Вы можете временно оформить полис с ошибкой, ориентируясь на данные прошлогоднего документа. И поменять его, как только появится свободное время. Главное – не откладывать этот процесс в долгий ящик. Ведь при возникновении страхового случая, обоснованность Ваших претензий к страховой компании Вам придется доказывать в суде.
Оформление электронного полиса
Оформление ЕОСАГО может показаться достаточно сложным процессом. Если Вы не прошли проверку с первого раза – внимательно изучите форму заполнения, проверьте ее на возможные опечатки, сверьте все указанные данные с прошлым документом и попробуйте еще раз. В большинстве своем, ошибки возникают в результате невнимательного заполнения формы. Устранить такие ошибки не составляет труда. Оформление полиса без похода в отделение страховой компании и длительного ожидания в очереди вполне реально.
Если Вы не прошли проверку с первого раза – внимательно изучите форму заполнения, проверьте ее на возможные опечатки, сверьте все указанные данные с прошлым документом и попробуйте еще раз. В большинстве своем, ошибки возникают в результате невнимательного заполнения формы. Устранить такие ошибки не составляет труда. Оформление полиса без похода в отделение страховой компании и длительного ожидания в очереди вполне реально.
Как исправить Кбм ОСАГО в базе АИС РСА и восстановить скидку
В предыдущей статье «Как правильно определить Кбм» мы рассмотрели законодательные аспекты применения коэффициента бонус-малус и особенности работы базы АИС РСА. Но часто наши пользователи сталкиваются с ситуацией, когда база выдает ошибку или коэффициент, которые не соответствует реальному положению дел. Страхователь в течение многих лет оформлял полисы ОСАГО, убытков по его вине не происходило, а значение Кбм либо равно единице, либо не соответствует количеству лет безубыточного страхования.
Как же восстановить Кбм?
Почему значение Кбм может быть не верным и какие шаги необходимо сделать, чтобы восстановить справедливость?
Итак, рассмотрим причины возможных ошибок.
Замена водительского удостоверения
Первое, что нужно сделать, это проверить, не менялось ли водительское удостоверение за последние несколько лет. Так как данные о Кбм передаются на основании уже закончившихся полисов, в базе АИС РСА может быть запись о водителе со старыми правами. Если водительское удостоверение менялось, проверьте кбм, указав старые серию и номер прав. Серию и номер старых прав вы можете найти на обороте водительского удостоверения. Если ваша скидка по старым правам находится в базе, ее можно восстановить.
Ошибка при вводе данных
Как мы уже отмечали, страховая компания передает данные о водителях из своей базы данных, а вносят эту информацию в базу люди (операторы по вводу полисов). Тут может иметь место человеческий фактор – при вводе фамилии, имени, отчества или даты рождения водителя оператор мог допустить опечатку. Если хотя бы 1 буква или цифра в базе данных не совпадает с той информацией, которую вы вводите при обращении к АИС РСА, система вернет ошибку и ваша скидка пропадет.
Если хотя бы 1 буква или цифра в базе данных не совпадает с той информацией, которую вы вводите при обращении к АИС РСА, система вернет ошибку и ваша скидка пропадет.
Управление несколькими автомобилями
Водитель мог быть вписан в качестве лица, допущенного к управлению в несколько страховых полисов. При этом значение Кбм могло быть разным в каждом из этих полисов, так как до 01.01.2013 агент не обращался к единой базе для определения Кбм, а давал скидку на основании предыдущего полиса. Например: Иванов И. И. имеет собственный автомобиль, а также допущен к управлению автомобилем супруги, у которой стаж вождения равен 2 года. В своем полисе у него Кбм 0,5, в полисе супруги – 0,9 (так как страховая история супруги насчитывает всего 2 года, по количеству лет стажа). Если страховая компания передала данные по обоим полисам, значение Кбм для Иванова И. И. будет максимальным из двух, то есть 0,9.
Банкротство страховой компании
Страховая компания обанкротилась и не передала данные в систему АИС РСА. В этом случае в единой базе просто нет сведений о страховой истории водителя.
В этом случае в единой базе просто нет сведений о страховой истории водителя.
Недобросовестный агент или сотрудник страховой компании
По закону агент перед оформлением полиса должен в обязательном порядке проверить вашу скидку в базе РСА. Однако часто агент не делает этого, пользуясь неграмотностью клиента. Завышая Кбм, агент увеличивает стоимость полиса и тем самым зарабатывает больше. В этом случае в базу РСА передается кбм = 1, то есть так же, если бы страхователь оформлял полис впервые.
Что же делать, чтобы не потерять накопленную скидку за безубыточное страхование и восстановить утраченный Кбм?
До 1 июля 2014 страховщики могли использовать для определения значения Кбм «справку о безубыточности». П 35 правил ОСАГО гласит: «При досрочном прекращении или по окончании действия договора обязательного страхования страховщик предоставляет страхователю сведения о страховании по форме, установленной в соответствии с законодательством Российской Федерации. Сведения о страховании предоставляются страховщиком бесплатно в письменной форме в 5-дневный срок с даты соответствующего обращения страхователя и вносятся в автоматизированную систему страхования». Таким образом достаточно было обратиться в страховую компанию, где был оформлен последний полис ОСАГО, получить справку по форме № 4 и на ее основании оформить следующий полис ОСАГО. При очередной передаче данных о значении Кбм в систему АИС РСА Кбм обновлялся.
Таким образом достаточно было обратиться в страховую компанию, где был оформлен последний полис ОСАГО, получить справку по форме № 4 и на ее основании оформить следующий полис ОСАГО. При очередной передаче данных о значении Кбм в систему АИС РСА Кбм обновлялся.
С 1 июля 2014 года вступили в силу поправки в законодательство, которые не позволяют применять Кбм на основании справки о безубыточности, а именно:
Подпункт «з» пункта 3 статьи 29 Федерального закона от 1 июля 2011 г. N 170-ФЗ «О техническом осмотре транспортных средств и о внесении изменений в отдельные законодательные акты Российской Федерации» (с изменениями и дополнениями) вносит изменения в Федеральный закон «Об обязательном страховании гражданской ответственности владельцев транспортных средств»
з) дополнить пунктом 10.1 следующего содержания:
«10.1. Заключение договора обязательного страхования без внесения сведений о страховании в автоматизированную информационную систему обязательного страхования, созданную в соответствии со статьей 30 настоящего Федерального закона, и проверки соответствия представленных страхователем сведений содержащейся в автоматизированной информационной системе обязательного страхования и в единой автоматизированной информационной системе технического осмотра информации не допускается. «;
«;
Таким образом, при оформлении полиса ОСАГО Страховщик в обязательном порядке должен проверить ваш Кбм по базе АИС РСА, а также проверить наличие действующего талона техосмотра в единой информационной системе ЕАИСТО. Без этого оформление полиса ОСАГО не допускается.
Как восстановить кбм? Можно пойти 2 путями:
Вариант 1.
- Определите, в какой момент времени пропал ваш кбм. Для этого нужно сделать проверки Кбм на разные даты, и найти, какая страховая компания оформила ваш полис с неправильной скидкой.
- Найдите и отсканируйте копии полисов с правильным значением кбм
- Напишите жалобы в Центробанк, РСА, страховую компанию, в которой вы в настоящее время застрахованы. К жалобе приложите сканы полисов, на основании которых вы требуете пересчета скидки.
- В течение месяца вашу жалобу должны рассмотреть и в зависимости от комплекта документов, которые вы направите вместе с жалобой принимается решение о восстановлении Кбм.
Вариант 2
- Проверьте кбм.
 В результатах проверки вы увидите кнопку «Не устраивает кбм? Восстановим». Наши специалисты сделают всю работу за вас, и в течение 1-5 дней ваш кбм будет восстановлен и вы сможете оформить полис ОСАГО с положенной скидкой или запросить возврат излишне уплаченной страховой премии в вашей страховой компании.
В результатах проверки вы увидите кнопку «Не устраивает кбм? Восстановим». Наши специалисты сделают всю работу за вас, и в течение 1-5 дней ваш кбм будет восстановлен и вы сможете оформить полис ОСАГО с положенной скидкой или запросить возврат излишне уплаченной страховой премии в вашей страховой компании.
наличие ОСАГО стали проверять видеокамеры
В Москве начали проверять наличие полисов ОСАГО при помощи камер. В российской столице от двух до четырех миллионов машин используются без обязательной страховки. Это данные Российского союза автостраховщиков. Специальное оборудование только тестируют. Поэтому пока водителям, у которых полиса нет или он оформлен не корректно, будут приходить только рекомендательные письма и предупреждения.
Принцип работы – сканирование номеров через камеры – старый. Письма счастья – новые. Теперь и за отсутствие действующей страховки. Пока они будут приходить только московским автомобилистам. Столичный регион стал первым пилотным субъектом, где тестируется система автоматической проверки наличия полиса ОСАГО с помощью дорожных камер. Вместо штрафов пока будут рассылаться уведомления.
«И мы, и ГИБДД, и правительство Москвы считаем, что надо дать несколько месяцев тем людям, кто не купил полис, протестировать еще систему, чтобы те, кто неправильно заполнил, не был наказан, все это определило продолжительность работы», — пояснил президент Российского союза автостраховщиков (РСА) Игорь Юргенс.
Инициатива введения такой системы сканирования возникла больше двух лет назад. Но к пилотной стадии пришли только летом 2019 года. Главная сложность была в отсутствии единой системы работы с данными. Камеры устанавливает ЦОДД, ГИБДД выписывает штрафы и собирает информацию о транспортных средствах, а информацией о всех застрахованных автомобилистах владеет Союз автостраховщиков.
«Трудности заключались в том, что в нашей системе одни данные, в их системе другие данные хранятся. В силу закона об ОСАГО можно было страховаться даже если номерного знака нет. Поэтому в нашей базе нет всех номеров. Поэтому необходимость была в создании общей системы, которая добавляла бы отсутствующие реквизиты. Техническая сверка», — отмечает исполнительный директор РСА Евгений Уфимцев.
За несколько месяцев работы в тестовом режиме система обнаружила почти 700 тысяч машин без ОСАГО. Среди автолюбителей уже сложилось мнение — мера может в разы дисциплинировать тех водителей, которые привыкли экономить на страховке, подвергая угрозе жизни других участников движения.
«В дальнейшем, если будет постоянно получать такие письма счастья тот, кто избегает страхования, вероятнее всего, он застрахуется, — предполагает председатель Всероссийского общества автомобилистов Валерий Солдунов. — Ведь страховка — это не только про автомобиль, но и про человеческую жизнь».
Новая система распознавания наличия полисов поможет вычислять и поддельные страховые документы. Рекомендации, а впоследствии штрафы получат те, кто заключил договор о страховании в интернете у лжестраховщиков сами того не зная. После запуска пилотного проекта система заработает в Северной столице и Казани.
как исправить, чем грозит, из-за чего может возникать
При оформлении полиса ОСАГО важно следить за тем, чтобы в нем не было ошибок. Даже малейшие неточности могут привести к тому, что документ могут признать недействительным или поддельным. Если вы обнаружили ошибки в вашем полисе, то их будет необходимо как можно скорее исправить. Подробнее о том, как это сделать, вы узнаете далее.
Распространенные ошибки
Чаще всего ошибки возникают при заполнении следующих данных:
- ФИО собственника, страхователя и водителей
- Паспортных данных страхователя
- Марки автомобиля
- VIN и госномера автомобиля
- Реквизитов страховой компании
- Номеров и серий водительских удостоверений
- Применяемых при расчете коэффициентов
Вся информация, указанная в полисе, проверяется в РСА. Если водитель и автомобиль уже есть в базе, то она посылает уведомление страховщику и требует исправления. Если страховка оформляется впервые, то информация записывается в базу, как и обычно, после чего ошибки могут быть обнаружены только при наступлении страхового случая. Данные в РСА всегда имеют приоритет перед указанными в полисе.
Кроме того, ошибкой могут признать:
- Заполнение полиса пастой разных цветов или оттенков
- Отличия в почерке, которым заполнен полис
- Отличия подписей от указанных в паспортах страхователя и работника СК
- Наличие устаревших или неправильных реквизитов в полисе
Причины появления
Ошибки в полисе ОСАГО могут возникнуть по трем причинам:
- Невнимательность страховщика или страхователя. Ошибки могут возникнуть в момент заполнения полиса или передачи данных в РСА
- Устаревание указанных данных. Ошибкой считается неактуальная информация в полисе — например, при замене паспорта или водительского удостоверения
- Умысел одной из сторон. Страхователь может намеренно указывать недостоверные данные, чтобы уменьшить стоимость полиса, или оформлять документ на подставное лицо. Умышленные ошибки могут быть и со стороны страховщика — например, он может намеренно передать неправильные данные в РСА при оформлении полиса через интернет
Какие могут возникнуть проблемы из-за ошибок в полисе
Если в полисе будут содержаться ошибки, то он может быть в любой момент признан недействительным. Это может привести к различным последствиям — как незначительным, так и тяжелым:
- Сотрудник ГИБДД может выписать штраф как за отсутствие полиса, если обнаружит расхождение информации в документе или в РСА
- При возникновении ДТП и признания водителя виновным страховая компания может потребовать возместить выплаченную сумму убытка с водителя в суде. Либо же она откажется возмещать ущерб по полису с ошибками вообще
- В крайнем случае страховой полис могут посчитать поддельным, а вас — обвинить в попытке мошенничества. Вам придется доказывать, что вы не указывали недостоверные данные умышленно
Что делать при обнаружении
Если после оформления полиса вы обнаружили ошибки, то вам следует как можно скорее обратиться в страховую компанию. Вносить правки в полис самостоятельно нельзя, иначе документ будет признан недействительным. В страховой компании сообщите о проблеме и заполните заявление об исправлении ошибок.
Для исправления вам потребуется оригинал полиса, паспорт страхователя и документы, подтверждающие правильные данные. Например, если был неправильно указан VIN автомобиля, то вам потребуются его ПТС и СТС. При внесении новых данных внимательно проверьте полис на наличие ошибок перед тем, как его забирать. Правки вносятся в действующий полис, либо заполняется новый бланк с актуальными сведениями.
Новую информацию в РСА страховщик отправит сам — отдельно обращаться туда не нужно. При этом следует быть внимательным при замене номера и серии водительских прав — при их изменении вы рискуете потерять начисленный КБМ. Чтобы его сохранить, дополнительно заполните в страховой компании заявление о сохранении коэффициента.
Как исправить ошибку в электронном полисе ОСАГО
Считается, что электронная база данных не позволит зарегистрировать документ с неправильно заполненными полями. На практике часты случаи, когда страхователь ошибается, программа не распознает ошибку и оформляет ОСАГО с неправильными сведениями. Не все страховые компании обеспечивают проверку вводимых данных по базе РСА.
Исправить ошибку в электронном полисе проще, чем в бумажном. Обычно для этого достаточно войти в личный кабинет на сайте страховщика, выбрать нужный полис и опцию редактирования. Укажите данные, которые необходимо исправить, и введите актуальные сведения. Загрузите скан-копии подтверждающих информацию документов. После проверки и внесения правок страховая компания вышлет исправленный документ на электронную почту.
Сколько стоит исправление полиса ОСАГО
Согласно закону, внесение любых правок в полис ОСАГО полностью бесплатно. Страховая компания не имеет права брать каких-либо комиссий за исправление документа.
Единственное исключение — если после внесения изменений изменяется стоимость полиса. В этом случае вам нужно будет выплатить страховщику разницу между стоимостью полиса до и после правок.
Какие ошибки могут быть признаны мошенничеством
Мошенничеством признаются любые ошибки, которые так или иначе влияют на стоимость полиса:
- Неправильно указанная мощность автомобиля
- Неправильно указанные стаж и КБМ
- Указание регистрации в регионе с низким территориальным коэффициентом
При обнаружении таких ошибок страхователю может грозить наказание по статье 159 Уголовного кодекса.
Вопрос-ответ
Когда вступают в силу исправления в полисе?
Исправления в полисе становятся действительными в день внесения правок. В РСА новые сведения вносятся в течение трех-пяти дней.
Что делать, если страховая компания не принимает заявление на изменение данных?
Если страховщик не хочет исправлять ошибки в полисе, то вам придется обратиться в суд. К доказательствам приложите документы, подтверждающие реальные данные страхователя и водителей.
Можно ли рассчитывать на страховую выплату при опечатках в полисе?
Наличие опечаток в документе не является основанием для отказа в полисе. При этом важно, чтобы в протоколе ГИБДД все сведения были указаны корректно. Полис все еще требуется исправить — это можно сделать в момент оформления страховой выплаты.
Источники
Индивидуальные тарифы ОСАГО. Что меняется для водителей
Некоторые коэффициенты ЦБ также изменил вместе с тарифами.
Для расчета коэффициента территории (КТ) используется адрес регистрации водителя, указанный в его паспорте, свидетельстве о регистрации или паспорте транспортного средства. Если вы переезжаете, то должны поменять и адрес регистрации машины.
Величина коэффициента связана со статистикой выплат в конкретном регионе. Чем больше на дороге машин, тем выше риск попасть в аварию. А значит, и КТ будет больше. Так, например, в Москве этот коэффициент равен 1,9, а в карельских селах — только 0,82.
Если в полисе указаны все, кто будет управлять машиной, то коэффициент ограничения (КО) равен 1. Можно не вписывать конкретных водителей, тогда автомобилем сможет пользоваться любой человек, у которого есть действующие права соответствующей категории. Но и КО в этом случае будет больше — 1,94, а полис выйдет дороже.
Коэффициент бонус-малус (КБМ) отражает аккуратность водителя за рулем. Если за год по вашей вине не случилось ни одной аварии, то КБМ снизится от текущего значения и полис станет дешевле. Если ваши действия привели к трем и больше ДТП, то почти во всех случаях КБМ будет максимальным — 2,45. Новички, только сдавшие на права и купившие первый полис, получают коэффициент, равный 1. То есть у них нет ни скидки за безаварийное вождение, ни надбавки за ДТП. При этом сейчас КБМ обновляется только раз в год — 1 апреля. То есть если, например, в 2020 году авария произошла после 1 апреля, то она будет учтена в КБМ уже в 2021 году.
А если вы захотите вписать в полис несколько водителей, то использоваться при расчетах будет максимальный КБМ. Если ограничений нет, то для физических лиц берется КБМ, равный 1. Свой КБМ можно узнать на сайте Российского союза автостраховщиков. Там же в специальном калькуляторе можно рассчитать и примерную стоимость полиса.
Чем старше водитель и чем дольше он водит, тем меньше для него коэффициент возраста и стажа (КВС). С 2019 года всех водителей разделили на 58 категорий, у каждой из которых свой КВС. Так, для водителей в возрасте 16–21 года без стажа коэффициент составляет 1,93, со стажем до двух лет — 1,9, а для автомобилистов в возрасте от 59 лет со стажем от пяти лет он значительно меньше — 0,91.
Стаж считается с момента оформления прав. Так что даже если вы не водите автомобиль, но права у вас есть, стаж все равно начисляется. Когда в полис вписывают нескольких водителей с разными КВС, во внимание принимается самый большой показатель.
Коэффициент мощности (КМ) применяется только для легковых автомобилей. Чем выше мощность двигателя, тем выше коэффициент.
Еще использовать машину можно не весь год, а только, например, для поездок летом на дачу. Это отражает коэффициент сезонности (КС). Чем короче период, тем меньше коэффициент и дешевле страховка. Например, за трехмесячное использование машины КС составит 0,5. А вот при оформлении полиса на 10–11 месяцев скидки уже не будет — КС равен 1, как за весь год. По этой же схеме рассчитывается и коэффициент в зависимости от срока страхования (КП), который применяется только для автомобилей, зарегистрированных за рубежом.
Ранее также имело значение, не нарушал ли автомобилист закон об ОСАГО — в этом случае применялся дополнительный коэффициент (КН), равный 1,5. Но больше отдельно его не будут брать в расчет.
Штрафов от камер видеофиксации пока не будет, если у вас нет полиса ОСАГО
РСА совместно с МВД РФ не смогли интегрировать свои электронные базы, для бесперебойной работы . Начало запуска было назначено на 1 февраля 2019 года. Тем не менее, на данный момент задача не выполнена.
Как считает один из руководителей РСА Евгений Уфимцев, проблему создают несознательные водители. После покупки машины, они получают полис ОСАГО перед тем, как зарегистрировать свой автомобиль в ГИБДД. Но после получения регистрационных знаков, не торопятся предоставить номер страховой компании. Отсюда, кажется машина застрахована, но по регистрационному номеру это не определить, потому что в информационной базе РСА его нет.
Надо сказать, что серверы, получающие информацию от видеокамер, будут работать на максимальном пределе. Но есть камеры в Москве под которыми проезжают несколько миллионов машин в сутки. Помимо нарушений ПДД придется проверять информацию о наличии страховки, что значительно увеличит нагрузку на серверы.
Поэтому будет вводиться другая схема. Раз в неделю страховые компании обновят базу данных о застрахованных автомобилях. Если транспортное средство есть в базе, камеры не запрашивают базу данных ОСАГО. Если его нет, то такой запрос направляется. При этом проверяется машина не ранее чем через 10 дней, потому что именно столько времени после приобретения автомобиля можно ездить без полиса ОСАГО.
Но, в МВД потребовали от РСА, чтобы серверы проверяли так же и идентификационный номер автомобиля. А тут возникли сложности. Из-за того что страховые агенты заносят информацию вручную, могут возникнуть ошибки. Где-то цифру пропустили, где-то вместо латинского шрифта использовали русский. Отсюда несовпадения баз данных.
Но в настоящее время все нужные работы по наладке взаимодействия этих систем проводятся. Впрочем, когда на практике заработает хотя бы один комплекс по выявлению не застрахованных автомобилей, никто сказать не берется.
Источник: Российская газета.
{\ text {T}} \ textbf {X}, ~~~~~~~~~~~~~~~~ C_ {jl} = \ overline {X _ {. j} Y _ {. l}} $, а затем разверните основные коэффициенты методом наименьших квадратов (как упоминает @ user969113). Вот пример.
Однако у этого метода есть несколько проблем, связанных с тем, что ковариационная матрица больше не является полуположительно определенной, а собственные / сингулярные значения имеют тенденцию к завышению. Хороший обзор этих проблем можно найти в Beckers and Rixen (2003), где они также предлагают метод оптимальной интерполяции недостающих пропусков — DINEOF (Data Interpolating Empirical Orthogonal Functions).Я недавно написал функцию, которая выполняет DINEOF, и мне действительно кажется, что это намного лучший способ. Вы можете выполнить DINEOF непосредственно для своего набора данных $ \ textbf {X} $, а затем использовать интерполированный набор данных в качестве входных данных в prcomp .
Обновление
Другой вариант проведения PCA для набора данных с пробелами — «Рекурсивно вычитаемые эмпирические ортогональные функции» (Taylor et al. 2013). Он также устраняет некоторые проблемы метода наименьших квадратов и в вычислительном отношении намного быстрее, чем DINEOF.В этом посте сравниваются все три подхода с точки зрения точности восстановления данных с помощью ПК.
Список литературы
Бекерс, Жан-Мари и М. Риксен. «Расчеты EOF и заполнение данных из неполных наборов океанографических данных». Журнал атмосферных и океанических технологий 20.12 (2003): 1839-1856.
Тейлор М., Лош М., Венцель М. и Шретер Дж. (2013). О чувствительности реконструкции и прогнозирования поля с использованием эмпирических ортогональных функций, полученных на основе данных с ошибками.{(t)} \ right) f \ left (\ mathbf {u} _ {i} \ right). \ end {align} $$
(14)
Реализация ARMS доступна в пакете R HI [35]. Пример \ (\ varvec {\ xi} _ {i1}, \ ldots, \ varvec {\ xi} _ {iK} \) для \ (i = 1, \ ldots, n \) получается на каждой итерации ЭМ t , где вектор \ ((s_ {i} + q) \ times 1 \) \ (\ varvec {\ xi} _ {ik} = \ left (\ tilde {\ mathbf {z}} _ {ik}, \ tilde {\ mathbf {u}} _ {ik} \ right) \), \ ( k = 1, \ ldots, K \), содержит «вмененные» значения для \ (\ mathbf {z} _ {i} \) и \ (\ mathbf {u} _ {i} \) (при том понимании, что \ (\ varvec {\ xi} _ {ik} = \ tilde {\ mathbf {u}} _ {ik} \), если \ (s_ {i} = 0 \)). {K} \ hat {\ mathbf {u}} _ {ik} \) по пространству индивидов как оценки \ (\ delta _ {1}, \ ldots, \ delta _ {q} \).Величина \ ((p-q) \ cdot \ hat {\ varvec {\ psi}} \) обеспечивает часть общей изменчивости, связанную с «отброшенными» компонентами.Новые предложения и сравнительное исследование
25
[5] B. Walczak, D.L. Massart, Работа с недостающими данными Часть I, Хемометрика и
Интеллектуальные лабораторные системы 58 (2001) 15-27.
[6] Ф. Артеага, А. Феррер, Работа с недостающими данными в MSPC: несколько методов,
различных интерпретаций, некоторые примеры, Journal of Chemometrics 16 (2002) 408-418.
[7] Ф. Артеага, А. Феррер, Структура для основанного на регрессии вменения недостающих данных
методов в онлайн-MSPC, Journal of Chemometrics 19 (2005) 439-447.
[8] S. Wold, C. Albano, W.J. Dunn, K. Esbensen, S. Hellberg, E. Johansson, M.
Sjöström. В Х. Мартенсе и Х. Руссвурме младшем (редакторы), Food Research and Data
Analysis, Applied Science Publishers, Лондон, 1983, стр. 183-185.
[9] P.R.C. Нельсон: Обработка недостающих измерений в моделях PCA и PLS.
к.э.н. Диссертация. Кафедра химического машиностроения Университета Макмастера.
Гамильтон, Онтарио, Канада, 2002.
[10] А.П. Демпстер, Н.М. Лэрд, Д. Рубин, Максимальная вероятность неполных данных
с помощью алгоритма EM (с обсуждением), Журнал Королевского статистического общества
Series B 39 (1977) 1-38.
[11] Дж. Л. Шафер, Анализ неполных многомерных данных, CRC Press, Нью-Йорк,
1997.
[12] P.D. Allison, Missing Data, Sage, Thousand Oaks, 2001.
[13] M.A. Tanner, W.H. Вонг, Расчет апостериорного распределения по увеличению данных
(с обсуждением), Журнал Американской статистической ассоциации 82
(1987) 528-550.
[14] Р. Лопес-Негрете де ла Фуэнте, С. Гарсия-Муньос, Л.Т. Биглер, Эффективная стратегия нелинейного программирования
для моделей PCA с неполными наборами данных, Журнал
Chemometrics 24 (2010) 301–311.
[15] Y. Liu, S.D. Браун, Сравнение пяти итерационных методов вменения для многомерной классификации
, Хемометрика и интеллектуальные лабораторные системы 120 (2013)
106-115.
[16] W.J. Krzanowski, Вменение отсутствующих значений в многомерных данных с использованием матрицы разложения по сингулярным значениям
, Biometrical Letters 25 (1988) 31-39.
[17] R.E. Уважаемый! Метод основных компонентов с отсутствующими данными для моделей множественной регрессии
, перепечатка, System Development Corp., Санта-Моника, Калифорния, 1959.
(PDF) Отсутствующие данные в анализе главных компонентов данных вопросника: сравнение методов
2314 J.R. Van Ginkel et al.
В целом, различия между методами пропущенных данных были настолько малы или бессистемны, что
можно было сделать вывод, что на практике не будет иметь большого значения, какой метод используется
в данных вопросника со степенью отсутствия, использованной здесь и считается обычным на практике.
До тех пор, пока из PCA полностью не удалены наблюдения (как в LD), результаты не будут сильно затронуты
используемым методом пропущенных данных.Конечно, большие различия могут быть обнаружены в более экстремальных (но, на наш взгляд, менее вероятных) условиях
. Таким образом, аргументы в пользу предпочтения одного метода
другому носят скорее практический, чем теоретический характер. Каждый метод имеет свои преимущества
и недостатки, поэтому пользователю решать, какие из этих преимуществ и недостатков
являются решающими с учетом имеющегося компьютерного программного обеспечения.
Литература
[1] Рубин ДБ. Вывод и недостающие данные.Биометрика. 1976; 63: 581–592.
[2] Little RJA, Рубин ДБ. Статистический анализ с недостающими данными. 2-е изд. Нью-Йорк: Уайли; 2002.
[3] Joliffe IT, Morgan BJT. Анализ главных компонентов и исследовательский факторный анализ. Stat Methods Med Res.
1992; 1: 69–95.
[4] Meulman JJ. Анализ однородности неполных данных. Лейден: DSWO Press; 1982.
[5] Такане Ю., Осима-Такане Ю. Взаимосвязь между двумя методами работы с отсутствующими данными в основном
компонентном анализе.Бихевиорометрика. 2003. 30: 145–154.
[6] Гифи А. Нелинейный многомерный анализ. Чичестер: Уайли; 1990.
[7] Грунг Б., Манн Р. Отсутствующие значения в анализе главных компонент. Хемометр Intell Lab. 1998. 42: 125–139.
[8] Kiers HAL. Аппроксимация методом взвешенных наименьших квадратов с использованием обычных алгоритмов наименьших квадратов. Психометрика. 1997; 62: 251–266.
[9] Josse J, Husson F, Pagès J. Gestion des données manquantes en Analyze en Composantes Principales. J Soc Fr Stat.
2009; 150: 28–51.
[10] Бернаардс CA, Сийтсма К. Влияние методов вменения и EM на факторный анализ, когда отсутствие ответа на вопросник
данных вопросника не может быть проигнорировано. Multivariate Behav Res. 2000; 35: 321–364.
[11] Демпстер А.П., Лэрд Н.М., Рубин Д.Б. Максимальная вероятность получения неполных данных с помощью алгоритма EM (с обсуждением
). J R Stat Soc Ser B. 1977; 39: 1–38.
[12] Schafer JL. Анализ неполных многомерных данных. Лондон: Чепмен и Холл; 1997.
[13] Рубин ДБ.Множественное вменение за неполучение ответов в опросах. Нью-Йорк: Уайли; 1987.
[14] Ван Гинкель JR, Kroonenberg PM. Использование обобщенного анализа прокруста для множественного вменения в компонентном анализе
. J Classif .; в прессе.
[15] Ван Гинкель Дж. Р., Кирс ХЭЛ. Построение доверительных интервалов начальной загрузки для загрузок главных компонентов при наличии пропущенных данных
: подход с множественным вменением. Br J Math Stat Psychol. 2011; 64: 498–515.
[16] Schafer JL.НОРМА: Версия 2.03 для Windows 95/98 / NT; 1998. Доступно по адресу: http://www.stat.psu.edu/∼jls/
misoftwa.html
[17] Yuan YC. Множественное вменение с использованием программного обеспечения SAS. J Stat Softw. 2011; 45: 1–25.
[18] SPSS Inc. IBM SPSS Statistics 19.0 для Windows. Чикаго, Иллинойс: SPSS Inc .; 2011.
[19] Gower JC. Обобщенный анализ прокрастов. Психометрика. 1975. 40: 33–51.
[20] Ten Berge JMF. Вращение ортогональных прокрастов для двух и более матриц. Психометрика.1977; 42: 267–275.
[21] Ван Гинкель Младший. Исследование множественного вменения в некачественных данных анкеты. Multivariate Behav Res.
2010; 45: 574–598.
[22] Bernaards CA, Belin TR, Schafer JL. Устойчивость многомерного нормального приближения для вменения неполных двоичных данных
. Stat Med. 2007. 26: 1368–1382.
[23] Ван Гинкель Дж. Р., Ван дер Арк Л. А., Сийтсма К. Множественное вменение данных тестов и анкет и влияние на
психометрических результатов.Multivariate Behav Res. 2007. 42: 387–414.
[24] Graham JW, Schafer JL. О выполнении множественного вменения для многомерных данных с малым размером выборки.
В: Хойл Р., редактор. Статистические стратегии для исследования малых выборок. Таузенд-Оукс, Калифорния: Сейдж; 1999. с. 1–29.
[25] Meulman JJ, Heiser WJ. Категории SPSS 19.0. Чикаго, Иллинойс: SPSS Inc .; 2011.
[26] Исследовательская сеть NICHD по уходу за детьми младшего возраста. Характеристики ухода за младенцами: факторы, способствующие положительному уходу
.Early Child Res Q. 1996; 11: 269–306.
[27] Costa PT Jr, McCrae RR. Руководство по инвентаризации личности NEO. Одесса, Флорида: ресурсы психологической оценки
Inc .; 1985.
[28] Radloff LS. Шкала CES-D: шкала самооценки депрессии для исследования среди населения в целом. Appl Psychol
Измер. 1977; 1: 385–401.
[29] Алисик Э., Ван дер Шут Т.А., Ван Гинкель Дж. Р., Клебер Р. Дж. Взгляд за пределы ПТСР у детей: посттравматический стресс
реакции, посттравматический рост и качество жизни.J Clin Psychiatry. 2008; 69: 1455–1461.
[30] Ravens-Sieberer U, Auquier P, Erhart M, Gosch A, Rajmil L, Bruil J, Power M, DuerW, Cloetta B, Czemy L, Mazur
J, Czimbalmos A, Tountas Y, Hagquist C, Килро Дж., Европейская группа KIDSCREEN. KIDSCREEN-27 для
детей и подростков: психометрические результаты кросс-культурного исследования в 13 европейских странах. Qual Life
Res. 2007. 16: 1347–1356.
Загружено [Universiteit Leiden / LUMC] в 05:13, 15 июля 2014 г.
Запуск платформы основных компонентов
Запустите платформу основных компонентов, выбрав «Анализ»> «Многовариантные методы»> «Основные компоненты».Анализ главных компонентов также доступен с использованием многомерных платформ и трехмерных диаграмм рассеяния.
В примере, описанном в разделе «Пример анализа главных компонентов», используются все непрерывные переменные из таблицы данных образца Solubility.jmp.
Рисунок 4.3 Окно запуска основных компонентов
Для получения дополнительной информации о параметрах в меню красного треугольника «Выбрать столбцы» см. Меню фильтра столбцов в разделе «Использование JMP».
Y, столбцы
Переменные для анализа компонентов.
Z, дополнительная переменная
Дополнительные переменные для отображения. Дополнительные переменные не включаются в расчет основных компонентов, и их включение не влияет на результаты. Дополнительные переменные, которые являются непрерывными, можно спроецировать на график нагрузки и использовать для улучшения интерпретации.
Вес
Определяет один столбец, числовые значения которого присваивают вес каждой строке в анализе.
Примечание. Роль веса игнорируется для методов оценки Wide и Sparse.
Freq
Определяет один столбец, числовые значения которого присваивают частоту каждой строке в анализе.
Примечание. Роль Freq игнорируется для методов оценки Wide и Sparse.
По
Создает отчет о главных компонентах для каждого значения, указанного в столбце По, чтобы можно было выполнять отдельный анализ для каждой группы.
Метод оценки
Определяет метод вычисления корреляций. Некоторые из этих методов предназначены для обработки недостающих данных.
По умолчанию
Параметр По умолчанию использует методы по строкам, попарно или REML. JMP Alert также рекомендует при необходимости переключиться на широкий метод.
— Построчное оценивание используется для таблиц данных без пропущенных значений.
— Попарная оценка используется для таблиц данных с пропущенными значениями и более чем 10 столбцами, более чем 5000 строк или большим количеством столбцов, чем строк.
— В противном случае используется оценка REML.
— Окно предупреждений JMP рекомендуется для широких оценок для таблиц данных с более чем 500 столбцами.Это связано с тем, что время вычислений может быть значительным при использовании других методов с большим количеством столбцов. Нажмите «Широкий», чтобы переключиться на метод «Широкий», или нажмите «Продолжить», чтобы использовать изначально выбранный метод.
REML
Оценка ограниченного максимального правдоподобия (REML) использует все данные, даже если присутствуют пропущенные значения. Из-за коэффициента коррекции смещения этот метод работает медленно, если набор данных большой и имеется много пропущенных значений. Следовательно, REML наиболее полезен для небольших наборов данных.Если в данных нет пропущенных ячеек, то оценки REML и ML эквивалентны и равны выборочной ковариационной матрице. Если есть пропущенные ячейки, оценки дисперсии и ковариации REML менее смещены, чем оценки из оценки ML. Подробнее о статистике см. REML.
ML
При оценке максимального правдоподобия (ML) используются все данные, даже если присутствуют пропущенные значения. Поскольку оценки из машинного обучения генерируются быстро, этот метод наиболее полезен для больших таблиц данных с отсутствующими данными.
Надежная
Надежная оценка использует все данные, даже если присутствуют пропущенные значения. Этот метод понижает вес экстремальных значений и поэтому полезен для таблиц данных, которые могут иметь выбросы. Подробнее о статистике см. В разделе «Надежность» в разделе «Корреляции и многомерные методы».
По строкам
Оценка по строкам вычисляет корреляцию Пирсона для каждой пары столбцов. Для получения статистических сведений см. Корреляцию продукта и момента Пирсона в разделе «Корреляции и многомерные методы».Построчное оценивание не использует наблюдения с пропущенными значениями. Этот метод полезен для исключения любых наблюдений, для которых отсутствуют данные.
Парная
Парная оценка использует все данные, даже если присутствуют пропущенные значения. Этот метод оценки вычисляет корреляции Пирсона для каждой пары столбцов с использованием всех наблюдений с непропущенными значениями для этих двух столбцов. Для получения статистических сведений см. Корреляцию продукта и момента Пирсона в разделе «Корреляции и многомерные методы».Попарная оценка наиболее полезна, когда в таблице данных отсутствуют значения и столбцов больше, чем строк, больше 10 столбцов или больше 5000 строк.
Wide
Wide Оценка не использует наблюдения с пропущенными значениями, поэтому строки, содержащие отсутствующие ячейки, удаляются перед применением метода. В этом методе оценки используется алгоритм, основанный на полном разложении по сингулярным числам. Алгоритм избегает вычисления ковариационной матрицы и, следовательно, эффективен с точки зрения вычислений.Это полезно, когда в ваших данных очень много столбцов. Для получения статистических сведений см. Широкий.
Sparse
Sparse оценка использует все данные, даже если присутствуют пропущенные значения. Этот метод оценки использует алгоритм, основанный на частичном разложении сингулярных значений, который вычисляет только первое указанное количество сингулярных значений и векторов сингулярных значений. Алгоритм позволяет избежать вычисления ковариационной матрицы, а также ненужных главных компонентов и, следовательно, эффективен с точки зрения вычислений.Это полезно, когда ваши данные разрежены, то есть содержат много нулей, или когда в данных много столбцов. Для получения статистических сведений см. Разреженный.
Примечание. Если вы выбрали REML, ML или Надежный, а ваша таблица данных содержит больше столбцов, чем строк и содержит пропущенные значения, JMP переключает метод оценки на попарный.
Количество компонентов
(Доступно, только если в качестве метода оценки указано «Разреженное».) Задает количество компонентов для оценки.Обычно количество компонентов намного меньше размера ваших данных.
Отсутствующие данные
Различные методы оценки позволяют обрабатывать отсутствующие данные различными способами. Вы также можете оценить пропущенные значения следующими способами:
• Используйте опцию «Вменять недостающие данные» в разделе «Многомерные методы»> «Многомерные». См. «Вменять отсутствующие данные» в разделе «Корреляции и многомерные методы».
• Используйте утилиты Multivariate Normal Imputation или Multivariate SVD Imputation, которые находятся в разделе Анализ> Скрининг> Исследовать отсутствующие значения.См. Утилиту «Изучение отсутствующих значений» в прогнозном и специализированном моделировании.
.
allentran / pca-magic: PCA, который итеративно заменяет отсутствующие данные
Реализация вероятностного анализа основных компонентов, который является вариантом ванильного PCA, который может использоваться для
- вычислить коэффициенты, при которых некоторые данные отсутствуют
- интерполировать данные, используя информацию из дополнительных серий
Часто вы хотите использовать PCA, но ваши данные разбиты на недостающие данные.См. Ниже, где белый цвет представляет отсутствующие данные в 14k + временных рядах в Current Population Survey, ежемесячном обследовании около 60k домашних хозяйств, проводимом Бюро переписи населения США с 1940 года.
Если достаточное количество данных не отсутствует, вы можете заполнить недостающие данные с помощью выборочных средних или какого-либо другого интерполированного значения, но если у вас слишком много отсутствующих данных, ваша рудиментарная интерполяция будет подавлять сигнал в данных с шумом. (Подумайте о предельном случае, когда отсутствуют все данные, кроме одной).
Лучший способ: предположим, у вас есть скрытые факторы, представляющие матрицу. Постройте линейную модель для каждой серии, а затем используйте полученную модель для интерполяции. Интуитивно это сохранит сигнал из данных, поскольку интерполированные значения происходят из скрытых факторов.
Однако проблема в том, что у вас никогда не бывает этих факторов с самого начала. Старая проблема с курицей и яйцом. Но неважно, на помощь приходят алгоритмы с фиксированной точкой через Probabilistic PCA.
С этой стратегией более 50 процентов дисперсии этих 14k + временных рядов в CPS можно объяснить всего лишь 12 факторами.
Установка
Установить через pip:
pip install ppca
Загрузить данные, которые должны быть расположены как n_samples на функций . Как обычно, вы должны убедиться, что ваши данные являются стационарными (если возможно, сделайте первые различия) и стандартизированы.
из ppca импорта PPCA
ppca = PPCA ()
Совместите модель с параметром d , указав количество компонентов и подробный вывод сходимости печати, если требуется.
ppca.fit (data = data, d = 100, verbose = True)
Параметры и компоненты модели будут прикреплены к объекту ppca.
variance_explained = ppca.var_exp
компоненты = ppca.data
model_params = ppca.C
Если вам нужны основные компоненты, вызовите преобразование .
component_mat = ppca.transform ()
Выполните примерку модели, сохраните модель, если хотите.
ppca.сохранить ('mypcamodel')
Загрузите модель, запостите экземпляр объекта PPCA. Это значительно ускорит примерку / трансформацию.
ppca.load ('mypcamodel.npy')
Пошаговое объяснение анализа основных компонентов
Цель этого поста — предоставить полное и упрощенное объяснение анализа основных компонентов и, особенно, пошагово ответить, как он работает, чтобы каждый мог его понять и использовать его, не обязательно имея сильную математическую подготовку.
PCA на самом деле широко освещенный в сети метод, и о нем есть несколько отличных статей, но лишь немногие из них переходят прямо к сути и объясняют, как он работает, не вдаваясь в технические детали и «почему» вещи. По этой причине я решил сделать свой пост, чтобы представить его в упрощенном виде.
Прежде чем перейти к объяснению, этот пост предоставляет логические объяснения того, что PCA делает на каждом шаге, и упрощает лежащие в его основе математические концепции, такие как стандартизация, ковариация, собственные векторы и собственные значения, не уделяя внимания тому, как их вычислять.
Что такое анализ главных компонентов?
Анализ главных компонентов, или PCA, — это метод уменьшения размерности, который часто используется для уменьшения размерности больших наборов данных путем преобразования большого набора переменных в меньший, который по-прежнему содержит большую часть информации в большом наборе. .
Уменьшение количества переменных в наборе данных, естественно, происходит за счет точности, но хитрость в уменьшении размерности состоит в том, чтобы торговать небольшой точностью ради простоты.Поскольку меньшие наборы данных легче исследовать и визуализировать, а анализ данных становится намного проще и быстрее для алгоритмов машинного обучения без обработки посторонних переменных.
Подводя итог, можно сказать, что идея PCA проста — уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
Пошаговое объяснение PCA
Шаг 1: Стандартизация
Целью этого шага является стандартизация диапазона непрерывных исходных переменных, чтобы каждая из них в равной степени способствовала анализу.
Более конкретно, причина, по которой так важно выполнить стандартизацию до PCA, заключается в том, что последний очень чувствителен к дисперсиям исходных переменных. То есть, если есть большие различия между диапазонами исходных переменных, те переменные с большими диапазонами будут преобладать над переменными с небольшими диапазонами (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1. ), что приведет к необъективным результатам. Таким образом, преобразование данных в сопоставимые масштабы может предотвратить эту проблему.
Математически это можно сделать путем вычитания среднего и деления на стандартное отклонение для каждого значения каждой переменной.
После завершения стандартизации все переменные будут преобразованы в один и тот же масштаб.
Шаг 2: Вычисление ковариационной матрицы
Цель этого шага — понять, как переменные набора входных данных отличаются от среднего по отношению друг к другу, или, другими словами, чтобы увидеть, есть ли отношения между ними.Потому что иногда переменные сильно коррелированы и содержат избыточную информацию. Итак, чтобы идентифицировать эти корреляции, мы вычисляем ковариационную матрицу.
Ковариационная матрица — это симметричная матрица p × p (где p — количество измерений), в которой в качестве элементов есть ковариации, связанные со всеми возможными парами исходных переменных. Например, для трехмерного набора данных с 3 переменными x , y и z ковариационная матрица представляет собой матрицу 3 × 3 из:
Ковариационная матрица для трехмерных данныхПоскольку ковариация переменной с самой собой — это ее дисперсия (Cov (a, a) = Var (a)), на главной диагонали (сверху слева направо снизу) у нас фактически есть дисперсии каждой исходной переменной.А поскольку ковариация коммутативна (Cov (a, b) = Cov (b, a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны.
Что ковариации, которые мы имеем в качестве элементов матрицы, говорят нам о корреляциях между переменными?
На самом деле имеет значение знак ковариации:
- , если положительный, то: две переменные увеличиваются или уменьшаются вместе (коррелировано)
- , если отрицательно, то: одна увеличивается, когда другая уменьшается (обратно коррелирована)
Сейчас , что мы знаем, что ковариационная матрица — это не более чем таблица, которая суммирует корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
Шаг 3: Вычислить собственные векторы и собственные значения ковариационной матрицы для определения главных компонентов
Собственные векторы и собственные значения — это концепции линейной алгебры, которые нам необходимо вычислить из ковариационной матрицы для определения главных компонентов данных. Прежде чем перейти к объяснению этих концепций, давайте сначала поймем, что мы подразумеваем под основными компонентами.
Основные компоненты — это новые переменные, которые построены как линейные комбинации или смеси исходных переменных.Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных сжимается или сжимается в первых компонентах. Итак, идея состоит в том, что 10-мерные данные дают вам 10 основных компонентов, но PCA пытается поместить максимум возможной информации в первый компонент, затем максимум оставшейся информации во второй и так далее, пока не появится что-то вроде того, что показано на графике осыпи ниже.
Процент отклонения (информации) для каждого ПКТакая организация информации по основным компонентам позволит вам уменьшить размерность без потери большого количества информации, и это за счет отбрасывания компонентов с низкой информацией и рассмотрения оставшихся компонентов как ваших новых переменных.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения, главные компоненты представляют направления данных, которые объясняют максимальную величину отклонения , то есть линии, которые захватывают большую часть информации данных. Связь между дисперсией и информацией здесь заключается в том, что чем больше дисперсия, переносимая линией, тем больше дисперсия точек данных вдоль нее, и чем больше дисперсия вдоль линии, тем больше информации она содержит.Проще говоря, просто думайте о главных компонентах как о новых осях, которые обеспечивают лучший угол для просмотра и оценки данных, чтобы различия между наблюдениями были лучше видны.
Будьте в курсе последних технологических тенденций
Зарегистрируйтесь бесплатно, чтобы получать больше подобных историй о науке о данных.
Как PCA конструирует основные компонентыПоскольку главных компонентов столько же, сколько переменных в данных, главные компоненты строятся таким образом, что первый главный компонент составляет наибольшую возможную дисперсию в наборе данных.Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и это линия, на которой проекция точек (красные точки) является наиболее разбросанной. Или, говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых точек (красные точки) до начала координат).
Второй главный компонент рассчитывается таким же образом, при условии, что он не коррелирует с (т.е., перпендикулярно первому главному компоненту, и что он составляет следующую по величине дисперсию.
Это продолжается до тех пор, пока не будет вычислено общее количество p главных компонентов, равное исходному количеству переменных.
Теперь, когда мы поняли, что мы подразумеваем под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. Прежде всего вам нужно знать о них, что они всегда попадают в пары, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных.Например, для трехмерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
Без лишних слов, за всей магией, описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются направлениями осей, где наибольшая дисперсия информация) и то, что мы называем основными компонентами. А собственные значения — это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину отклонения , содержащуюся в каждом основном компоненте .
Ранжируя собственные векторы в порядке их собственных значений, от наибольшего к наименьшему, вы получаете главные компоненты в порядке значимости.
Пример:
предположим, что наш набор данных является двумерным с двумя переменными x, y и что собственные векторы и собственные значения ковариационной матрицы следующие:
Если мы ранжируем собственные значения в В порядке убывания мы получаем λ1> λ2, что означает, что собственный вектор, соответствующий первой главной компоненте (PC1), равен v1, , а тот, который соответствует второму компоненту (PC2), равен v2.
После определения главных компонентов для вычисления процента дисперсии (информации), приходящейся на каждый компонент, мы делим собственное значение каждого компонента на сумму собственных значений. Если мы применим это к приведенному выше примеру, мы обнаружим, что ПК1 и ПК2 несут соответственно 96% и 4% дисперсии данных.
Шаг 4: Вектор признаков
Как мы видели на предыдущем шаге, вычисление собственных векторов и их упорядочение по их собственным значениям в порядке убывания позволяет нам найти главные компоненты в порядке значимости.На этом этапе мы выбираем, оставить ли все эти компоненты или отбросить те, которые имеют меньшее значение (с низкими собственными значениями), и сформировать с оставшимися матрицу векторов, которую мы называем Вектор признаков .
Итак, вектор признаков — это просто матрица, в столбцах которой есть собственные векторы компонентов, которые мы решили оставить. Это делает его первым шагом к уменьшению размерности, потому что, если мы решим оставить только p собственных векторов (компонентов) из n , окончательный набор данных будет иметь только p размеров.
Пример :
Продолжая пример из предыдущего шага, мы можем либо сформировать вектор признаков с обоими собственными векторами v 1 и v 2:
, либо отбросить собственный вектор v 2, который имеет меньшее значение и формирует вектор признаков с v только 1:
Отказ от собственного вектора v2 уменьшит размерность на 1 и, следовательно, вызовет потерю информации в окончательном наборе данных.Но, учитывая, что v 2 несут только 4% информации, потеря, следовательно, не будет важной, и у нас все еще будет 96% информации, которая переносится v 1.
Итак, как мы видели в этом примере вам решать, сохранить ли все компоненты или отбросить менее важные, в зависимости от того, что вы ищете. Потому что, если вы просто хотите описать свои данные в терминах новых переменных (главных компонентов), которые не коррелированы, не стремясь уменьшить размерность, не нужно исключать менее значимые компоненты.
Последний шаг: повторное преобразование данных по осям основных компонентов
На предыдущих шагах, помимо стандартизации, вы не вносили никаких изменений в данные, вы просто выбираете главные компоненты и формируете вектор признаков, но набор входных данных всегда остается в терминах исходных осей (т. е. в терминах исходных переменных).
На этом последнем шаге цель состоит в том, чтобы использовать вектор признаков, сформированный с использованием собственных векторов ковариационной матрицы, для переориентации данных с исходных осей на оси, представленные главными компонентами (отсюда и название Основные компоненты). Анализ компонентов).Это можно сделать, умножив транспонирование исходного набора данных на транспонирование вектора признаков.
* * *
Закария Джаади — специалист по анализу данных и инженер по машинному обучению. Ознакомьтесь с другими его материалами по темам Data Science на Medium.
Ссылки :
- [Стивен М.