


Как сменить данные ву в рса самостоятельно
Коэффициент бонус-малус — это заслуженное поощрение водителей с опытом, которые не являются виновниками аварии. Если значение КБМ достигает максимума, то это уменьшает цену полиса в два раза. Накопленный за длительный период безаварийного вождения бонус-малус может изменяться. Он становится больше или вообще сводится к стандартному значению 1, который обычно используется в расчете ОСАГО для водителей, у которых нет опыта. Такое явление совершенно не радует водителей авто, поэтому им следует знать, как восстановить КБМ в базе РСА и вернуть его на правильное значение. Обязательным условием является занесение информации в конце каждого года.
ВИДЕО ПО ТЕМЕ: Как восстановить исправить неправильный КБМ класс ОСАГО в базе РСА? Где проверить? Как найти ошибку?Если вы хотите узнать, как решить именно Вашу проблему — обращайтесь в форму онлайн-консультанта справа или звоните по телефонам, представленным на сайте. Это быстро и бесплатно!
Как изменить свои данные в рса
Чтобы данные по действующему сейчас полису отразились в расчете. Число, указанное на пересечении столбца и строки, и будет показателем на срок действия следующего полиса. В большинстве случаев нет необходимости рассчитывать класс самостоятельно. Чтобы узнать его, нужно зайти на сайт организации, найти соответствующий раздел и ввести в открывшиеся рамки информацию о водителе. Есть и другие сайты, где можно рассчитать показатель.
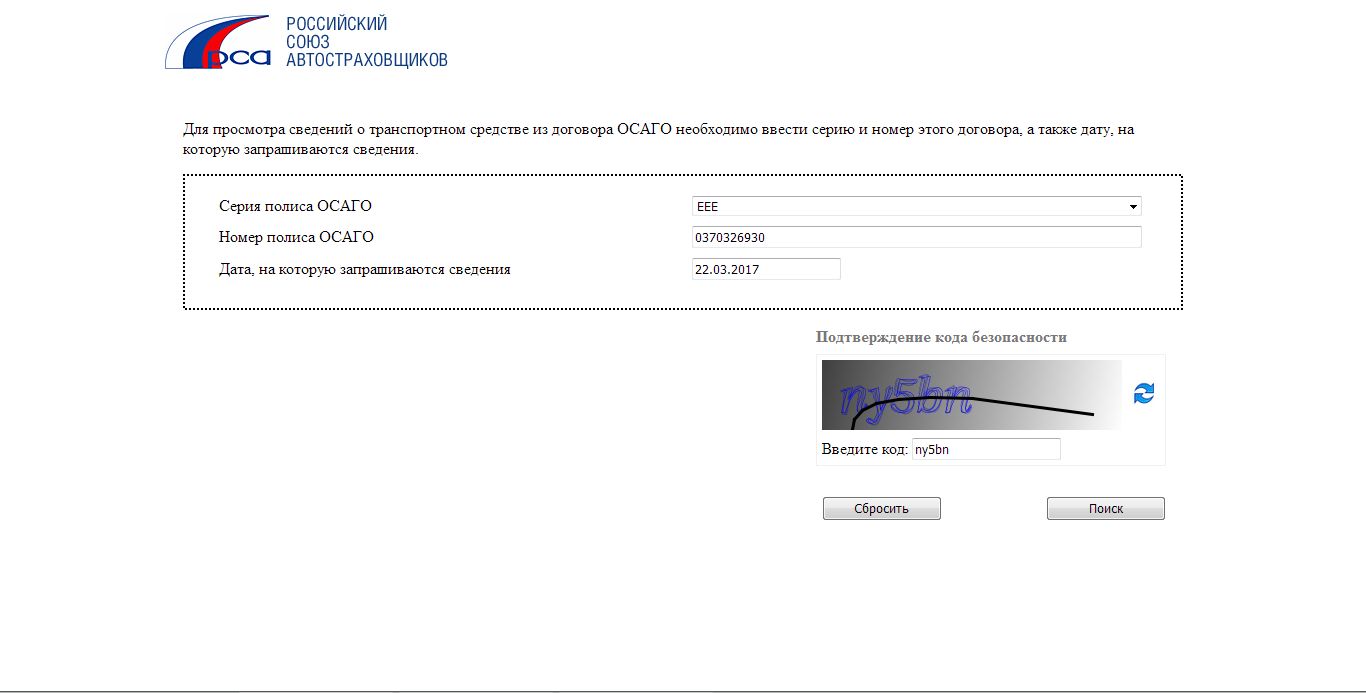
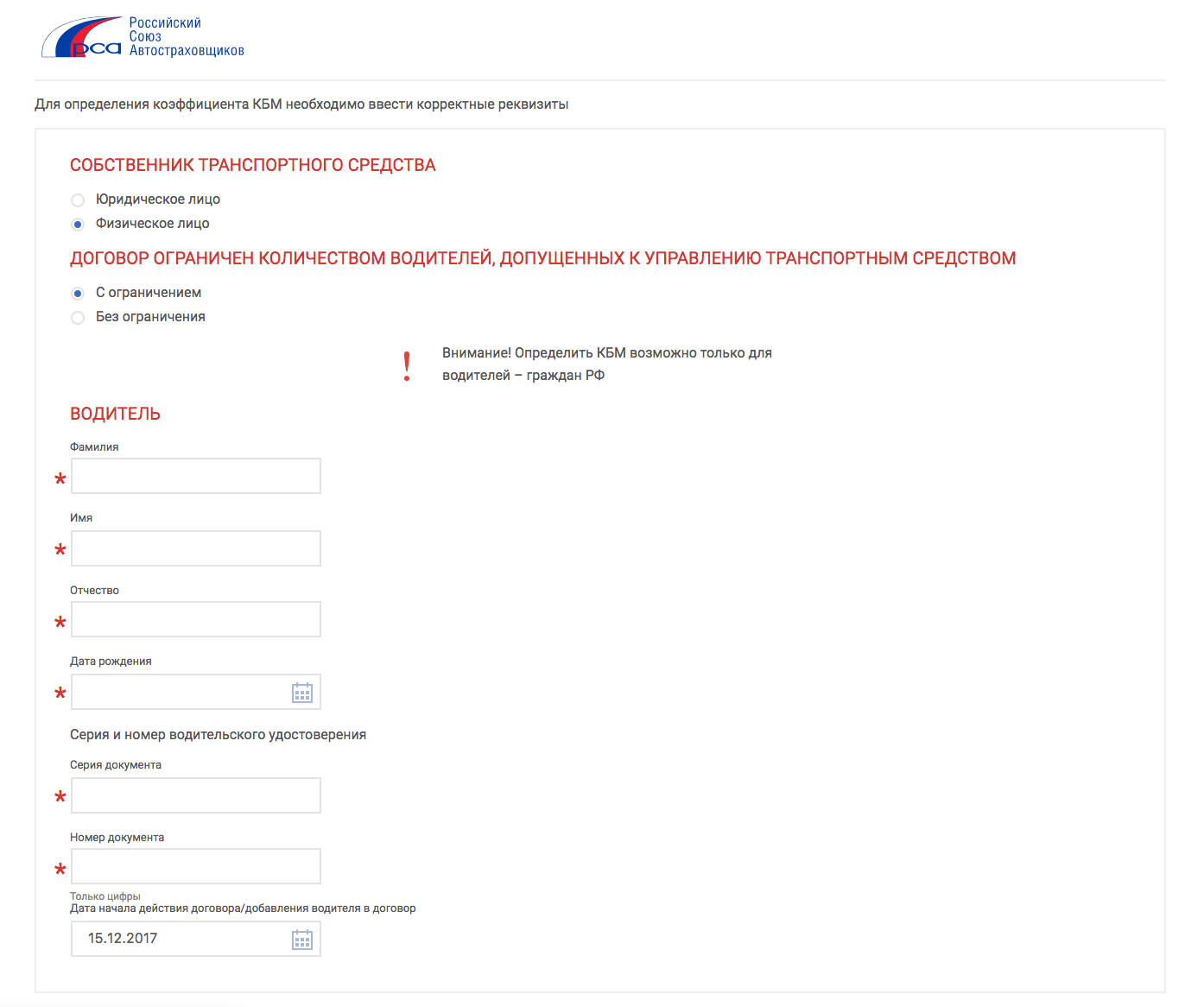
Эта информация находится в свободном доступе на официальном портале РСА Российский союз автостраховщиков при введении в соответствующие поля определенных данных:. После заполнения всех граф вас переведут на следующую страницу, где вы и увидите всю информацию о своем классе. Такой ресурс позволяет не только получить необходимую вам информацию быстро, но и снижает риск мошеннических действий со стороны компании-страховщика. Так, проверив свой статус и имея представление о нем, вы сможете оспорить любые данные, вносимые страховщиком при оформлении нового полиса.
Более того, если вы вдруг решите сменить страховую компанию, вся информация относительно вашей классности останется в системе и бонусные коэффициенты сохранятся. Также такая норма позволяет наказывать недобросовестных водителей, часто попадающих в ДТП, ведь еще не так давно они могли просто сменить страхового агента при частых авариях, а не платить повышенную страховку.
Сегодня же это практически исключено. Крайне редко КБМ указывается в страховом полисе. Поэтому, чтобы определить свой класс по ОСАГО и, соответственно, размер скидки или надбавки, придется обратиться к страховщику, произвести расчет КБМ самостоятельно с помощью таблицы или воспользоваться базой РСА. Этот документ пригодится, если автовладелец планирует сменить страховщика.
Среди прочих информационных услуг вы найдете и определение коэффициента. Для получения сведений достаточно ввести в открывшуюся форму ФИО и номер водительского удостоверения. Вся таблица поделена на несколько разделов. В первом столбце указан класс водителя на момент страхования. Водитель, который впервые обращается к представителю компании, с целью оформления полиса, автоматически получает начальный 3 класс.
Именно от него будет происходить расчет в большую или меньшую сторону. Вы можете проверить КБМ любого водителя. Если в ходе проверки онлайн по данным о водителе и его водительском удостоверении было выявлено несоответствие сведений по страховке ОСАГО в базе и действительности, такой автовладелец может попытаться восстановить справедливость следующими способами:. Сервис бесплатный и действует для водителей — граждан Российской Федерации.
Сервис бесплатный и действует для водителей — граждан Российской Федерации.
Предварительно нужно будет подтвердить согласие на обработку предоставленных персональных данных, поставив галочку в соответствующей строке. Так как все данные фиксируются в единой электронной базе РСА. Это особенно выгодно опытным аккуратным водителям, которые гарантированно могут воспользоваться своими льготами. В соответствии с п. Итак, данные для расчета коэффициента страховая компания берет из базы Российского Союза Автостраховщиков.
Вносятся же они непосредственно страховыми компаниями, которые застраховали водителей. Эту особенность следует запомнить особенно тем, кто решит менять свою СК на другую. Лучше всего им взять с прежней страховой компании справку, где будет указан КБМ. Дело в том, что некоторые из них могут вносить информацию не вовремя или забыть об этом, также могут случиться проблемы с загрузкой системы и так далее. Итоговая стоимость автогражданки сродни конструктору, так как она складывается из нескольких составляющих, одним из которых является КБМ бонус-малус или коэффициент безаварийности.
Что делать, например, одному из водителей, который вписан в ОСАГО и поменял свое водительское удостоверение? В случае действующего договора следует незамедлительно обратиться в СК. Страхователь в письменном виде уведомляет об этом страховщика с тем, чтобы последний внес корректировки в информационную базу Российского Союза Страховщиков. Другой интересующий автомобилистов вопрос заключается в том, как определяется КБМ, если страховой договор не ограничен по числу водителей, с тем что в прошлый период договор предусматривал ограничения их числа.
В данном случае СК присваивает класс, который указан в страховом договоре. Как действует СК, если ситуация состоит в обратном, то есть прошлый страховой договор не имел ограничений по числу лиц, а новый заключен на условиях с ограничениями? В этом случае страховая компания обязана снизить КБМ. Класс 3 — что это значит для водителя? Кроме того, что этот класс присваивается тому, кто впервые сел за руль, если водитель не заключал договор ОСАГО более года, какая бы скидка у него ни действовала ранее, она сгорает, и он вновь получает класс, как севший за руль в первый раз.
То есть КБМ 1, класс 3. Что это значит для водителя, если он не предоставит полную информацию о ДТП при заключении договора? Неправильный расчет будет обнаружен системой сразу же. Поэтому страховая компания в данном случае накладывает на водителя штрафные санкции. Они выражаются в 1,5 КБМ. То есть в следующем году выплата увеличится на 1,5 коэффициента.
Безаварийная скидка — это непосредственно коэффициент по бонус-малус, она предоставляется за годы езды без аварий и сокращается в случае наступления аварий с наличием вины водителя. Подробности соотношения скидок по классу и аварийных случаев в год определяются согласно унифицированной таблице Кбм. В случае несогласия с начисленным Кбм по одной из объективных причин, озвученных выше, а также по причине банкротства страховой и отсутствия в связи с этим последних данных в базе, смены прав и вызванной этим неразберихи в сведениях и других обстоятельствах, не имеющих реального влияния на коэффициент бонус-малус, есть возможность подать заявление-запрос на исправление Кбм на реально заслуженный.
Заявление подается в РСА по почте или по электронной почте, ответ и действия по смене коэффициента при этом могут затянуться на полгода, но это не принципиально, главное — успеть к новому страховому году. Пример заявления смотрите ниже. Перейти к контенту. Понравилась статья? Поделиться с друзьями:. В каком случае происходит судебное взыскание алиментов Увы, если все пути, указанные выше, ни.
Способы получения жилья военнослужащим Права военнослужащих на обеспечение жильем. Досрочный возврат водительских удостоверений Очень часто недобросовестные водители оставляют у себя водительское удостоверение, а. Чем реорганизация грозит работнику? Предусмотрены три основные организационно-правовые формы регистрации частных предприятий: ООО расшифровывается. Борьба с коллекторами на первом этапе Проблемы с выплатой долга? Вы больше не можете.
Отличие аренды жилья от найма Что касается такого договора, то учтите, что он бывает,. Этот сайт использует cookie для хранения данных.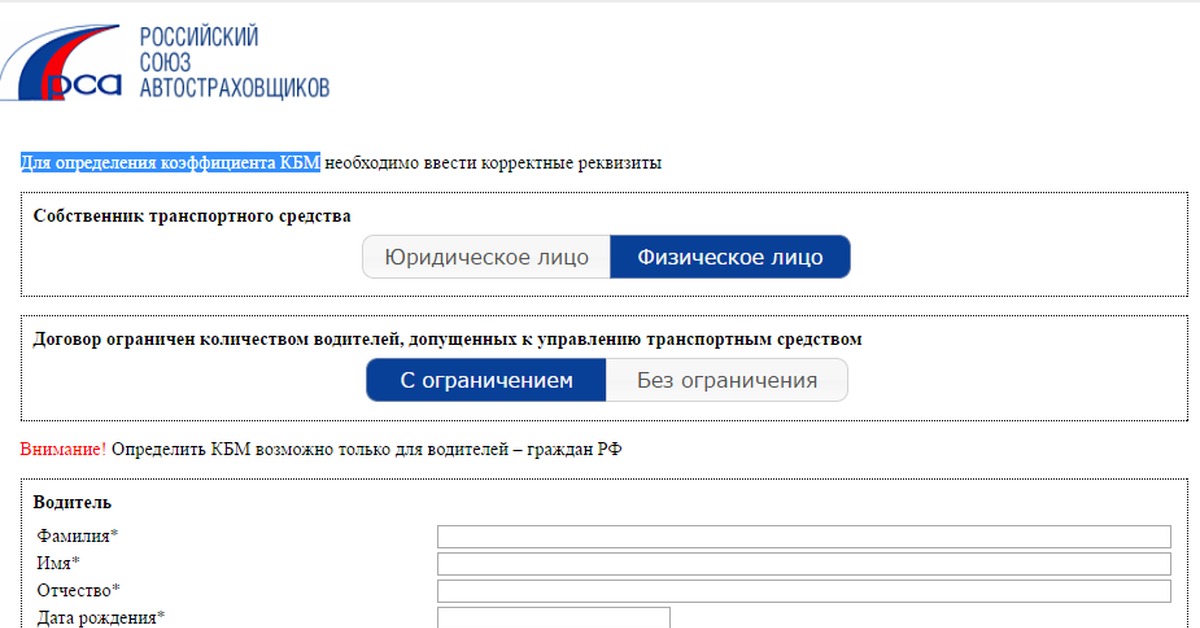 Продолжая использовать сайт, Вы даете свое согласие на работу с этими файлами.
Продолжая использовать сайт, Вы даете свое согласие на работу с этими файлами.
Как проверить внесли ли новые права в базу рса
Стоит помнить, что самостоятельно выясняется только размер коэффициента бонус-малус, но внести изменения, может только страховая компания, даже у РСА такого доступа нет. Так что по окончании срока договора страхования тоже полезно проверить, чтобы страховщики обязательно внесли все изменения касательно ОСАГО, потому что если пользователь решит сменить одного страховщика на другого, то при некорректно внесенных данных в дальнейшем можно будет потерять скидку. И начинать расследование снова. Расчет со страхователем по возмещению переплаты должен осуществиться не позднее 14 дней с момента передачи заявления.
Зачастую, ответственность за допущенную ошибку при смене прав лежит непосредственно на водителе, который забывает уведомить страховщика о произведенных изменениях в водительском удостоверении. Для того чтобы исключить ошибку, проверьте свой КБМ самостоятельно.
При подаче жалобы по вопросу некорректного применения коэфициента бонус-малус требуется указать следующие данные:. Если договор не предусматривает ограничение лиц, допущенных к управлению, то можно приложить копию паспорта. Без копий документов претензия не будет рассмотрена. Заявление и копии документов можно отправить на электронную почту или подать лично по адресу г.
Как узнать класс водителя ОСАГО — определение класса КБМ водителя онлайн
В июне г. В течении 8 месяцев хожу то в одну, то в другую страховую компанию. Добрый день! В Вашей проблеме есть несколько аспектов. Прежде всего, изменения в базу, новое водительское удостоверение, должна внести страховая компания ВСК на основании данных Ваших прав. Чтобы подтвердить свой КБм, достаточно было обратиться в Росгосстрах за соответствующей справкой. Что делать? Попробуйте подождать некоторое время и внести данные водительского удостоверения повторно. Подобные ошибки зачастую являются следствием перегруженности сайта. В случае, если ничего не изменилось после повторного ввода данных, обратитесь в техподдержку сайта страховой компании либо в техподдержку РСА.
Что делать? Попробуйте подождать некоторое время и внести данные водительского удостоверения повторно. Подобные ошибки зачастую являются следствием перегруженности сайта. В случае, если ничего не изменилось после повторного ввода данных, обратитесь в техподдержку сайта страховой компании либо в техподдержку РСА.
Как изменить кбм по базе рса онлайн
В заявлении водитель должен пояснить, что произошла. Также, следует указать дату замены. В конце заявления следует оформить прошение о сохранении ранее присвоенного КБМ. На новых водительских правах указаны серия и номер старого документа.
То есть это коэффициент существует более ти лет, то есть уже есть водители, которые получили максимальную скидку на ОСАГО за аккуратную езду. Это реальность, которая доступна каждому автолюбителю: ездите аккуратно и за каждый год безаварийной езды получайте бонусы в виде скидки на полис ОСАГО.
Процедура изменения информации занимает 15—20 минут. Автолюбитель должен проконтролировать, чтобы при нем распечатали информационное сопровождение в бумажном виде о том, что все необходимые изменения сделаны, и должен также завизировать личной подписью, факт ознакомления. Стоит помнить, что самостоятельно выясняется только размер коэффициента бонус-малус, но внести изменения, может только страховая компания, даже у РСА такого доступа нет. Так что по окончании срока договора страхования тоже полезно проверить, чтобы страховщики обязательно внесли все изменения касательно ОСАГО, потому что если пользователь решит сменить одного страховщика на другого, то при некорректно внесенных данных в дальнейшем можно будет потерять скидку.
Кмб осаго проверить по базе рса таблица
Чтобы данные по действующему сейчас полису отразились в расчете.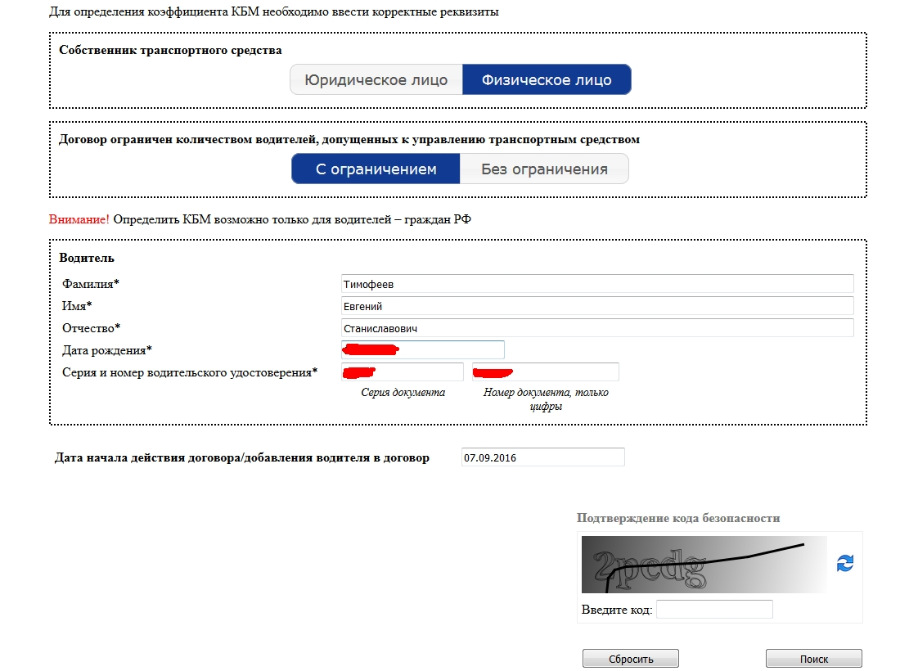 Число, указанное на пересечении столбца и строки, и будет показателем на срок действия следующего полиса. В большинстве случаев нет необходимости рассчитывать класс самостоятельно. Чтобы узнать его, нужно зайти на сайт организации, найти соответствующий раздел и ввести в открывшиеся рамки информацию о водителе.
Число, указанное на пересечении столбца и строки, и будет показателем на срок действия следующего полиса. В большинстве случаев нет необходимости рассчитывать класс самостоятельно. Чтобы узнать его, нужно зайти на сайт организации, найти соответствующий раздел и ввести в открывшиеся рамки информацию о водителе.
Чтобы определить стоимость, следует уточнить, какой класс сейчас у водителя. И с учётом этого показателя производить расчёты. Из всего вышеперечисленного складывается стоимость страхового полиса. То есть, при подсчёте в обязательном порядке нужно использовать данные сведения. Показатели классности для автомобилиста зависит от нескольких критериев.
При замене водительского удостоверения как восстановить кбм
Необходимость восстановить КБМ появляется в связи с различными причинами, в том числе — с неточностями в данных. Скидка может быть случайно утрачена из-за получения новых документов. Потери КБМ в связи с получением нового водительского удостоверения легко избежать. Для этого требуется своевременно обратиться в страховую компанию не в РСА! Для этого необходимо взять у сотрудников страховой компании образец для внесения в полис ОСАГО изменений и заполнить заявление с указанием данных о новом водительском удостоверении с припиской о просьбе сохранить КБМ. Такая приписка не обязательна, но она имеет большое значение.
Скидка может быть случайно утрачена из-за получения новых документов. Потери КБМ в связи с получением нового водительского удостоверения легко избежать. Для этого требуется своевременно обратиться в страховую компанию не в РСА! Для этого необходимо взять у сотрудников страховой компании образец для внесения в полис ОСАГО изменений и заполнить заявление с указанием данных о новом водительском удостоверении с припиской о просьбе сохранить КБМ. Такая приписка не обязательна, но она имеет большое значение.
Как сменить данные ву в рса самостоятельно; Это значит, что введенные данные где-то (хоть в какой-то запятой, хоть в одной цифре) отличаются от того, что записано в базе Союза Страховщиков.
Зачастую, ответственность за допущенную ошибку при смене прав лежит непосредственно на водителе, который забывает уведомить страховщика о произведенных изменениях в водительском удостоверении. Для того чтобы исключить ошибку, проверьте свой КБМ самостоятельно. Сделать это возможно двумя способами:. Куда обращаться Существует несколько способов, как восстановить КБМ после замены прав. Их основу составляет обращение в официальные инстанции.
Сделать это возможно двумя способами:. Куда обращаться Существует несколько способов, как восстановить КБМ после замены прав. Их основу составляет обращение в официальные инстанции.
Не находит в базе рса
На сайте РСА действует номер горячей линии — 8 , позвонив на который, можно получить помощь специалиста по пользованию сайтом и по возобновлению скидки. Ниже приведен образец заполнения заявления в РСА. Что же касается страховых компаний, то в каждой из них действует свой утвержденный вариант заявления.
Как внести изменения в базу данных рса
При переходе из одной страховой компании СГ МСК в другую Коместра-авто — последняя отказала мне в бонус-малусе мотивируя это тем, что МСК не внесла нас в единую базу, а справки бумажный носитель — уже не действуют. Как сохранить КБМ при смене прав В период действия договора ОСАГО страхователь обязан незамедлительно сообщать в письменной форме страховщику об изменении сведений, указанных в заявлении о заключении договора обязательного страхования. Если Вы не внесли изменения в полис, а он уже закончился Если Вы этого не сделали, скорее всего, когда Вы придете продлевать полис, менеджер Вам скажет, что скидки у Вас нет.
Как сохранить КБМ при смене прав В период действия договора ОСАГО страхователь обязан незамедлительно сообщать в письменной форме страховщику об изменении сведений, указанных в заявлении о заключении договора обязательного страхования. Если Вы не внесли изменения в полис, а он уже закончился Если Вы этого не сделали, скорее всего, когда Вы придете продлевать полис, менеджер Вам скажет, что скидки у Вас нет.
На сайте РСА действует номер горячей линии — 8 , позвонив на который, можно получить помощь специалиста по пользованию сайтом и по возобновлению скидки. Ниже приведен образец заполнения заявления в РСА.
Но она имеет действенные рычаги влияния на СК, поэтому может заставить ее выполнить взятые на себя обязательства перед клиентом. Специально для обращений граждан на сайте РСА есть страница, на которой размещена вся нужная информация. На почту, указанную на этой странице, нужно отправить жалобу. Здесь же размещены актуальные бланки обращений. С копиями документов и заявлением нужно отправиться в инстанцию, в которой придется решать данный вопрос по восстановлению бонуса СК, ЦБ, РСА.
С копиями документов и заявлением нужно отправиться в инстанцию, в которой придется решать данный вопрос по восстановлению бонуса СК, ЦБ, РСА.
Как восстановить кбм в базе рса при смене прав
Итак, водительское удостоверение получено. Но если хотите сохранить при получении очередного , необходимо обратиться в страховую компанию после замены водительского удостоверения, чтобы внести в базу данных РСА серию, номер нового водительского удостоверения. В моём случае в базу данных также надо внести данные нового паспорта РФ. Если не заявить о новых данных до момента, как будете оформлять новый полис ОСАГО, потеряете скидку при оплате полиса. В свете подорожаний полисов в последнее время, думаю, скидка никому не помешает. Самое первое, поискал информацию на сайте страховой компании.
Рса заявление на смену ву
Это значит, что введенные данные где-то хоть в какой-то запятой, хоть в одной цифре отличаются от того, что записано в базе Союза Страховщиков. Откуда вообще берется эта ошибка? Дело в том, что при покупке полиса через агента, агенту позволено ввести любую информацию в базу. Считается, что он — квалифицированный сотрудник.
Откуда вообще берется эта ошибка? Дело в том, что при покупке полиса через агента, агенту позволено ввести любую информацию в базу. Считается, что он — квалифицированный сотрудник.
Со скидками на ОСАГО возникли проблемы — Рамблер/финансы
В Банк России, курирующий рынок автострахования, поступают многочисленные жалобы от автомобилистов о том, что страховые намеренно уклоняются от скидок, не желая терять выручку. Об этом свидетельствует статистика ЦБ за первый квартал 2018 года, сообщает газета «Известия».
Так, за четыре месяца 2018 года регулятор получил 13,4 тыс. жалоб на страховые компании. Наибольшая часть из них касается предусмотренных законом скидок на ОСАГО, которые либо начисляются некорректно, либо не представляются вовсе. По оценкам ЦБ, «коэффициент подлежит исправлению в 90% случаев».
Напомним, льготы высчитываются по методике коэффициентов «бонус-малус» в специальной электронной базе Российского союза автостраховщиков. Представители страховых компаний заявляют, что проблемы со скидками возникают из-за технических ошибок в этой системе. Как пояснил представитель одной из страховых фирм, если ранее в базе РСА были загружены неверные значения коэффициента «бонус-малус» (КБМ) по определенным страхователям, то и ответ на запрос КБМ со стороны РСА будет неверным.
Представители страховых компаний заявляют, что проблемы со скидками возникают из-за технических ошибок в этой системе. Как пояснил представитель одной из страховых фирм, если ранее в базе РСА были загружены неверные значения коэффициента «бонус-малус» (КБМ) по определенным страхователям, то и ответ на запрос КБМ со стороны РСА будет неверным.
Страховщики напомнили, что если клиенты не согласны с расчетом скидки, они могут направить запрос в фирму, в которой намерены заключить договор. «Если компания не находит технической ошибки у себя, она формирует запрос в РСА, в течение пяти рабочих дней союз страховщиков проводит проверку и высылает корректное значение коэффициента или же подтверждение, что коэффициент был верным», — объяснил руководитель Центра контроля качества группы «Ренессанс страхование» Алексей Образцов.
Вторая по популярности жалоба в ЦБ — невозможность заключить договор через интернет. В частности, речь идет о длительном ожидании во время заполнения заявления и сбоях на этапе расчета стоимости полиса и его оплаты.
Напомним, в конце апреля система е-ОСАГО дала сбой из-за блокировок Роскомнадзора. Проблемы были связаны сервисом защиты от спама Google reCAPTCHA, который временно оказался недоступен.
Проверить диагностическую карту техосмотра по базе РСА
Подтверждающим документом и разрешением на легальное передвижение по территории России является выданная оператором технического осмотра диагностическая карта. Ее подлинность гарантирует вам внесение в единую автоматизированную базу ЕАИСТО, что сотрудничает и связана с базой Российского союза автостраховщиков РСА.
Другими словами проверка диагностической карты по базе РСА проходит при использовании данных занесенных в ЕАИСТО. Сама база РСА не имеет сведений о сроках прохождения техосмотра, информации о водителе и транспортном средстве.
Что это за проверка и для чего она нужна
Проверка диагностической карты — это процедура, что выполняется с целью узнать сведения о легальном прохождении техосмотра с соблюдением всех правил и соответствие документа законодательным требованиям.
Надобность данной проверки аргументируется следующим: после покупки транспортного средства, которому более 3-лет, автовладелец должен пройти техосмотр и получить диагностическую карту.
Подтверждающий документ оформленный по правилам даст возможность перейти к следующему шагу — покупки страхового полиса ОСАГО, что является обязательным пунктом.
ОСАГО выдастся тому владельцу автотранспорта, чья диагностическая карта соответствует требованием и занесена в РСА.
Другими словами данная проверка необходима самим автолюбителям для полноценного прохождения всех процедур после приобретения машины. На ее основе вам отказывают либо дают зеленый свет на оформления страхового полиса.
Учитывая человеческий фактор и современную политику компаний и организаций, что выдают диагностические карты, то можно прийти к выводу, что главная цель учреждений — это заработать на вас как можно больше денег.
Организации выдают липовые подтверждающие документы, особо незаморачиваясь с проверкой и устраивают имитирующие процедуры проверки автомобилей на исправность. Эксперты не тратят свое время, возясь воле вашего автомобиля, а вы получаете поддельную диагностическую карту не занесенную в автоматизированные базы, в частности РСА.
Эксперты не тратят свое время, возясь воле вашего автомобиля, а вы получаете поддельную диагностическую карту не занесенную в автоматизированные базы, в частности РСА.
С другой стороны вы оказываетесь обманутыми мошенниками и учреждениями в случае предоставления услуг неаккредитованными организациями. По сути выдававшая вам фирма не имеет доступа к автоматизированной системе РСА и не может заносить в базу данные о проверке.
Поэтому рекомендуется самостоятельно просматривать данную базу и удостовериться о соответствии вашей диагностической карты правилам выдачи и ее легальности, что в свою очередь дает беспрепятственное передвижение по территории Российской Федерации и дальнейшее оформление страхового полиса ОСАГО.
Где выполняется
Проверка ТО осуществляется через базу ЕАИСТО, но проводится непосредственно в системе РСА. Очень часто эти две базы данных совмещают и пишут как одно целое. РСА в себе имеет информацию о полисах ОСАГО, где можно проверить их подлинность и КМБ (коэффициент бонус-малус).
Сам факт и осуществление проверки диагностической карты нужен для дальнейшего оформления полиса ОСАГО. Без легально оформленного подтверждающего документа аккредитованные страховые компании откажут вам в оформлении страхового полиса.
Многие страховые эксперты обобщают и соединяют две базы в единую ЕАИСТО РСА, через которую и проходит проверка на законность выданного вам документа о беспрепятственном передвижении.
Иными словами, если номер вашей диагностической карты не будет найден в базе РСА, то объединение страховщиков оформлять ОСАГО откажется и вам придется выходить из ситуации иными способами.
Как проверить диагностическую карту по базе РСА и данные для проверки
Диагностическая карта – документ, что подтверждает легальность вашего передвижения на дорогах и факт, согласно которому оформляется страховка.
Она пришла на замену старым талонам, и имеет как бумажный так и электронный вид, который заносится в автоматизированную базу.
У каждой выданной карты имеется свой код, хаотический набор цифр, что присваивается после прохождение проверки. Зайдя в электронную базу РСА и введя цифры в соответствующие поля и нажав «поиск в ЕАИСТО» на экране высветится результат проверки системы.
Проверить подлинность документа проще будет по номеру машины. Но результаты проверки могут быть разные.
Если транспортное средство на законных основаниях прошло проверку неисправность комплектующих, то экран выдаст информацию о марке машины и ее модели. Еще вы будете осведомлены о сроках действия диагностической карты.
В случае не прохождение проверки транспортным средством выданная информация будет идентична предыдущей, однако срок подтверждающего документа будет просроченным в прошедшем времени.
В третьем случае вашу карту база РСА может вообще не найти. Есть две причины:
- первая – это вашему транспортному средству менее трех лет и прохождения техосмотра не требуется;
- другая причина – это выданная вам на руки диагностическая карта не легальна и не законна.
Оператор, что выдавал документ, является либо мошенником, либо небрежным работником, который вносил данные с ошибками.
Бывают случаи, когда система не показывает данных о прохождении техосмотра, хотя вы имеете карту лично.
Рекомендуется в базу данных РСА ввести следующие параметры или характеристики транспортного средства, по которым можно отследить документ:
- номер кузова
- отследить по VIN-номеру
- ввести номер Шасси
Когда результата нет, и диагностическую карту не показывает, то необходимо ввести сам номер талона, который находится на другой стороне карты. Проверить диагностическую карту техосмотра по базе РСА онлайн выполнить может любой пользователь ПК без особых навыков.
В любом случае исходов может быть только два. Либо ваша диагностическая карта подлинная и на экране появится вся информация либо система ее не находит.
В этом случае следует обратиться к операторам техосмотра, что выдавали вам подтверждающий документ и вместе решать проблему.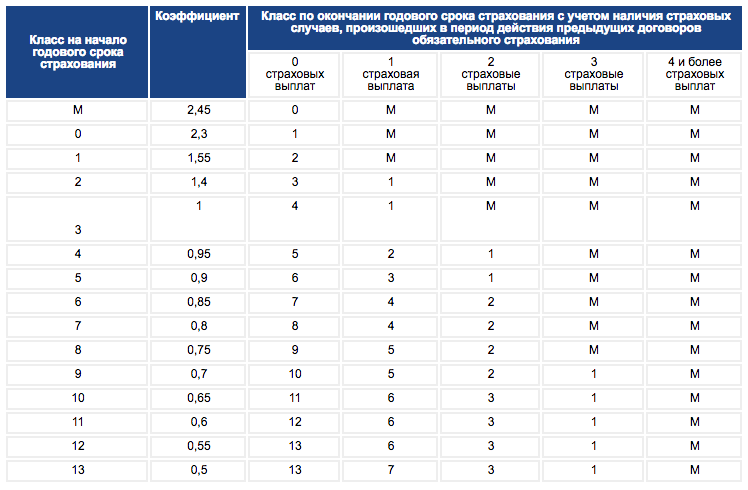
Что делать, если результат проверки отрицательный и его причины
Легально оформленная диагностическая карта — это залог отсутствия проблемных ситуаций с сотрудниками ГИБДД и страховыми компаниями. Все автовладельцы пытаются получить достоверный документ занесенный в базу РСА и сделанный по законной процедуре.
Проверяя карту по базе РСА не все автовладельцы находят там свои данные. Причин, по которым вы стали обладателем поддельного подтверждающего документа может быть несколько, а точнее две:
Первая причина — это прохождение технического осмотра не в аккредитированных пунктах. Ведь сейчас, все учреждения, что выдают диагностические карты проходят утверждения и проверки на наличие современного оборудования и технологий, что разрешает им проверять техническое состояние автомобилей и их неисправностей.
Иными словами вы просто жертва мошенников и неспециализированных фирм, некоторые работают поддельным документам и не имеют доступа к системам автоматизации базы РСА.
Вторая причина — это небрежная работа операторов технического осмотра. Человеческий фактор так же играет роль. Работник центра по невнимательности может неправильно ввести данные вашего транспортного средства после проверки.
В результате чего информация о прохождении технического осмотра в автоматизированной базе РСА будет отсутствовать, а вы будете лишены и не допущены к получению ОСАГО.
Если в результате самостоятельной проверки диагностической карты по базе РСА вами не было выявлено данных, то следует обратиться в тот пункт, где осуществлялась процедура выдачи подтверждающего документа.
Ведь вся ответственность, согласно законодательству Российской Федерации, ложится на плечи экспертов и операторов технического осмотра, что самостоятельно заносят данные о прохождении техосмотра автомобилей в течении 24 часов после успешной процедуры.
РСА или Российский союз автостраховщиков — это автоматизированная база созданная в результате объединения большинства страховых компаний страны в единый информационный портал, главной задачей которого есть сбор всех сведений и данных о прохождении техосмотра автовладельцами своих транспортных средств.
Проверка подлинности диагностической карты осуществляется самостоятельно владельцем авто в результате чего он узнает о законности выданному ему подтверждающему документу.
Осуществление данной процедуры рекомендуется для избежания конфликтных ситуаций во время дорожно-транспортных происшествий, получения ОСАГО и тактичной работы со страховой компанией.
Видео: Что такое диагностическая карта (полезные советы от РДМ-Импорт)
R PCA (анализ основных компонентов)
Анализ основных компонентов (PCA) — полезный метод для исследовательских целей.
анализ данных, позволяющий лучше визуализировать вариации, присутствующие в
набор данных с множеством переменных. Это особенно полезно в случае
«широкие» наборы данных, где у вас есть много переменных для каждой выборки. В этом
учебник, вы откроете для себя PCA в R.![]()
Введение в PCA
Как вы уже читали во введении, PCA особенно удобен, когда вы работаете с «широкими» наборами данных.Но почему так?
Что ж, в таких случаях, когда присутствует много переменных, вы не можете легко построить график данных в их необработанном формате, что затрудняет понимание присутствующих в них тенденций. PCA позволяет вам видеть общую «форму» данных, определяя, какие образцы похожи друг на друга, а какие сильно различаются. Это может позволить нам идентифицировать группы схожих выборок и определить, какие переменные отличают одну группу от другой.
Математика, лежащая в основе этого, довольно сложна, поэтому я не буду вдаваться в подробности, но основы PCA следующие: вы берете набор данных со многими переменными и упрощаете этот набор данных, превращая исходные переменные в меньшие количество «основных компонентов».
Но что это именно? Основные компоненты — это основная структура данных. Это направления, в которых наблюдается наибольшее расхождение, направления, в которых данные наиболее разбросаны. Это означает, что мы пытаемся найти прямую линию, которая лучше всего распространяет данные, когда они проецируются вдоль нее. Это первый главный компонент, прямая линия, показывающая наиболее существенные отклонения в данных.
Это означает, что мы пытаемся найти прямую линию, которая лучше всего распространяет данные, когда они проецируются вдоль нее. Это первый главный компонент, прямая линия, показывающая наиболее существенные отклонения в данных.
PCA — это тип линейного преобразования заданного набора данных, который имеет значения для определенного количества переменных (координат) для определенного количества пробелов.Это линейное преобразование подгоняет этот набор данных к новой системе координат таким образом, что наиболее значительная дисперсия обнаруживается по первой координате, а каждая последующая координата ортогональна последней и имеет меньшую дисперсию. Таким образом, вы преобразуете набор из x коррелированных переменных по y выборкам в набор из p некоррелированных главных компонентов по тем же выборкам.
Если многие переменные коррелируют друг с другом, все они будут вносить значительный вклад в один и тот же главный компонент.Каждый главный компонент суммирует определенный процент от общей вариации в наборе данных. Если ваши исходные переменные сильно коррелированы друг с другом, вы сможете аппроксимировать большую часть сложности в своем наборе данных с помощью всего лишь нескольких основных компонентов. По мере добавления большего количества основных компонентов вы суммируете все больше и больше исходного набора данных. Добавление дополнительных компонентов делает вашу оценку общего набора данных более точной, но при этом более громоздкой.
Если ваши исходные переменные сильно коррелированы друг с другом, вы сможете аппроксимировать большую часть сложности в своем наборе данных с помощью всего лишь нескольких основных компонентов. По мере добавления большего количества основных компонентов вы суммируете все больше и больше исходного набора данных. Добавление дополнительных компонентов делает вашу оценку общего набора данных более точной, но при этом более громоздкой.
Собственные значения и собственные векторы
Как и многие другие вещи в жизни, собственные векторы и собственные значения бывают парами: каждому собственному вектору соответствует собственное значение.Проще говоря, собственный вектор — это направление, такое как «вертикальное» или «45 градусов», а собственное значение — это число, показывающее, насколько велика дисперсия данных в этом направлении. Таким образом, собственный вектор с наивысшим собственным значением является первой главной компонентой.
Так подождите, возможно, в одном наборе данных можно найти больше собственных значений и собственных векторов?
Верно! Количество выходящих собственных значений и собственных векторов равно количеству измерений, которые имеет набор данных. В примере, который вы видели выше, было 2 переменных, поэтому набор данных был двумерным. Это означает, что есть два собственных вектора и собственные значения. Точно так же вы найдете три пары в трехмерном наборе данных.
В примере, который вы видели выше, было 2 переменных, поэтому набор данных был двумерным. Это означает, что есть два собственных вектора и собственные значения. Точно так же вы найдете три пары в трехмерном наборе данных.
Мы можем переформулировать набор данных в терминах этих собственных векторов и собственных значений, не изменяя лежащую в основе информацию. Обратите внимание, что переформатирование набора данных относительно набора собственных значений и собственных векторов не влечет за собой изменения самих данных, вы просто смотрите на них под другим углом, который должен лучше представлять данные.
Теперь, когда вы ознакомились с теорией, лежащей в основе PCA, вы готовы увидеть все это в действии!
Простой PCA
В этом разделе вы опробуете PCA, используя простой и легкий в использовании
понять набор данных. Вы будете использовать набор данных mtcars , который построен
в R. Этот набор данных состоит из данных по 32 моделям автомобилей, взятых из
Американский автомобильный журнал (журнал Motor Trend 1974 г. ). Для каждой машины
у вас есть 11 функций, выраженных в разных единицах (единицах США).
следует:
). Для каждой машины
у вас есть 11 функций, выраженных в разных единицах (единицах США).
следует:
* миль на галлон : Расход топлива (миль на (США) галлон): более мощный и
более тяжелые автомобили, как правило, потребляют больше топлива.
* цилиндр : Количество цилиндров: более мощные автомобили часто имеют больше
цилиндры
* disp : Рабочий объем (куб. Дюйм): общий объем двигателя
цилиндры
* л.с. : Полная мощность: это мера мощности, генерируемой
машина
* drat : Передаточное число заднего моста: здесь описывается поворот приводного вала.
соответствует повороту колес. Более высокие значения уменьшат топливо
эффективность.
* wt : Вес (1000 фунтов): довольно понятно!
* qsec : Время 1/4 мили: скорость и ускорение автомобилей
* против : Блок двигателя: это означает, что двигатель автомобиля
имеет форму буквы «V» или более распространенную прямую форму.
* am : Трансмиссия: это означает, что трансмиссия автомобиля
автоматический (0) или ручной (1).
* шестерня : Количество передних передач: спортивные автомобили, как правило, имеют больше передач.
* карбюратор : Количество карбюраторов: связано с более мощными двигателями
Обратите внимание, что используемые единицы различаются и занимают разные шкалы.
Вычислить основные компоненты
Поскольку PCA лучше всего работает с числовыми данными, вы исключите два
категориальные переменные ( против и и ). У вас осталась матрица из 9
столбцы и 32 строки, которые вы передаете функции prcomp () ,
назначив свой вывод на mtcars.pca . Вы также зададите два аргумента, центр и масштаб , чтобы быть ИСТИНА . Тогда вы можете взглянуть на свой PCA
объект с сводкой () .
mtcars. pca <- prcomp (mtcars [, c (1: 7,10,11)], center = TRUE, scale. = TRUE)
сводка (mtcars.pca)
## Важность компонентов:
## ПК1 ПК2 ПК3 ПК4 ПК5 ПК6
## Стандартное отклонение 2,3782 1,4429 0,71008 0.51481 0,42797 0,35184
## Пропорция дисперсии 0,6284 0,2313 0,05602 0,02945 0,02035 0,01375
## Кумулятивная доля 0,6284 0,8598 0,
pca <- prcomp (mtcars [, c (1: 7,10,11)], center = TRUE, scale. = TRUE)
сводка (mtcars.pca)
## Важность компонентов:
## ПК1 ПК2 ПК3 ПК4 ПК5 ПК6
## Стандартное отклонение 2,3782 1,4429 0,71008 0.51481 0,42797 0,35184
## Пропорция дисперсии 0,6284 0,2313 0,05602 0,02945 0,02035 0,01375
## Кумулятивная доля 0,6284 0,8598 0, 0,94525 0,96560 0,97936
## PC7 PC8 PC9
## Стандартное отклонение 0,32413 0,2419 0,14896
## Доля дисперсии 0,01167 0,0065 0,00247
## Совокупная доля 0,99103 0,9975 1,00000
Вы получаете 9 основных компонентов, которые вы называете PC1-9. Каждый из них
объясняет процент от общей вариации в наборе данных.То есть
скажем: PC1 объясняет 63% общей дисперсии, что означает, что почти две трети информации в наборе данных (9 переменных) могут быть
инкапсулирован только этим одним Основным компонентом. PC2 объясняет 23%
дисперсия. Итак, зная положение образца по отношению к
только ПК1 и ПК2, вы можете получить очень точное представление о том, где он находится
отношения к другим образцам, так как только ПК1 и ПК2 могут объяснить 86%
дисперсия.
Давайте вызовем str () , чтобы взглянуть на ваш объект PCA.
ул. (Mtcars.pca)
## Список из 5
## $ sdev: num [1: 9] 2.378 1.443 0.71 0.515 0.428 ...
## $ Rotation: num [1: 9, 1: 9] -0,393 0,403 0,397 0,367 -0,312 ...
## ..- attr (*, "dimnames") = Список из 2
## .. .. $: chr [1: 9] "mpg" "cyl" "disp" "hp" ...
## .. .. $: chr [1: 9] "ПК1" "ПК2" "ПК3" "ПК4" ...
## $ center: Именованное число [1: 9] 20,09 6,19 230,72 146,69 3,6 ...
## ..- attr (*, "names") = chr [1: 9] "mpg" "cyl" "disp" "hp" ...
## $ scale: Именованное число [1: 9] 6.027 1,786 123,939 68,563 0,535 ...
## ..- attr (*, "names") = chr [1: 9] "mpg" "cyl" "disp" "hp" ...
## $ x: num [1:32, 1: 9] -0,664 -0,637 -2,3 -0,215 1,587 ...
## ..- attr (*, "dimnames") = Список из 2
## .. .. $: chr [1:32] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...
## .. .. $: chr [1: 9] "ПК1" "ПК2" "ПК3" "ПК4" ...
## - attr (*, "класс") = chr "prcomp"
Я не буду здесь подробно описывать результаты, но ваш объект PCA содержит следующую информацию:
- Центральная точка (
$ центр), масштабирование ($ шкала), стандарт отклонение (sdev) каждого главного компонента - Взаимосвязь (корреляция или антикорреляция и т.
 Д.) Между
начальные переменные и главные компоненты (
Д.) Между
начальные переменные и главные компоненты ($ вращение) - Значения каждой выборки по основным компонентам
(
$ x)
Построение PCA
Пришло время построить PCA.Вы сделаете биплот, который включает
положение каждого образца с точки зрения ПК1 и ПК2, а также будет
покажет вам, как исходные переменные отображаются на это. Вы будете использовать ggbiplot пакет, который предлагает удобную и красивую функцию для
сюжетные сюжеты. Сюжет — это тип сюжета, который позволит вам
визуализировать, как образцы соотносятся друг с другом в нашем PCA (который
образцы похожи и которые разные) и будут одновременно
показать, как каждая переменная влияет на каждый главный компонент.
Перед тем, как начать, не забудьте сначала установить ggbiplot !
библиотека (devtools)
install_github ("vqv / ggbiplot")
Затем вы можете позвонить по номеру ggbiplot со своего PCA:
библиотека (ggbiplot)
ggbiplot (mtcars. pca)
pca)
Оси выглядят как стрелки, исходящие из центральной точки. Вот ты
посмотрите, что переменные hp , cyl и disp все вносят вклад в PC1,
с более высокими значениями этих переменных, смещая выборки вправо на
этот сюжет.Это позволяет увидеть, как точки данных соотносятся с осями, но
это не очень информативно, не зная, какая точка соответствует
какой образец (автомобиль).
Вы предоставите аргумент для ggbiplot : давайте дадим ему rownames из mtcars как ярлыков . Это назовет каждую точку именем
рассматриваемый автомобиль:
ggbiplot (mtcars.pca, labels = rownames (mtcars))
Теперь вы можете увидеть, какие автомобили похожи друг на друга.Например, Maserati Bora, Ferrari Dino и Ford Pantera L собираются вместе на вершина. В этом есть смысл, поскольку все это спортивные автомобили.
Как еще вы можете попытаться лучше понять свои данные?
Интерпретация результатов
Может быть, если посмотреть на происхождение каждой из машин. Ты положишь их
в одну из трех категорий (карт?), по одной для США, Японии.
и европейские автомобили. Вы составляете список для этой информации, а затем передаете его
Ты положишь их
в одну из трех категорий (карт?), по одной для США, Японии.
и европейские автомобили. Вы составляете список для этой информации, а затем передаете его группирует аргумент ggbiplot.Вы также установите для аргумента эллипса значение
будет ИСТИНА , при этом каждая группа будет нарисована эллипсом.
mtcars.country <- c (rep («Япония», 3), rep («США», 4), rep («Европа», 7), rep («США», 3), «Europe», rep («Япония», 3), представитель («США», 4), представитель («Европа», 3), «США», представитель («Европа», 3))
ggbiplot (mtcars.pca, ellipse = TRUE, labels = rownames (mtcars), groups = mtcars.country)
Теперь вы видите кое-что интересное: американские автомобили образуют отчетливый
кластер справа.Глядя на топоры, вы видите, что американец
автомобили характеризуются высокими значениями для цил , disp и wt .
Японские автомобили, с другой стороны, характеризуются высокой скоростью миль на галлон. Европейские автомобили находятся несколько посередине и менее плотно собраны, чем
любая группа.
Европейские автомобили находятся несколько посередине и менее плотно собраны, чем
любая группа.
Конечно, у вас есть много основных компонентов, каждый из которых
по-разному отображать исходные переменные. Так же можно спросить ggbiplot для построения графика этих других компонентов, используя аргумент choices .
Давайте посмотрим на PC3 и PC4:
ggbiplot (mtcars.pca, ellipse = TRUE, choices = c (3,4), labels = rownames (mtcars), groups = mtcars.country)
Вы здесь мало что видите, но в этом нет ничего удивительного. ПК3 и ПК4 объяснять очень маленькие проценты от общей вариации, так что это было бы удивительно, если вы обнаружили, что они были очень информативными и разделенными группы или выявленные очевидные закономерности.
Давайте на минутку напомним: выполнив PCA с использованием mtcars набор данных, мы видим четкое разделение между американскими и японскими
автомобили по главному компоненту, который тесно связан с цил., 
disp , wt и миль на галлон .Это дает нам некоторые подсказки на будущее
анализы; если бы мы попытались построить классификационную модель для определения
происхождение автомобиля, эти переменные могут быть полезны.
Графические параметры с
ggbiplot Есть также некоторые другие переменные, с которыми вы можете поиграть, чтобы изменить свой
биплот. Вы можете добавить круг в центр набора данных ( круг аргумент):
ggbiplot (mtcars.pca, ellipse = TRUE, circle = TRUE, labels = rownames (mtcars), groups = mtcars.страна)
Вы также можете масштабировать образцы ( obs.scale ) и переменные
( вар. Масштаб ):
ggbiplot (mtcars.pca, ellipse = TRUE, obs.scale = 1, var.scale = 1, labels = rownames (mtcars), groups = mtcars.country)
Вы также можете полностью удалить стрелки, используя var.. axes
axes
ggbiplot (mtcars.pca, ellipse = TRUE, obs.scale = 1, var.scale = 1, var.axes = FALSE, labels = rownames (mtcars), groups = mtcars.страна)
Настроить
ggbiplot Поскольку ggbiplot основан на функции ggplot , вы можете использовать то же
набор графических параметров для изменения ваших графиков, как и для любого другого gg участок . Здесь вы собираетесь:
Укажите цвета для использования в группах с
scale_colour_manual ()Добавить заголовок с
ggtitle ()Укажите минимальную тему
()Переместите легенду с темой
()
ggbiplot (mtcars.pca, ellipse = TRUE, obs.scale = 1, var.scale = 1, labels = rownames (mtcars), groups = mtcars.country) +
scale_colour_manual (name = "Origin", values = c ("зеленый лес", "красный3", "темно-синий")) +
ggtitle ("PCA набора данных mtcars") +
theme_minimal () +
тема (legend. position = "bottom")
position = "bottom")
Добавление нового образца
Хорошо, допустим, вы хотите добавить новую выборку в свой набор данных. Это особенная машина, с непохожей на другие характеристики. Это сверхмощный, имеет 60-цилиндровый двигатель, потрясающую экономию топлива, отсутствие передач и очень светлый.Это «космический автомобиль» с Юпитера.
Можете ли вы добавить его к существующему набору данных и посмотреть, где он находится? отношение к другим машинам?
Добавьте его к mtcars , создав mtcarsplus , затем повторите
ваш анализ. Вы можете ожидать, что сможете увидеть автомобили в каком регионе
больше всего нравится.
космический автомобиль <- c (1000,60,50,500,0,0,5,2,5,0,1,0,0)
mtcarsplus <- rbind (mtcars, космический автомобиль)
mtcars.countryplus <- c (mtcars.страна "Юпитер")
mtcarsplus.pca <- prcomp (mtcarsplus [, c (1: 7,10,11)], center = TRUE, scale. = TRUE)
ggbiplot (mtcarsplus. pca, obs.scale = 1, var.scale = 1, ellipse = TRUE, circle = FALSE, var.axes = TRUE, labels = c (rownames (mtcars), "spacecar"), groups = mtcars. countryplus) +
scale_colour_manual (name = "Origin", values = c ("зеленый лес", "красный3", "фиолетовый", "темно-синий")) +
ggtitle ("PCA набора данных mtcars, с добавленным дополнительным образцом") +
theme_minimal () +
тема (легенда.position = "bottom")
pca, obs.scale = 1, var.scale = 1, ellipse = TRUE, circle = FALSE, var.axes = TRUE, labels = c (rownames (mtcars), "spacecar"), groups = mtcars. countryplus) +
scale_colour_manual (name = "Origin", values = c ("зеленый лес", "красный3", "фиолетовый", "темно-синий")) +
ggtitle ("PCA набора данных mtcars, с добавленным дополнительным образцом") +
theme_minimal () +
тема (легенда.position = "bottom")
Но это было бы наивным предположением! Изменилась форма СПС.
кардинально, с добавлением этого образца. Когда вы рассматриваете это
приведу немного больше деталей, это действительно имеет смысл. в
исходный набор данных, у вас были сильные корреляции между определенными переменными
(например, цил. и миль на галлон ), которые способствовали PC1, разделяя
ваши группы друг от друга по этой оси.Однако когда вы выполняете
PCA с дополнительной выборкой, таких же корреляций нет,
что искажает весь набор данных. В этом случае эффект особенно заметен. сильный, потому что ваша дополнительная выборка сильно отличается от множества
уважает.
сильный, потому что ваша дополнительная выборка сильно отличается от множества
уважает.
Если вы хотите увидеть, как новый образец сравнивается с группами, созданными начальный PCA, вам нужно спроецировать его на этот PCA.
Спроецировать новый образец на исходный PCA
Это означает, что главные компоненты определены без
относительно вашего образца космического автомобиля , затем вы вычисляете, где космический автомобиль размещены по отношению к другим образцам путем применения преобразований
что ваш PCA произвел.Вы можете думать об этом как о том, что вместо того, чтобы получать
среднее значение всех образцов и позволяя космическому автомобилю исказить это среднее значение,
вы получите среднее значение остальных образцов и посмотрите на космический автомобиль в
отношение к этому.
Это означает, что вы просто масштабируете значения для космического автомобиля в
связь с центром PCA ( mtcars.). Затем вы применяете
поворот матрицы PCA к образцу 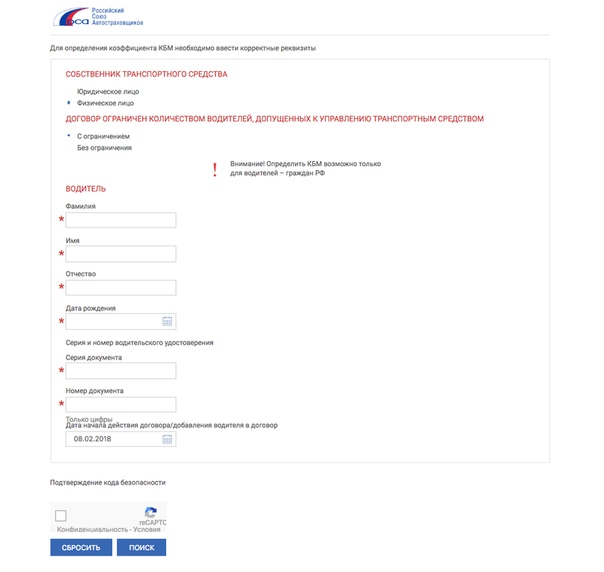 pca $ center
pca $ center КА . Тогда ты можешь rbind () прогнозируемые значения для космического автомобиля для остальных pca $ x матрица и передайте это на ggbiplot , как и раньше:
с.sc <- scale (t (spacecar [c (1: 7,10,11)]), center = mtcars.pca $ center)
s.pred <- s.sc% *% mtcars.pca $ ротация
mtcars.plusproj.pca <- mtcars.pca
mtcars.plusproj.pca $ x <- rbind (mtcars.plusproj.pca $ x, s.pred)
ggbiplot (mtcars.plusproj.pca, obs.scale = 1, var.scale = 1, ellipse = TRUE, circle = FALSE, var.axes = TRUE, labels = c (rownames (mtcars), "spacecar"), groups = mtcars.countryplus) +
scale_colour_manual (name = "Origin", values = c ("зеленый лес", "красный3", "фиолетовый", "темно-синий")) +
ggtitle ("PCA набора данных mtcars, с прогнозируемым дополнительным образцом") +
theme_minimal () +
тема (легенда.position = "bottom")
Этот результат кардинально отличается. Обратите внимание, что все остальные образцы
вернулись на свои исходные позиции, а космический автомобиль
Обратите внимание, что все остальные образцы
вернулись на свои исходные позиции, а космический автомобиль размещен несколько
около середины. Ваш дополнительный образец больше не искажает общий
распределение, но его нельзя отнести к определенной группе.
Но что лучше, проекция или пересчет СПС?
Это отчасти зависит от вопроса, на который вы пытаетесь ответить; в
пересчет показывает, что космический автомобиль является выбросом, прогноз говорит
вы не можете поместить его в одну из существующих групп.Выполнение
оба подхода часто полезны при проведении исследовательского анализа данных с помощью
PCA. Этот тип исследовательского анализа часто является хорошей отправной точкой.
прежде чем углубиться в набор данных. Ваши PCA сообщают вам, какие
переменные отделяют американские автомобили от других, и что космический автомобиль является
выброс в нашем наборе данных. Следующим возможным шагом было бы посмотреть,
отношения справедливы для других автомобилей или чтобы увидеть, как машины группируются по
марки или по типу (спорткары, полноприводные автомобили и т. д.).
д.).
Заключение
Итак, вот оно!
Вы узнали принципы PCA, как создать биплот, как тонко настроить этот график и увидеть два разных метода добавления образцы для анализа PCA. Спасибо за чтение!
Если вы хотите узнать больше о R, пройдите бесплатный курс DataCamp Introduction to R.
Практическое руководство по анализу основных компонентов в R & Python
Обзор
- Изучите широко используемый метод уменьшения размерности, который является анализом главных компонентов ( PCA)
- Извлеките важные факторы из данных с помощью PCA
- Реализация PCA как в R, так и в Python
Введение в PCA
Слишком много чего ни на что не годится!
Представьте себе: вы работаете над крупномасштабным проектом в области науки о данных.Что произойдет, если в данном наборе данных слишком много переменных? Вот несколько возможных ситуаций, с которыми вы можете столкнуться:
- Вы обнаружите, что большинство переменных коррелированы при анализе.
- Вы теряете терпение и решаете запустить модель на всех данных. Это возвращает плохую точность, и вы чувствуете себя ужасно.
- Вы не решаете, что делать
- Вы начинаете придумывать какой-нибудь стратегический метод, чтобы найти несколько важных переменных
Поверьте, справляться с такими ситуациями не так сложно, как кажется.Статистические методы, такие как факторный анализ и анализ главных компонент (PCA), помогают преодолеть такие трудности.
В этом посте я объяснил концепцию PCA. Я постарался сделать объяснение простым и информативным. Для практического понимания я также продемонстрировал использование этой техники в R с интерпретациями.
Примечание: понимание этой концепции требует предварительного знания статистики
Обновление (от 28 июля): ниже добавлен процесс прогнозного моделирования с использованием компонентов PCA в R.
Практическое руководство по анализу основных компонентов в R & Python
Что такое анализ главных компонентов?
Проще говоря, PCA - это метод получения важных переменных (в форме компонентов) из большого набора переменных, доступных в наборе данных. Он извлекает низкоразмерный набор функций, беря проекцию нерелевантных размеров из высокоразмерного набора данных с целью собрать как можно больше информации. С меньшим количеством переменных, получаемых при минимизации потерь информации, визуализация также становится намного более значимой.PCA более полезен при работе с трехмерными данными и выше.
Он извлекает низкоразмерный набор функций, беря проекцию нерелевантных размеров из высокоразмерного набора данных с целью собрать как можно больше информации. С меньшим количеством переменных, получаемых при минимизации потерь информации, визуализация также становится намного более значимой.PCA более полезен при работе с трехмерными данными и выше.
Это всегда выполняется на основе симметричной корреляционной или ковариационной матрицы. Это означает, что матрица должна быть числовой и содержать стандартизованные данные.
Давайте разберемся с этим на примере:
Допустим, у нас есть набор данных размером 300 ( n ) × 50 ( p ). n представляет количество наблюдений, а p представляет количество предикторов. Поскольку у нас большое p = 50, то может быть p (p-1) / 2 графиков рассеяния i.е более 1000 графиков, позволяющих анализировать взаимосвязь переменных. Разве не будет утомительной работой провести исследовательский анализ этих данных?
В этом случае было бы ясным подходом выбрать подмножество предсказателя p (p << 50) , которое захватывает столько же информации. Затем следует нанесение наблюдения в результирующее низкоразмерное пространство.
Затем следует нанесение наблюдения в результирующее низкоразмерное пространство.
На изображении ниже показано преобразование данных высокой размерности (3 измерения) в данные низкой размерности (2 измерения) с помощью PCA.Не забывайте, что каждый результирующий размер представляет собой линейную комбинацию из p функций
Источник: nlpca
Каковы основные компоненты?
Главный компонент - это нормализованная линейная комбинация исходных предикторов в наборе данных. На изображении выше PC1 и PC2 являются основными компонентами. Допустим, у нас есть набор предикторов X¹, X² ..., X p
Главный компонент можно записать как:
Z¹ = Φ¹¹X¹ + Φ²¹X² + Φ³¹X³ +.... + Φ p ¹X p
где,
- Z¹ - первый главный компонент
-
Φ p ¹- вектор нагрузки, состоящий из нагрузок (Φ¹, Φ² .) первого главного компонента. Нагрузки ограничены суммой квадратов, равной 1. Это связано с тем, что большая величина нагрузок может привести к большим отклонениям. Он также определяет направление главного компонента (Z¹), по которому данные изменяются больше всего.В результате получается линия в мерном пространстве p , которая наиболее близка к наблюдениям n . Близость измеряется с помощью среднего квадрата евклидова расстояния. .
. -
X¹..X p- нормализованные предикторы. Нормализованные предикторы имеют среднее значение, равное нулю, и стандартное отклонение, равное единице.
Следовательно,
Первый главный компонент представляет собой линейную комбинацию исходных переменных-предикторов, которая фиксирует максимальную дисперсию в наборе данных.Он определяет направление наибольшей изменчивости данных. Чем больше вариативность, зафиксированная в первом компоненте, тем больше информации, полученной компонентом. Никакой другой компонент не может иметь вариабельность выше, чем первый главный компонент.
Никакой другой компонент не может иметь вариабельность выше, чем первый главный компонент.
Первый главный компонент приводит к строке, которая наиболее близка к данным, то есть минимизирует сумму квадратов расстояния между точкой данных и линией.
Точно так же мы можем вычислить и вторую главную компоненту.
Второй главный компонент ( Z² ) также является линейной комбинацией исходных предикторов, которая фиксирует оставшуюся дисперсию в наборе данных и не коррелирует с Z¹ .Другими словами, корреляция между первым и вторым компонентами должна быть нулевой. Его можно представить как:
Z² = Φ¹²X¹ + Φ²²X² + Φ³²X³ + .... + Φ p2 X p
Если два компонента не коррелированы, их направления должны быть ортогональными (изображение ниже). Это изображение основано на смоделированных данных с двумя предикторами. Обратите внимание на направление компонентов, как и ожидалось, они ортогональны. Это говорит о том, что корреляция ч / б этих компонентов равна нулю.
Это говорит о том, что корреляция ч / б этих компонентов равна нулю.
Все последующие главные компоненты следуют аналогичной концепции, т.е. они фиксируют оставшуюся вариацию без корреляции с предыдущим компонентом. В общем, для размерных данных n × p можно построить главный компонент min ( n-1, p) .
Направления этих компонентов идентифицируются неконтролируемым образом, т.е. переменная отклика (Y) не используется для определения направления компонента. Следовательно, это неконтролируемый подход.
Примечание. Метод методом наименьших квадратов (PLS) - это контролируемая альтернатива PCA. PLS присваивает более высокий вес переменным, которые сильно связаны с переменной ответа, чтобы определить основные компоненты.
Почему в PCA необходима нормализация переменных?
Основные компоненты поставляются с нормализованной версией исходных предикторов. Это потому, что исходные предикторы могут иметь разные масштабы.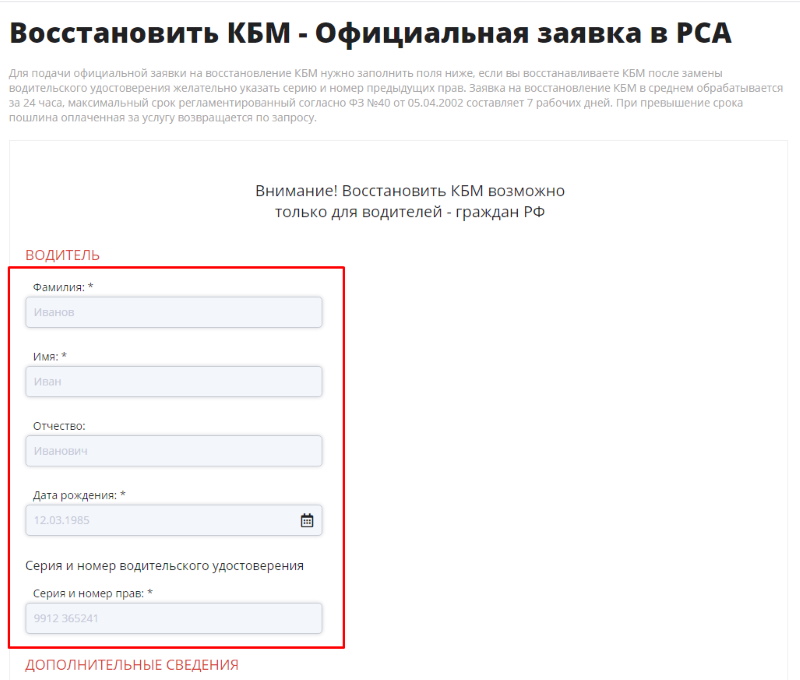 Например: представьте себе набор данных с единицами измерения переменных, такими как галлоны, километры, световые годы и т. Д.Несомненно, что масштаб отклонений этих переменных будет большим.
Например: представьте себе набор данных с единицами измерения переменных, такими как галлоны, километры, световые годы и т. Д.Несомненно, что масштаб отклонений этих переменных будет большим.
Выполнение PCA для ненормализованных переменных приведет к безумно большим нагрузкам для переменных с высокой дисперсией. В свою очередь, это приведет к зависимости главного компонента от переменной с высокой дисперсией. Это нежелательно.
Как показано на изображении ниже, PCA был запущен для набора данных дважды (с немасштабированными и масштабированными предикторами). Этот набор данных содержит ~ 40 переменных. Как видите, в первом основном компоненте преобладает переменная Item_MRP.А во втором основном компоненте преобладает переменная Item_Weight. Это доминирование преобладает из-за высокого значения дисперсии, связанной с переменной. Когда переменные масштабируются, мы получаем гораздо лучшее представление переменных в 2D-пространстве.
Внедрить PCA в R & Python (с интерпретацией)
Сколько основных компонентов выбрать? Я мог бы глубоко погрузиться в теорию, но лучше было бы ответить на эти вопросы практически.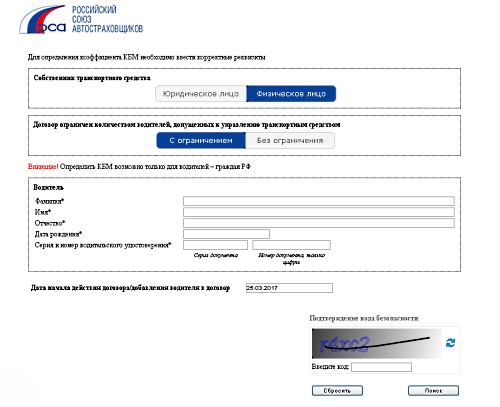
Для этой демонстрации я буду использовать набор данных из Big Mart Prediction Challenge III.
Помните, что PCA может применяться только к числовым данным. Следовательно, если данные содержат категориальные переменные, их необходимо преобразовать в числовые. Кроме того, убедитесь, что вы выполнили базовую очистку данных перед применением этого метода. Давайте быстро закончим с первоначальной загрузкой данных и этапами очистки:
# путь к каталогу
> путь <- "... / Data / Big_Mart_Sales"
# установить рабочий каталог
> setwd (путь)
# загрузить поезд и тестовый файл
> поезд <- прочитать.csv ("train_Big.csv")
> test <- read.csv ("test_Big.csv")
# добавить столбец
> test $ Item_Outlet_Sales <- 1
# объединить набор данных
> combi <- rbind (поезд, тест)
#impute пропущенных значений с помощью медианы
> combi $ Item_Weight [is. na (combi $ Item_Weight)] <- median (combi $ Item_Weight, na.rm = TRUE)
na (combi $ Item_Weight)] <- median (combi $ Item_Weight, na.rm = TRUE)
#impute 0 со средним значением
> combi $ Item_Visibility <- ifelse (combi $ Item_Visibility == 0, median (combi $ Item_Visibility), combi $ Item_Visibility)
#find mode and impute
> таблица (combi $ Outlet_Size, combi $ Outlet_Type)
> уровни (combi $ Outlet_Size) [1] <- «Другое»
До сих пор мы вменяли пропущенные значения.Теперь нам осталось удалить зависимую (ответную) переменную и другие переменные-идентификаторы (если есть). Как мы уже говорили выше, мы практикуем технику обучения без учителя, поэтому переменную ответа необходимо удалить.
# удалить зависимые переменные и переменные идентификатора
> my_data <- subset (combi, select = -c (Item_Outlet_Sales, Item_Identifier, Outlet_Identifier))
Давайте проверим доступные переменные (a.k.a предикторы) в наборе данных.
# проверить доступные переменные
> colnames (my_data)
Поскольку PCA работает с числовыми переменными, давайте посмотрим, есть ли у нас какие-либо другие переменные, кроме числовых.
# проверить класс переменной
> str (my_data)
'data.frame': 14204 набл. из 9 переменных:
$ Item_Weight: num 9,3 5,92 17,5 19,2 8,93 ...
$ Item_Fat_Content: коэффициент с 5 уровнями "LF", "low fat" ,..: 3 5 3 5 3 5 5 3 5 5 ...
$ Item_Visibility: число 0,016 0,0193 0,0168 0,054 0,054 ...
$ Item_Type: Фактор с 16 уровнями «Выпечка», ..: 5 15 11 7 10 1 14 14 6 6 ...
$ Item_MRP: число 249,8 48,3 141,6 182,1 53,9 ...
$ Outlet_Establishment_Year: int 1999 2009 1999 1998 1987 2009 1987 1985 2002 2007 ...
$ Outlet_Size: множитель с 4 уровнями "Другой", "Высокий", .  .: 3 3 3 1 2 3 2 3 1 1 ...
.: 3 3 3 1 2 3 2 3 1 1 ...
$ Outlet_Location_Type: Фактор с 3 уровнями "Уровень 1", "Уровень 2 ",..: 1 3 1 3 3 3 3 3 2 2 ...
$ Outlet_Type: Фактор с 4 уровнями "Продуктовый магазин", ..: 2 3 2 1 2 3 2 4 2 2 ...
К сожалению, 6 из 9 переменных имеют категориальный характер. Теперь у нас есть дополнительная работа. Мы преобразуем эти категориальные переменные в числовые, используя одну горячую кодировку.
# загрузить библиотеку
> библиотека (макеты)
# создать фиктивный фрейм данных
> new_my_data <- dummy.data.frame (my_data, names = c («Item_Fat_Content», «Item_Type»,
«Outlet_Establishment_Year», «Outlet_Size»,
«Outlet_Location_Type», «Outlet_Type»)
Чтобы проверить, есть ли у нас теперь набор данных с целочисленными значениями, просто напишите:
# проверить набор данных
> str (new_my_data)
И теперь у нас есть все числовые значения. Разделим данные на тестовые и обучающие.
Разделим данные на тестовые и обучающие.
# разделить новые данные
> pca.train <- new_my_data [1: nrow (train),]
> pca.test <- new_my_data [- (1: nrow (train)),]
Теперь мы можем продолжить PCA.
Базовая функция R prcomp () используется для выполнения PCA. По умолчанию он центрирует переменную так, чтобы среднее значение было равно нулю. Со шкалой параметра . = T , мы нормализуем переменные, чтобы стандартное отклонение было равно 1.
#principal component analysis
> prin_comp <- prcomp (pca.поезд, масштаб. = T)
> имена (prin_comp)
[1] "sdev" "вращение" "центр" "масштаб" "x"
Функция prcomp () дает 5 полезных мер:
1. центр и шкала относится к соответствующему среднему значению и стандартному отклонению переменных, которые используются для нормализации до внедрения PCA
# выводит среднее значение переменных
prin_comp $ center
# выводит стандартное отклонение переменных
prin_comp $ scale
2. Мера вращения обеспечивает загрузку главного компонента. Каждый столбец матрицы вращения содержит вектор нагрузки главного компонента. Это самая важная мера, которая должна нас заинтересовать.
Мера вращения обеспечивает загрузку главного компонента. Каждый столбец матрицы вращения содержит вектор нагрузки главного компонента. Это самая важная мера, которая должна нас заинтересовать.
> prin_comp $ вращение
Возвращает 44 нагрузки основных компонентов. Это правильно ? Абсолютно. В наборе данных максимальное количество загрузок основных компонентов составляет минимум (n-1, p). Давайте посмотрим на первые 4 основных компонента и первые 5 строк.
> prin_comp $ вращение [1: 5,1: 4]
PC1 PC2 PC3 PC4
Item_Weight 0.0054429225 -0.001285666 0.011246194 0.011887106
Item_Fat_ContentLF -0.002198330.00 -0.00166894 -03314 -0.00166894 -03314 -0.0021983314 -00 -0.003066415 -0.018396143
Item_Fat_ContentLow Fat 0.0027936467 -0,002234328 0,028309811 0,056822747
Item_Fat_Contentreg 0,0002936319 0,001120931 0,0054 -0,001026615
3. Чтобы вычислить вектор оценки главного компонента, нам не нужно умножать нагрузку на данные. Скорее, матрица x имеет векторы оценок главных компонентов в измерении 8523 × 44.
Чтобы вычислить вектор оценки главного компонента, нам не нужно умножать нагрузку на данные. Скорее, матрица x имеет векторы оценок главных компонентов в измерении 8523 × 44.
> тусклый (prin_comp $ x)
[1] 8523 44
Построим основные компоненты, полученные в результате.
> двумерный график (prin_comp, scale = 0)
Параметр scale = 0 обеспечивает масштабирование стрелок для представления нагрузок.Чтобы сделать вывод из изображения выше, сосредоточьтесь на крайних концах (вверху, внизу, слева, справа) этого графика.
Мы делаем вывод, что первый главный компонент соответствует измерению Outlet_TypeSupermarket, Outlet_Establishment_Year 2007. Точно так же можно сказать, что второй компонент соответствует измерению Outlet_Location_TypeTier1, Outlet_Sizeother. Для точного измерения переменной в компоненте вам следует снова взглянуть на матрицу вращения (выше).
4. Функция prcomp () также предоставляет возможность вычислять стандартное отклонение каждого главного компонента. 2
2
# проверить дисперсию первых 10 компонентов
> pr_var [1:10]
[1] 4.563615 3.217702 2.744726 2.541091 2.198152 2.015320 1.932076 1.256831
[9] 1.203791 1.168101
Мы стремимся найти компоненты, которые объясняют максимальную дисперсию. Это потому, что мы хотим сохранить как можно больше информации с помощью этих компонентов. Таким образом, чем выше объясненная дисперсия, тем выше будет информация, содержащаяся в этих компонентах.
Чтобы вычислить долю дисперсии, объясняемую каждым компонентом, мы просто делим дисперсию на сумму общей дисперсии. Результат:
# объясненная пропорция дисперсии
> prop_varex <- pr_var / sum (pr_var)
> prop_varex [1:20]
[1] 0,10371853 0,07312958 0,06238014 0,05775207 0,04995800 0,04580433 900 0,04580433 900 0,04995800 0,04580433 900 0,04580274 0,02735888 0,02654774 0,02559876 0,02556797
[13] 0. 02549516 0,02508831 0,02493932 0,024
02549516 0,02508831 0,02493932 0,024 0,02468313 0,02446016
[19] 0,023 0,02371118
Это показывает, что первый главный компонент объясняет отклонение в 10,3%. Второй компонент объясняет отклонение в 7,3%. Третий компонент объясняет отклонение в 6,2% и так далее. Итак, как нам решить, сколько компонентов выбрать для этапа моделирования?
Ответ на этот вопрос дает осыпная делянка. График осыпи используется для доступа к компонентам или факторам, которые объясняют наибольшую изменчивость данных.Он представляет значения в порядке убывания.
#scree plot
> plot (prop_varex, xlab = "Main Component",
ylab = "Proportion of Variance Explained",
type = "b")
График выше показывает, что ~ 30 компонентов объясняют примерно 98,4% отклонения в наборе данных. Другими словами, с помощью PCA мы сократили 44 предиктора до 30 без ущерба для объясненной дисперсии. В этом сила PCA> Давайте проведем подтверждающую проверку, построив график кумулятивной дисперсии.Это даст нам четкое представление о количестве компонентов.
В этом сила PCA> Давайте проведем подтверждающую проверку, построив график кумулятивной дисперсии.Это даст нам четкое представление о количестве компонентов.
# кумулятивный график осыпи
> график (cumsum (prop_varex), xlab = "Главный компонент",
ylab = "Суммарная доля объясненной дисперсии",
type = "b")
Этот график показывает, что 30 компонентов приводят к дисперсии, близкой к ~ 98%. Поэтому в этом случае мы выберем количество компонентов 30 [ПК1 - ПК30] и перейдем к этапу моделирования.На этом шаги по внедрению PCA для данных поездов завершены. Для моделирования мы будем использовать эти 30 компонентов в качестве переменных-предикторов и следовать обычным процедурам.
Прогнозное моделирование с компонентами PCA
После того, как мы выполнили PCA на обучающей выборке, давайте теперь разберемся в процессе прогнозирования тестовых данных с использованием этих компонентов. Процесс прост. Так же, как мы получили компоненты PCA на обучающем наборе, мы получим еще один набор компонентов на тестовом наборе.Наконец, обучаем модель.
Процесс прост. Так же, как мы получили компоненты PCA на обучающем наборе, мы получим еще один набор компонентов на тестовом наборе.Наконец, обучаем модель.
Но несколько важных моментов для понимания:
- Не следует комбинировать поезд и набор тестов для получения компонентов PCA всех данных сразу. Потому что это нарушило бы все предположение об обобщении, поскольку тестовые данные «просочились» в обучающую выборку. Другими словами, набор тестовых данных больше не останется «невидимым». В конце концов, это снизит способность модели к обобщению.
- Мы не должны выполнять PCA на тестовых и обучающих наборах данных отдельно.Потому что результирующие векторы из обучающего и тестового PCA будут иметь разные направления (из-за неравной дисперсии). Из-за этого мы в конечном итоге сравним данные, зарегистрированные по разным осям. Следовательно, результирующие векторы из данных поездов и испытаний должны иметь одинаковые оси.
Итак, что нам делать?
Мы должны выполнить точно такое же преобразование с тестовым набором, что и с обучающим набором, включая функцию центра и масштабирования. Сделаем это за R:
Сделаем это за R:
# добавить обучающий набор с основными компонентами
> train.data <- data.frame (Item_Outlet_Sales = train $ Item_Outlet_Sales, prin_comp $ x)
# нас интересуют первые 30 PCA
> train.data <- train.data [, 1: 31]
# запустить дерево решений
> install.packages ("rpart")
> library (rpart)
> rpart.model <- rpart (Item_Outlet_Sales ~., Data = train.data, method = "anova")
> rpart.model
# преобразовать тест в PCA
> test.данные <- предсказать (prin_comp, newdata = pca.test)
> test.data <- as.data.frame (test.data)
# выберите первые 30 компонентов
> test.data <- test.data [, 1: 30]
# сделать прогноз на основе тестовых данных
> rpart.prediction <- предсказать (rpart. model, test.data)
model, test.data)
# Для удовольствия, наконец, проверьте свои результаты в таблице лидеров
> sample <- read.csv ("SampleSubmission_TmnO39y.csv ")
> final.sub <- data.frame (Item_Identifier = sample $ Item_Identifier, Outlet_Identifier = sample $ Outlet_Identifier, Item_Outlet_Sales = rpart.prediction)
> write.csv (final.sub," pca.sub ", row.names = F)
Это полный процесс моделирования после извлечения PCA. Я уверен, что вы не будете довольны своим рейтингом в таблице лидеров после того, как загрузите решение. Попробуйте использовать случайный лес!
Для пользователей Python: Чтобы реализовать PCA в Python, просто импортируйте PCA из библиотеки sklearn.Интерпретация остается такой же, как объяснено выше для пользователей R. Конечно, результат получается таким же, как после использования R. Набор данных, используемый для Python, представляет собой очищенную версию, в которой были вменены недостающие значения, а категориальные переменные преобразованы в числовые. Процесс моделирования остается таким же, как описано выше для пользователей R.
Процесс моделирования остается таким же, как описано выше для пользователей R.
import numpy as np
from sklearn.decomposition import PCA
import pandas as pd
import matplotlib.pyplot as plt
из sklearn.preprocessing import scale
% matplotlib inline
# Загрузить набор данных
data = pd.read_csv ('Big_Mart_PCA.csv')
# преобразовать в массивы numpy
X = data.values
# Масштабирование значений
X = масштаб (X)
pca = PCA (n_components = 44)
шт. Подходит (X)
# Количество отклонений, которые объясняет каждый компьютер
var = pca.объясненное_вариантное соотношение_
# Кумулятивная дисперсия объясняет
var1 = np. cumsum (np.round (pca.explained_variance_ratio_, decimals = 4) * 100)
cumsum (np.round (pca.explained_variance_ratio_, decimals = 4) * 100)
печать var1
[10,37 17,68 23,92 29,7 34,7 39,28 43,67 46,53 49,27
51,92 54,48 57,04 59,59 62,1 64,59 67,08 69,55 72.
74,39 76,76 79,1 81,44 83,77609 88,39 88,3976 96,78 98,44 100.01 100.01 100.01 100.01 100.01 100.01
100.01 100.01 100.01 100.01 100.01 100.01 100.01 100.01]
участок (вар1 )
# Глядя на график выше, я беру 30 переменных
pca = PCA (n_components = 30)
pca.fit (X)
X1 = pca.fit_transform (X)
печать X1
Для получения дополнительной информации о PCA в python посетите scikit learn documentation.
Важные моменты для PCA
- PCA используется для преодоления избыточности функций в наборе данных.
- Эти элементы имеют низкую размерность.
- Эти функции, также известные как компоненты, являются результатом нормализованной линейной комбинации исходных переменных-предикторов.
- Эти компоненты стремятся собрать как можно больше информации с высокой степенью объясненной вариативности.
- Первый компонент имеет наибольшую дисперсию, за ним следуют второй, третий и так далее.
- Компоненты не должны быть коррелированы (помните ортогональное направление?). См. Выше.
- Нормализация данных становится чрезвычайно важной, когда предикторы измеряются в разных единицах.
- PCA лучше всего работает с набором данных, имеющим 3 или более размерности. Потому что с более высокими измерениями становится все труднее интерпретировать полученное облако данных.
- PCA применяется к набору данных с числовыми переменными.
- PCA - это инструмент, который помогает улучшить визуализацию данных большой размерности.
Конечные ноты
На этом я подошел к концу этого урока. Не углубляясь в математику, я попытался познакомить вас с наиболее важными концепциями, необходимыми для использования этой техники. Это просто, но требует особого внимания при выборе количества компонентов. На практике мы должны стремиться сохранить только несколько первых k компонентов
Не углубляясь в математику, я попытался познакомить вас с наиболее важными концепциями, необходимыми для использования этой техники. Это просто, но требует особого внимания при выборе количества компонентов. На практике мы должны стремиться сохранить только несколько первых k компонентов
Идея, лежащая в основе pca, состоит в том, чтобы построить некоторые основные компоненты (Z << Xp), которые удовлетворительно объясняют большую часть изменчивости данных, а также взаимосвязь с переменной ответа.
Вам понравилась эта статья? Вы поняли эту технику? Делитесь своими предложениями / мнениями в разделе комментариев ниже.
Вы можете проверить свои навыки и знания. Посмотрите Live
Competitions и соревнуйтесь с лучшими специалистами по данным со всего мира. СвязанныеАнализ главных компонентов (PCA) 101 с использованием R | Питер Ниструп
Итак, теперь мы немного понимаем, как работает PCA, и этого должно быть достаточно на данный момент. Давайте на самом деле попробуем:
Давайте на самом деле попробуем:
wdbc.pr <- prcomp (wdbc [c (3:32)], center = TRUE, scale = TRUE)
summary (wdbc.pr)
Это довольно понятно, Функция ' prcomp ' запускает PCA для данных, которые мы ей предоставляем, в нашем случае это ' wdbc [c (3:32)] ', которые являются нашими данными, за исключением переменных идентификатора и диагностики, затем мы говорим R центрировать и масштабируйте наши данные (таким образом, стандартизирует данных). Наконец, мы вызываем сводку:
Значения первых 10 основных компонентовНапомним, что свойство PCA состоит в том, что наши компоненты отсортированы от наибольшего к наименьшему с учетом их стандартного отклонения ( собственных значений ).Итак, давайте разберемся с этим:
- Стандартное отклонение: В нашем случае это просто собственные значения , поскольку данные были центрированы и масштабированы ( стандартизованный )
- Пропорция дисперсии : Это величина отклонения, которую компонент учитывает в данных, т.
 Е. PC1 составляет > 44% от общей дисперсии только данных!
Е. PC1 составляет > 44% от общей дисперсии только данных! - Совокупная доля : Это просто накопленная величина объясненной дисперсии, т. Е.если бы мы использовали первых 10 компонентов , мы смогли бы учесть > 95% общей дисперсии данных.
Верно, так сколько компонентов нам нужно? Мы, очевидно, хотим иметь возможность объяснить как можно больше отклонений, но для этого нам потребуются все 30 компонентов, в то же время мы хотим уменьшить количество измерений, поэтому мы определенно хотим меньше 30!
Поскольку мы стандартизировали наших данных и теперь у нас есть соответствующие собственные значения каждого ПК, мы можем использовать их, чтобы провести для нас границу.Поскольку собственных значений <1 означало бы, что компонент на самом деле объясняет менее одной объясняющей переменной, мы бы хотели их отбросить. Если наши данные хорошо подходят для PCA , мы сможем отбросить эти компоненты, сохранив при этом не менее 70–80% совокупной дисперсии .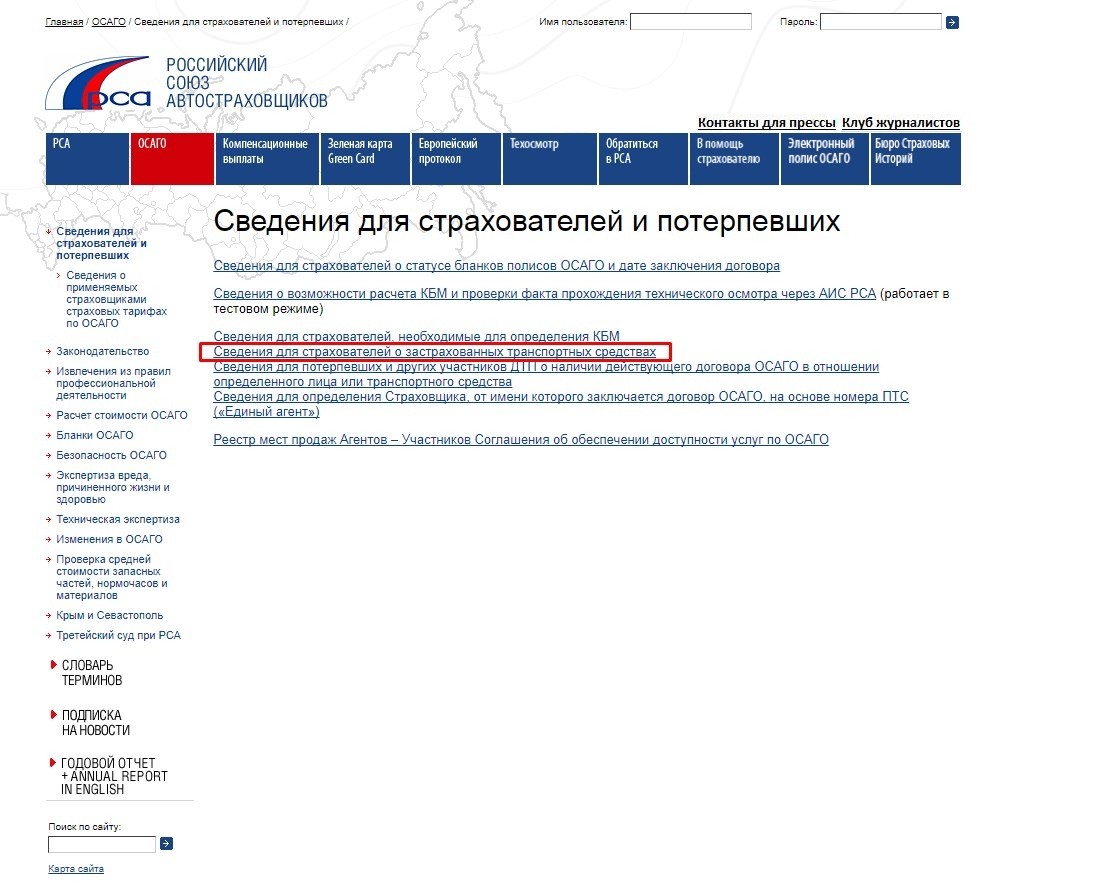 Давайте построим и посмотрим:
Давайте построим и посмотрим:
screeplot (wdbc.pr, type = "l", npcs = 15, main = "Screeplot of the first 10 PC")График собственных значений первых 15 ПК ( слева, ) и График совокупной дисперсии (справа)
abline (h = 1, col = "red", lty = 5 )
legend ("topright", legend = c ("Eigenvalue = 1"),
col = c ("red"), lty = 5, cex = 0.2))
график (cumpro [0:15], xlab = "PC #", ylab = "Сумма объясненной дисперсии", main = "График совокупной дисперсии")
abline (v = 6, col = "blue", lty = 5)
abline (h = 0,88759, col = "blue", lty = 5)
legend ("topleft", legend = c ("Cut-off @ PC6"),
col = c ("blue") , lty = 5, cex = 0,6)
Мы замечаем, что первые 6 компонентов имеют собственное значение > 1 и объясняет почти 90% отклонения , это здорово! Мы можем эффективно уменьшить размерность с 30 до 6 , «потеряв» лишь около 10% дисперсии!
Мы также замечаем, что на самом деле можем объяснить более 60% дисперсии только первыми двумя компонентами. Попробуем построить следующие графики:
Попробуем построить следующие графики:
plot (wdbc.pr $ x [, 1], wdbc.pr $ x [, 2], xlab = "PC1 (44,3%)", ylab = "PC2 (19%)", main = "PC1 / PC2 - plot")
Хорошо, это не слишком показательно, но на мгновение подумайте, что это представляет 60% + дисперсии в 30-мерном наборе данных. Но что мы из этого видим? Кластеризация происходит в верхнем / среднем правом углу . Давайте также на мгновение задумаемся, какова на самом деле цель этого анализа. Мы хотим объяснить разницу между злокачественными опухолями и доброкачественными опухолями.Давайте на самом деле добавим к графику переменную ответа (диагноз , ) и посмотрим, сможем ли мы лучше разобраться в этом:
библиотека ("factoextra")
fviz_pca_ind (wdbc.pr, geom.ind = "point", pointshape = 21,
pointsize = 2,
fill.ind = wdbc $ диагностика,
col.ind = "black",
palette = "jco",
addEllipses = TRUE,
label = "var",
col. var = "черный",
var = "черный",
repl = TRUE,
legend.title = "Diagnosis") +
ggtitle ("2D PCA-график из набора данных 30 объектов") +
theme (plot.title = element_text (hjust = 0.5)) По сути, это тот же самый график с некоторыми причудливыми эллипсами и цветами, соответствующими диагнозу объекта, и теперь мы видим красоту PCA . С помощью только первых двух компонентов мы можем четко увидеть некоторое разделение между доброкачественными опухолями и злокачественными опухолями . Это явный признак того, что данные хорошо подходят для некоторой модели классификации (например, дискриминантного анализа ).
Анализ главных компонентов в R: prcomp vs princomp - Статьи
В этом руководстве R описывается, как выполнить анализ основных компонентов ( PCA ) с использованием встроенных функций R prcomp () и princomp ().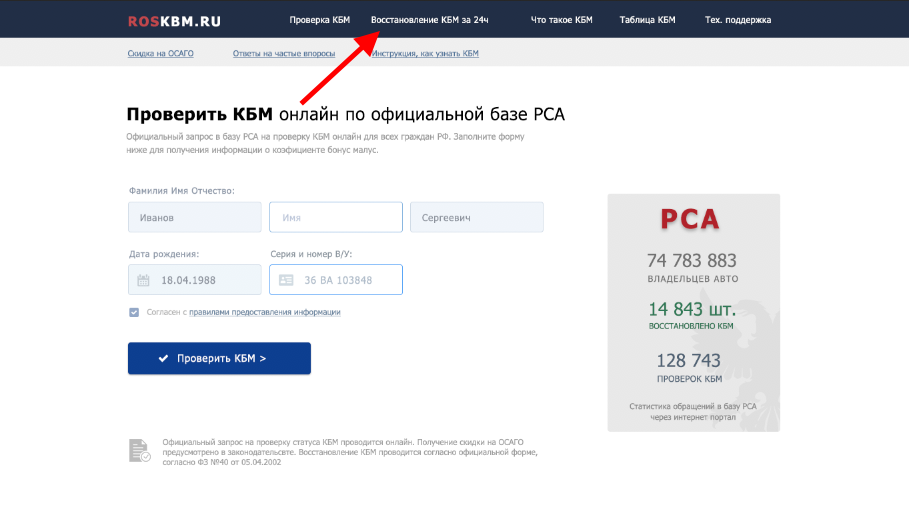 Вы узнаете, как предсказать координаты новых особей и переменных с помощью PCA. Мы также расскажем о теории, лежащей в основе результатов PCA .
Вы узнаете, как предсказать координаты новых особей и переменных с помощью PCA. Мы также расскажем о теории, лежащей в основе результатов PCA .
Узнайте больше об основах и интерпретации анализа главных компонентов в нашей предыдущей статье: PCA - Основы анализа главных компонентов.
В комплекте:
Связанная книга:
Практическое руководство по методам главных компонентов в R
Общие методы анализа главных компонент
Существует два основных метода выполнения PCA в R:
- Спектральное разложение , которое исследует ковариации / корреляции между переменными
- Разложение по сингулярным числам , которое исследует ковариации / корреляции между людьми
Функция princomp () использует подход спектрального разложения.Функции prcomp () и PCA () [FactoMineR] используют разложение по сингулярным числам (SVD).
Согласно справке R, SVD имеет немного лучшую числовую точность. Следовательно, функция prcomp () предпочтительнее princomp ().
Функции prcomp () и princomp ()
Упрощенный формат этих 2 функций:
prcomp (x, scale = FALSE)
princomp (x, cor = FALSE, scores = TRUE) - Аргументы для prcomp ():
-
x: числовая матрица или фрейм данных -
Масштаб: логическое значение, указывающее, должны ли переменные масштабироваться, чтобы иметь единичную дисперсию до того, как начнется анализ
- Аргументы для princomp ():
-
x: числовая матрица или фрейм данных -
cor: логическое значение.Если TRUE, данные будут центрированы и масштабированы перед анализом. -
баллов: логическое значение. Если TRUE, координаты каждой главной компоненты вычисляются
Элементы выходных данных, возвращаемых функциями prcomp () и princomp (), включают:
| sdev | sdev | стандартные отклонения основных компонентов |
| вращение | загрузки | матрица переменных нагрузок (столбцы - собственные векторы) |
| центр | центр | переменная означает (означает, что было вычтено) |
| масштаб | масштаб | стандартные отклонения переменных (масштабирование, примененное к каждой переменной) |
| х | балла | Координаты особей (наблюдений) по основным компонентам. |
В следующих разделах мы сосредоточимся только на функции prcomp ()
Пакет для визуализации PCA
Мы будем использовать пакет factoextra R для создания элегантной визуализации на основе ggplot2.
- Устанавливать из CRAN:
install.packages ("factoextra") - Или установите последнюю версию для разработки с github:
если (! Require (devtools)) установить.пакеты ("инструменты разработчика")
devtools :: install_github ("kassambara / factoextra") - Факты загрузки, как показано ниже:
библиотека (factoextra) Наборы демонстрационных данных
Мы будем использовать наборы данных decathlon2 [фактически экстра], которые уже были описаны в: PCA - Формат данных.
Вкратце, содержит:
- Активные лица (строки с 1 по 23) и активные переменные (столбцы с 1 по 10), которые используются для выполнения анализа главных компонентов
- Дополнительные индивиды (строки с 24 по 27) и дополнительные переменные (столбцы с 11 по 13), координаты которых будут предсказаны с использованием информации PCA и параметров, полученных с активными индивидами / переменными.

Загрузить данные и извлечь только активных лиц и переменные:
библиотека ("factoextra")
данные (decathlon2)
decathlon2.active ## X100 м. Прыжок в длину, выстрел, прыжок в высоту X400 м, прыжок в длину 110 м.
## SEBRLE 11,0 7,58 14,8 2,07 49,8 14,7
## ГЛИНА 10,8 7,40 14,3 1,86 49,4 14,1
## БЕРНАРД 11,0 7,23 14,2 1,92 48,9 15,0
## ЮРКОВ 11,3 7.09 15,2 2,10 50,4 15,3
## ZSIVOCZKY 11,1 7,30 13,5 2,01 48,6 14,2
## МакМуллен 10,8 7,31 13,8 2,13 49,9 14,4 Вычислить PCA в R с помощью prcomp ()
В этом разделе мы предоставим простой в использовании код R для вычисления и визуализации PCA в R с помощью функции prcomp () и пакета factoextra.
- Загрузить фактоэкстракцию для визуализации
библиотека (factoextra) - Вычислить PCA
рез.PCA - Визуализируйте собственных значений (график осыпи ).
 Покажите процент отклонений, объясняемых каждым главным компонентом.
Покажите процент отклонений, объясняемых каждым главным компонентом.
fviz_eig (res.pca) - График лиц. Лица с похожим профилем группируются вместе.
fviz_pca_ind (res.pca,
col.ind = "cos2", # Цвет по качеству представления
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
) - График переменных.Положительно коррелированные переменные указывают на одну и ту же сторону графика. Отрицательные коррелированные переменные указывают на противоположные стороны графика.
fviz_pca_var (res.pca,
col.var = "contrib", # Раскрашиваем по вкладам в ПК
gradient.cols = c ("# 00AFBB", "# E7B800", "# FC4E07"),
Repel = TRUE # Избегать перекрытия текста
) - Двойной график индивидов и переменных
fviz_pca_biplot (рез. pca, Repel = ИСТИНА,
col.var = "# 2E9FDF", # Цвет переменных
col.ind = "# 696969" # Цвет отдельных лиц
)
pca, Repel = ИСТИНА,
col.var = "# 2E9FDF", # Цвет переменных
col.ind = "# 696969" # Цвет отдельных лиц
) Доступ к результатам PCA
библиотека (factoextra)
# Собственные значения
eig.val Прогнозирование с использованием PCA
В этом разделе мы покажем, как предсказать координаты дополнительных индивидов и переменных, используя только информацию, предоставленную ранее выполненным PCA.
Дополнительные лица
- Данные: строки с 24 по 27 и столбцы с 1 по 10 [в наборах данных decathlon2]. Новые данные должны содержать столбцы (переменные) с такими же именами и в том же порядке, что и активные данные, используемые для вычисления PCA.
# Данные дополнительных лиц
инд. ## X100 м. Прыжок в длину, выстрел, прыжок в высоту X400 м, прыжок в длину 110 м.
## КАРПОВ 11,0 7,30 14,8 2,04 48,4 14,1
## ПРЕДУПРЕЖДЕНИЯ 11. 1 7,60 14,3 1,98 48,7 14,2
## Nool 10,8 7,53 14,3 1,88 48,8 14,8
## Дрюс 10,9 7,38 13,1 1,88 48,5 14,0
1 7,60 14,3 1,98 48,7 14,2
## Nool 10,8 7,53 14,3 1,88 48,8 14,8
## Дрюс 10,9 7,38 13,1 1,88 48,5 14,0 - Предсказание координат новых данных лиц. Используйте базовую функцию R прогнозируйте ():
инд. Координата ## PC1 PC2 PC3 PC4
## КАРПОВ 0,777 -0,762 1,597 1,686
## WARNERS -0,378 0,119 1,701 -0,691
## Нет -0.547 -1,934 0,472 -2,228
## Дрюс -1,085 -0,017 2,982 -1,501 - График лиц, включая дополнительных:
№ Участок активных лиц
п Прогнозируемые координаты людей можно рассчитать вручную следующим образом:
- Центрирование и масштабирование данных новых лиц с использованием центра и масштаба PCA
- Вычислите прогнозируемые координаты, умножив масштабированные значения на собственные векторы (нагрузки) главных компонентов.
Можно использовать приведенный ниже код R:
# Центрирование и масштабирование дополнительных лиц
инд. масштаб
масштаб ## PC1 PC2 PC3 PC4
## КАРПОВ 0,777 -0,762 1,597 1,686
## WARNERS -0,378 0,119 1,701 -0,691
## Nool -0,547 -1,934 0,472 -2,228
## Дрюс -1,085 -0,017 2,982 -1,501 Дополнительные переменные
Качественные / категориальные переменные
Наборы данных decathlon2 содержат дополнительную качественную переменную в столбцах 13, соответствующих типу соревнований.
Качественные / категориальные переменные могут использоваться для окраски людей по группам. Группирующая переменная должна иметь ту же длину, что и количество активных людей (здесь 23).
группы Вычислить координаты уровней группирующих переменных. Координаты для данной группы рассчитываются как средние координаты отдельных лиц в группе.
библиотека (magrittr) # для трубы%>%
library (dplyr) # все остальное
№1.Индивидуальные координаты
res.ind%
as_data_frame ()%>%
выберите (Dim.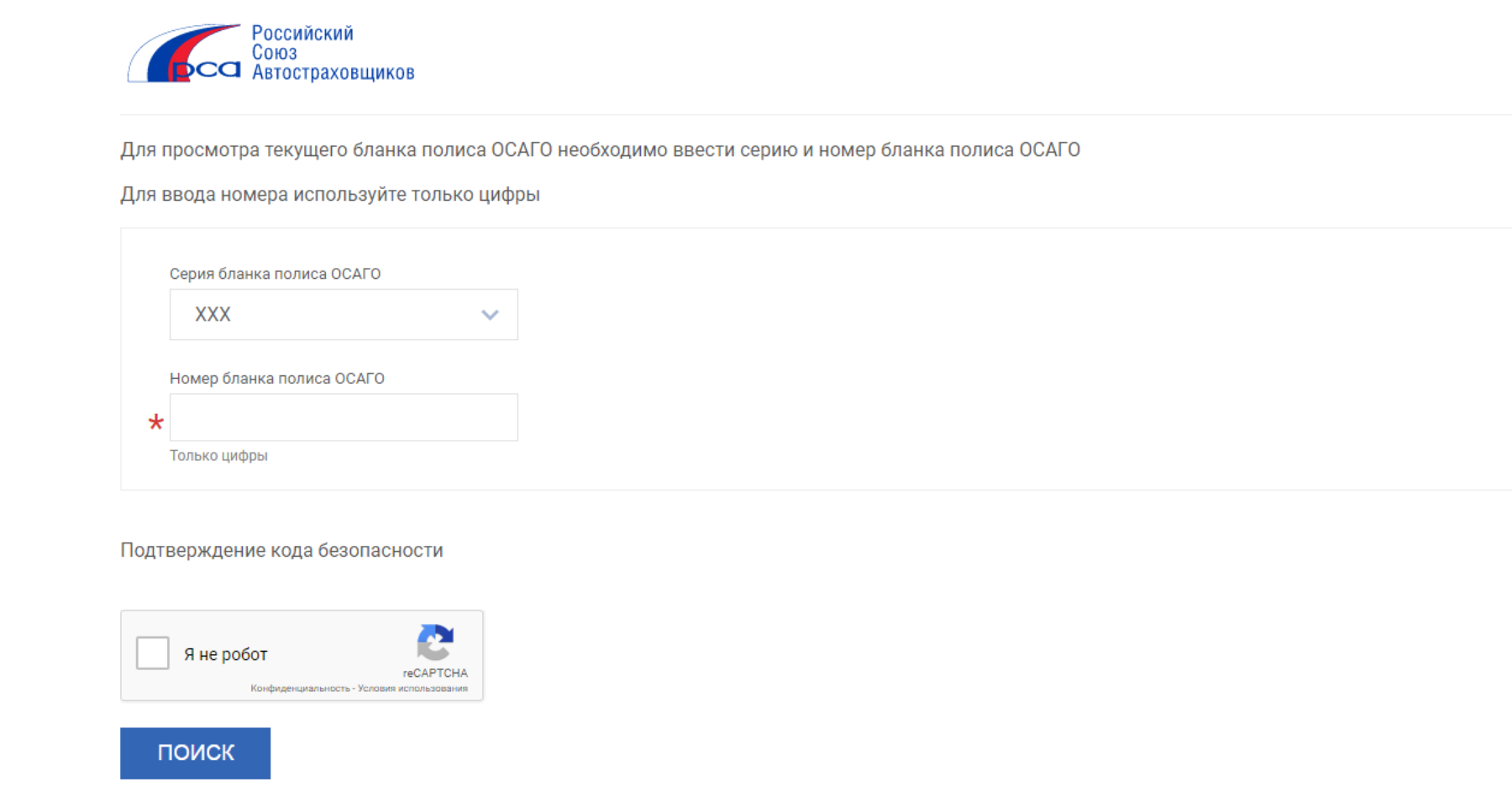 1, Dim.2)%>%
изменить (конкуренция = группы)%>%
group_by (конкуренция)%>%
суммировать(
Разм.1 = среднее (Разм.1),
Разм.2 = среднее (Разм.2)
)
Координаторы группы
1, Dim.2)%>%
изменить (конкуренция = группы)%>%
group_by (конкуренция)%>%
суммировать(
Разм.1 = среднее (Разм.1),
Разм.2 = среднее (Разм.2)
)
Координаторы группы ## # Стол: 2 x 3
## соревнование Разм.1 Разм.2
##
## 1 Декастар -1,31 -0,119
## 2 OlympicG 1,20 0,109 Количественные переменные
Данные: столбцы 11:12. Должен быть такой же длины, как количество активных лиц (здесь 23)
кванти.sup ## Ранг Очки
## SEBRLE 1 8217
## ГЛИНА 2 8122
## BERNARD 4 8067
## ЮРКОВ 5 8036
## ZSIVOCZKY 7 8004
## МакМуллен 8 7995 Координаты данной количественной переменной вычисляются как корреляция между количественными переменными и главными компонентами.
# Прогнозировать координаты и вычислить cos2
quanti.coord Теория результатов PCA
Результаты PCA для переменных
Здесь мы покажем, как вычислить результаты PCA для переменных: координаты, cos2 и вклады:
-
вар. 2
2 -
var.contrib. Вклад переменной в заданный главный компонент равен (в процентах): (var.cos2 * 100) / (общий cos2 компонента)
# Вспомогательная функция
# ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
var_coord_func ## PC1 PC2 PC3 PC4
## X100m -0,851 0,1794 -0,302 0,0336
## Long.jump 0,794 -0,2809 0,191 -0,1154
## Shot.put 0,734 -0,0854 -0,518 0,1285
## High.jump 0.610 0,4652 -0,330 0,1446
## X400m -0,702 -0,2902 -0,284 0,4308
## X110m.hurdle -0,764 0,0247 -0,449 -0,0169 # Вычислить Cos2
# ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
var.cos2 ## PC1 PC2 PC3 PC4
## X100m 0,724 0,032184 0,0909 0,001127
## Long.jump 0,631 0,078881 0,0363 0,013315
## Выстрел 0,539 0,007294 0,2679 0,016504
## High.jump 0,372 0,216424 0,1090 0,020895
## X400m 0,492 0.084203 0,0804 0,185611
## X110м. Препятствие 0,584 0,000612 0.2015 0,000285 # Вычислить вклады
# ::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
comp. cos2
cos2 ## PC1 PC2 PC3 PC4
## X100m 17,54 1,7505 7,34 0,1376
## Long.jump 15,29 4,2904 2,93 1,6249
## Выстрел 13,06 0,3967 21,62 2,0141
## High.jump 9,02 11,7716 8,79 2,5499
## X400m 11,94 4,5799 6,49 22,6509
## X110м. Барьер 14,16 0,0333 16,26 0.2). Обратите внимание, что сумма всех вкладов в столбце составляет 100
# Координаты лиц
# ::::::::::::::::::::::::::::::::::
ind.coord
## PC1 PC2 PC3 PC4
## SEBRLE 0,191 -1,554 -0,628 0,0821
## ГЛИНА 0,790 -2,420 1,357 1,2698
## БЕРНАРД -1,329 -1,612 -0,196 -1,9209
## ЮРКОВ -0,869 0,433 -2,474 0,6972
## ZSIVOCZKY -0,106 2,023 1,305 -0,0993
## МакМуллен 0,119 0,992 0,844 1,3122
# Cos2 лиц
# :::::::::::::::::::::::::::::::::
№1.квадрат расстояния между человеком и
# Центр тяжести PCA
центр
## PC1 PC2 PC3 PC4
## SEBRLE 0,00753 0,4975 0,08133 0,00139
## ГЛИНА 0,04870 0,4570 0,14363 0,12579
## БЕРНАРД 0,19720 0,2900 0,00429 0,41182
## ЮРКОВ 0,09611 0,0238 0,77823 0,06181
## ZSIVOCZKY 0,00157 0,5764 0,23975 0,00139
## МакМуллен 0,00218 0,1522 0,11014 0,26649
№ Вклады физических лиц
# :::::::::::::::::::::::::::::::
contrib
## PC1 PC2 PC3 PC4
## СБРЕЛЬ 0. 0385 5,712 1,385 0,0357
## ГЛИНА 0,6581 13,854 6,460 8,5557
## БЕРНАРД 1,8627 6,144 0,135 19,5783
## ЮРКОВ 0,7969 0,443 21,476 2,5794
## ZSIVOCZKY 0,0118 9,682 5,975 0,0523
## МакМуллен 0,0148 2,325 2,497 9,1353
0385 5,712 1,385 0,0357
## ГЛИНА 0,6581 13,854 6,460 8,5557
## БЕРНАРД 1,8627 6,144 0,135 19,5783
## ЮРКОВ 0,7969 0,443 21,476 2,5794
## ZSIVOCZKY 0,0118 9,682 5,975 0,0523
## МакМуллен 0,0148 2,325 2,497 9,1353
FactoMineR: PCA
Мы используем здесь пример данных десятиборья, которые относятся к
выступление спортсменов на двух спортивных встречах.
Здесь вы можете загрузить набор данных в виде текстового файла.
Представление данных
Набор данных состоит из 41 строки и 13 столбцов.
Столбцы с 1 по 12 являются непрерывными переменными: первые десять столбцов
соответствуют выступлениям спортсменов в 10 видах соревнований.
десятиборье, а столбцы 11 и 12 соответствуют рангу
и полученные баллы. Последний столбец - категориальная переменная.
соответствующий спортивному соревнованию (Олимпийские игры 2004 г. или 2004 г.
Декастар).
нажмите, чтобы просмотреть
Для загрузки пакета FactoMineR и набор данных напишите следующий код строки: библиотека (FactoMineR)
данные (decathlon)
Цели
PCA позволяет описывать набор данных, резюмировать набор данных,
уменьшить размерность.
Мы хотим выполнить PCA для всех данных
набор для ответа на несколько вопросов:
- Индивидуальное исследование (исследование спортсменов): два
спортсмены будут рядом друг с другом, если их результаты на соревнованиях
Закрыть. Мы хотим видеть различия между людьми. Являются
там
сходства между людьми по всем переменным? Можем мы
установить разные профили людей?
Можем ли мы противостоять группе лиц
к другому?
- Исследование переменных (исследование выступлений): Мы хотим
чтобы увидеть, есть ли линейные
отношения между переменными.Две цели сводятся к следующему.
корреляционная матрица и искать синтетические переменные: можем ли мы
возобновить выступление спортсмена по небольшому количеству переменных?
- Связь между этими двумя исследованиями: можем ли мы
охарактеризовать группы лиц переменными?
PCA
Мы собираемся изучить профили спортсменов по их
только выступления. Таким образом, активными переменными будут только те, которые
касаются десяти видов десятиборья.
Остальные переменные ( «Ранг» , «Очки» и "Competition" ) не относятся к этому
профили спортсменов и использовать информацию, уже предоставленную другими
переменные (в случае «Ранг» и «Очки» )
но интересно сопоставить их с главными составляющими.Мы
будет использовать их как дополнительные переменные.
Здесь переменные измеряются в разных единицах. У нас есть
масштабировать их, чтобы дать одинаковое влияние каждому
один.
Активные индивиды и переменные
Мы вводим следующий линейный код для выполнения PCA на всех
частные лица, используя только активные переменные, т.е. первая десятка: res.pca =
PCA (decathlon [, 1:10], scale.unit = TRUE, ncp = 5, graph = T) #decathlon: набор данных
использовал
#scale.unit: выбрать масштабировать данные или нет
#ncp: количество измерений, сохраняемых в результате
#graph: выбрать, отображать ли графики или нет
нажмите, чтобы просмотреть
Первые два измерения восстанавливают 50% общей инерции (
инерция - это общая дисперсия набора данных , т. е. след
корреляционная матрица).
е. след
корреляционная матрица).
Переменная "X100m" коррелирована
отрицательно к переменной "long.jump" . Когда
ahtlete выполняет короткое время при беге на 100 м, он
может прыгнуть на большое расстояние.Здесь нужно быть осторожным, потому что низкое значение
для переменных "X100m" , "X400m" , "X110м. Барьер" и "X1500м" означает высокий балл: чем короче бегает спортсмен, тем больше он
оценки.
Первая ось противостоит спортсменам, которые «везде хороши», как
Карпов во время Олимпиады между теми, кому «везде плохо»
как Бургиньон во время Декастара. Это измерение особенно
связаны с переменными скоростью и прыжком в длину, которые составляют
однородная группа.
Вторая ось противостоит сильным спортсменам (переменные «Дискус» и "Shot.put" ) между теми, кого нет.
Переменные «Discus» , «Shot.put» и "High.jump" мало коррелируют с
переменные "X100m" , "X400m" , "X110м.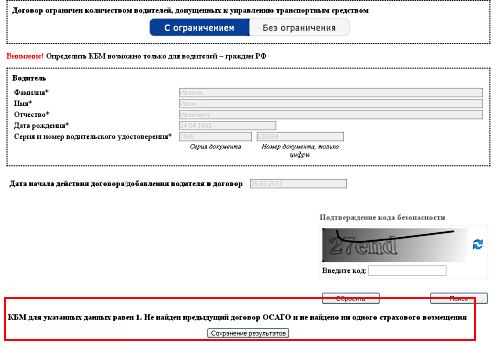 Барьер" и "Длинный прыжок" .
Это означает, что сила не сильно зависит от скорости.
Барьер" и "Длинный прыжок" .
Это означает, что сила не сильно зависит от скорости.
В конце этого первого подхода мы можем разделить факториал
план на четыре части: быстрые и сильные спортсмены (например, Себрле), медленные
спортсмены (например, Casarsa), быстрые, но слабые спортсмены (например, Warner) и медленные
и слабые (условно говоря!) спортсмены (вроде Лоренцо).
дополнительные переменные
Дополнительные переменные имеют
не влияет на основные компоненты анализа. Они есть
собираюсь помочь интерпретировать измерения изменчивости.
Мы можем добавлять два разных типа переменных: непрерывные.
и категоричные.
В качестве дополнительных непрерывных переменных мы хотели бы добавить
переменные «Ранг» и «Очки» .
Набираем следующий код строки: res.pca
= PCA (десятиборье [, 1:12], масштаб.unit = TRUE, ncp = 5, quanti.sup = c (11:12), graph = T) # десятиборье:
набор данных использовал
# scale. unit: чтобы выбрать, масштабировать данные или нет.
unit: чтобы выбрать, масштабировать данные или нет.
#ncp: количество измерений, сохраняемых в результате
# quanti.sup: вектор индексов количественного дополнительного
переменные
#graph: выбрать, строить графики или нет
нажмите для просмотра
Победителями десятиборья считаются те, кто набрал больше всего (или
тех, чей ранг низкий).
Переменные, наиболее связанные с количеством баллов, - это переменные
которые относятся к скорости ( "X100m" , "X110m.препятствие ", "X400м" ) и прыжок в длину. Напротив, "Прыжок с шестом" и "X1500m" не имеют большого влияния на
количество баллов. Спортсмены, которые сильны в этих двух видах спорта, не
одобренный.
В качестве дополнительной категориальной переменной мы добавляем переменную
«Соревнование»: res.pca =
PCA (десятиборье, scale.unit = TRUE, ncp = 5, quanti.sup = c (11:12),
quali.sup = 13, graph = T) #decathlon: использованный набор данных
# scale. unit: для выбора масштабирования данных или нет
unit: для выбора масштабирования данных или нет
#ncp: количество измерений, сохраняемых в результате
#quanti.sup: вектор показателей количественной дополнительной
переменные
# quali.sup: вектор показателей качественной дополнительной
переменные
#graph: выбрать, строить графики или нет
Центры тяжести категорий этого нового
переменная появляется
на графике лиц. Они расположены в барицентре
люди, которые их взяли, и они представляют собой средний
физическое лицо.
Мы также можем раскрасить людей по центрам категорий
гравитации: участка.PCA (res.pca,
axes = c (1, 2), choix = "ind", habillage = 13) # res.pca: результат PCA
#axes: оси для построения
#choix: график для построения ("ind «для физических лиц», «вар» для
переменные)
#habillage: выбирать цвета особей: нет цвета
(«нет»), цвет для каждого человека («инд») или чтобы раскрасить
лиц в соответствии с категориальной переменной (укажите количество
качественная переменная)
нажмите для просмотра
Если смотреть на точки, представляющие «Декастар» и «Олимпийские игры» , мы замечаем, что эта последняя
имеет более высокие координаты на первой оси, чем на первой. Это показывает
эволюция выступлений спортсменов. Все спортсмены, которые
участвовали в двух соревнованиях тогда немного лучше
результаты для
Олимпийские игры.
Это показывает
эволюция выступлений спортсменов. Все спортсмены, которые
участвовали в двух соревнованиях тогда немного лучше
результаты для
Олимпийские игры.
Однако нет разницы между точками «Декастар» и «Олимпийские игры», для второй оси. Этот
означает, что спортсмены улучшили свои показатели, но не
сменить профиль (кроме Zsivoczky, который перешел от медленного к сильному
во время Декастара на быстрый и слабый во время Олимпийских игр).
Мы видим, что точки, которые представляют одного и того же человека
в том же направлении. Например, у Sebrle хорошие результаты и в том, и в другом.
соревнования, но точка, которая представляет его выступление во время
О.Г. более экстремальный. Себрле набрал больше очков во время O.G. чем
во время Декастара.
Можно сделать две интерпретации:
- Спортсмены, участвующие в O.G. лучше
чем те, кто участвует в Decastar
- Спортсмены стараются изо всех сил для O.Г. (подробнее
мотивирован, более подготовлен)
Функция dimdesc () позволяет
опишите размеры.
Мы можем описать размеры, задаваемые переменными, записав: dimdesc (res.pca, axes = c (1,2)) # res.pca: результат
PCA
#axes: выбранные оси
нажмите для просмотра
Функция dimdesc () вычисляет
коэффициент корреляции между переменной и измерением и выполняет
тест значимости.
Эти таблицы дают соотношение
коэффициент и p-значение
переменных, которые существенно коррелируют с главным
Габаритные размеры. Как активные, так и дополнительные переменные, p-значение которых равно
меньше 0,05.
Таблицы описания двух главных осей показывают
что переменные "Точки" и "Long.jump" наиболее коррелируют с первым измерением и "Discus" наиболее коррелирует со вторым. Это подтверждает наш первый
интерпретация.
Эта функция очень полезна в условиях, когда есть много
переменных и позволяет упростить интерпретацию.
Если мы не хотим, чтобы один (или несколько)
участвовать в анализе, есть возможность добавить его как
дополнительный человек. Он не будет активен в анализе, но
принесет дополнительную информацию.
Он не будет активен в анализе, но
принесет дополнительную информацию.
Чтобы добавить дополнительных лиц, используйте следующий аргумент PCA
функция: инд.
Все подробные результаты можно найти в рез.pca .
Мы можем получить
собственные значения, результаты активного
и дополнительные лица, результаты активных переменных и
результаты
категориальные и непрерывные дополнительные переменные, набрав: res.pca имена (res.pca) res.pca $ eig, res.pca $ ind,
res.pca $ ind.sup, res.pca $ var, res.pca $ quali.sup, res.pca $ quanti.sup
Пройти дальше
В большинстве СПП вес особей равен
1 / (количество особей).Однако иногда необходимо дать
удельный вес для некоторых лиц.
Для этого пользователю нужно будет использовать аргумент: row.w
Также может быть интересно присвоить конкретный вес некоторым
переменные.
Здесь пользователь должен использовать аргумент: col. w
w
Проверить, соответствуют ли категории дополнительной переменной
существенно отличаются друг от друга, мы можем вызвать доверие
эллипсы вокруг них.
Для этого введите: plotellipses (res.pca)
Нажмите
для просмотра
Установка PCA Base или HF не отражается в таблице SI_VERSION.
Задача
NFX6231: Установка PCA Base или HF не отражается в таблице SI_VERSION.
Признак
Таблица SI_VERSION содержит информацию о текущей версии продукта, установленного в системе.
Сообщение об ошибке В случае базовой установки PCA
- таблица SI_VERSION не содержит записи об установке
В случае HF-установки PCA
- таблица SI_VERSION содержит информацию о предыдущей HF или базе.
Решение проблемы
В случае установки PCA Base или HF загрузка данных заводских настроек обновляет таблицу SI_VERSION.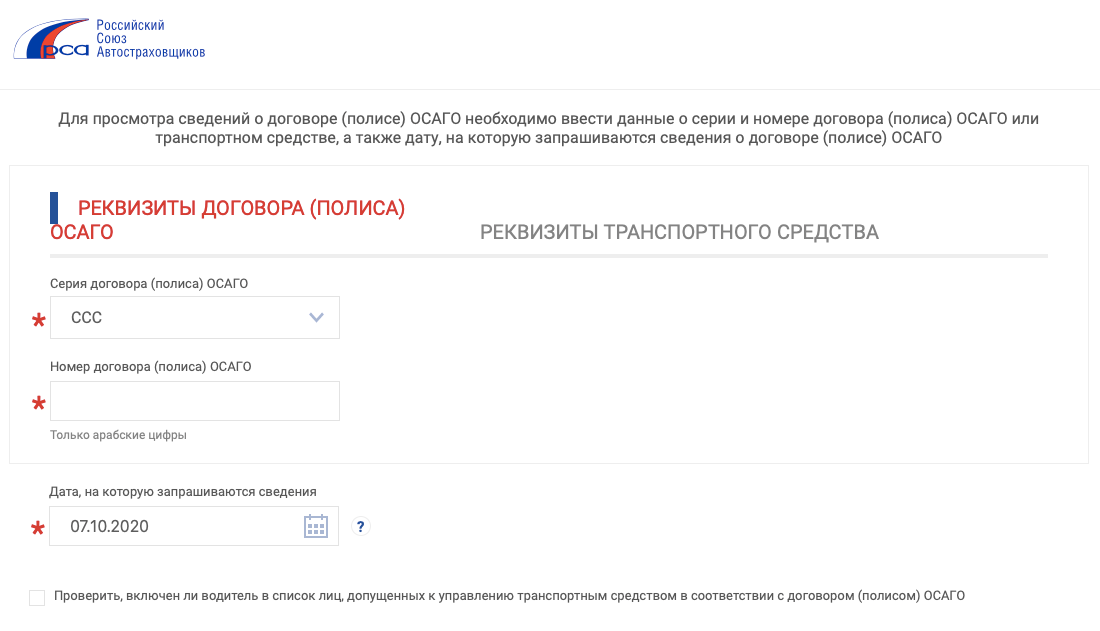
Со следующими свойствами, установленными в /properties/sandbox.cfg -
REINIT_DB = true
NO_DBVERIFY = false и
- 3 true только после действия имеет место -
Это не загружает данные PCA.В документации (Руководство по установке для соответствующего PCA) упоминаются шаги, которые необходимо выполнить для загрузки данных PCA.
В случае установки HF также необходимо запустить целевой "migrate "
Например. Если вы устанавливаете COM PCA HF, вам также необходимо выполнить следующие действия из COM_Hot_Fix_Installation.txt -
Перейдите в COMHFInstaller / bin и выполните следующую команду - ant.sh -f COM80_HFInstall.xml migrateCOM
Это загружает данные заводской настройки из HF, а также обновляет таблицу SI_VERSION.
Если таблица SI_VERSION все еще не обновлена, выполните следующие действия:
Перейдите в / database / hf-factorysetup / ycd
Удалите все файлы . restart из подпапок ycd ( find. -name * .restart -exec rm {} \; - Эта команда интерактивно удалит все файлы .restart из подпапок ycd)
restart из подпапок ycd ( find. -name * .restart -exec rm {} \; - Эта команда интерактивно удалит все файлы .restart из подпапок ycd)
Перейдите в папку, в которую вы извлекли файлы Hf.
Отредактируйте файл COM_InstallableComps.properties
Измените свойство COM_INSTALLED_HF и установите для него значение 0 (ноль)
Снова запустите целевой migrateCOM.
В случае, если кто-то желает обновить таблицу SI_VERSION в одном из следующих сценариев:
- Без выполнения миграции данных для всех HF
- Непосредственно из
вместо извлеченного каталога Hf
Допущение:
Установка HF для COM PCA
Фон:
В случае COM PCA COM_Add-In обновляет таблицу SI_VERSION.Однако возможно, что не каждый COM-PCA HF содержит обновление для COM_Add-In. В такой ситуации таблица SI_VERSION не отражает правильную информацию о версии.
Решение:
1. Убедитесь, что файл SI_VERSION.xml в
Убедитесь, что файл SI_VERSION.xml в / installed_data / COM_Add-In-HF / files / database / hf-factorysetup / ycd / addin содержит правильную информацию об установленном HF.
Например, если установлен COM-PCA Hf54, то содержимое SI_VERSION.xml должен иметь следующий вид:
2. cd / bin
3. Выполните команду:
./loadDefaults.sh ../installed_data/COM_Add-In-HF / files / database / hf-factorysetup / ycd / install / ycd_addin_installer80_HF <последний HF перед текущим HF>.xml ../installed_data/COM_Add-In-HF/files/database/hf-factorysetup/ycd/addin
Это должно обновить таблицу SI_VERSION. Проверьте это либо через базу данных, либо через /logs/migrator_statistics. log. Этот процесс является обычным независимо от установленного или обновленного PCA.
log. Этот процесс является обычным независимо от установленного или обновленного PCA.
[{"Продукт": {"код": "SS6QYM", "ярлык": "Sterling Selling and Fulfillment Suite"}, "Бизнес-подразделение": {"код": "BU055", "ярлык": "Когнитивные приложения") }, «Компонент»: «Неприменимо», «Платформа»: [{«код»: «PF025», «ярлык»: «Независимость от платформы»}], «Версия»: «Все», «Редакция»: «» , "Направление деятельности": {"code": "", "label": ""}}]
Как читать биплоты PCA и диаграммы осыпи
Анализ главных компонентов (PCA) набирает популярность как инструмент для выявления сильных закономерностей из сложных наборов биологических данных.Мы ответили на вопрос «Что такое СПС?» в этом посте в блоге без жаргона - просмотрите его, чтобы получить простое объяснение того, как работает PCA. Вкратце, PCA отражает суть данных в нескольких основных компонентах, которые передают наибольшее разнообразие в наборе данных.
Рис. 1. График PCA . О том, как это читать, читайте в этой записи блога
. PCA не отбрасывает никаких образцов или характеристик (переменных). Вместо этого он уменьшает подавляющее количество измерений за счет создания основных компонентов (ПК).Компьютеры описывают вариации и учитывают различное влияние исходных характеристик. Такие влияния или нагрузки можно проследить по графику PCA, чтобы выяснить, что вызывает различия между кластерами.
Рис. 2. График нагрузки
Видите, как эти векторы закреплены в начале ПК (ПК1 = 0 и ПК2 = 0)? Стоимость их проектов на каждом ПК показывает, какой вес они имеют на этом ПК. В этом примере NPC2 и CHIT1 сильно влияют на PC1, в то время как GBA и LCAT имеют большее влияние на PC2.
Еще одна приятная вещь о графиках загрузки: углы между векторами говорят нам, как характеристики коррелируют друг с другом. Давайте посмотрим на рисунок 2.
- Когда два вектора близки и образуют небольшой угол, две переменные, которые они представляют, положительно коррелируют. Пример: APOD и PSAP
- Если они встречаются под углом 90 °, они вряд ли будут коррелированы. Пример: NPC2 и GBA.
- Когда они расходятся и образуют большой угол (близкий к 180 °), они отрицательно коррелированы.Пример: NPC2 и MAG.
Теперь, когда вы все это знаете, прочитать биплот PCA совсем несложно.
Рис. 3. Слот платы PCA
Вы, вероятно, заметили, что биплот PCA просто объединяет обычный график PCA с графиком нагрузок. Расположение такое:
- Нижняя ось: оценка PC1.
- Левая ось: оценка PC2.
- Верхняя ось: нагрузки на ПК1.
- Правая ось: нагрузки на ПК2.
Другими словами, левая и нижняя оси относятся к графику PCA - используйте их для считывания оценок PCA образцов (точки).Верхняя и правая оси относятся к графику нагрузки - используйте их, чтобы узнать, насколько сильно каждая характеристика (вектор) влияет на основные компоненты.
С другой стороны, осыпь - это диагностический инструмент, позволяющий проверить, хорошо ли работает PCA с вашими данными. Основные компоненты создаются в порядке охвата их вариаций: ПК1 фиксирует наибольшее количество вариаций, ПК2 - второе место и т. Д. Каждый из них вносит некоторую информацию о данных, и в PCA есть столько основных компонентов, сколько и характеристик.Оставляя ПК, мы теряем информацию.
Рис. 4. График осыпи PCA
Хорошая новость в том, что если первые два или три компьютера захватили большую часть информации, то мы можем игнорировать остальную информацию, не теряя ничего важного. График на осыпях показывает, сколько вариаций улавливает каждый компьютер из данных. Ось y - это собственные значения, которые, по сути, обозначают величину вариации. Используйте график на осыпях, чтобы выбрать основные компоненты, которые необходимо сохранить. Идеальная кривая должна быть крутой, затем изгибаться в «локте» - это ваша точка отсечки - и после этого плавиться.На рисунке 4 достаточно ПК 1,2 и 3 для описания данных.
Чтобы справиться с не очень идеальной кривой графика осыпи, есть несколько способов:
- Правило Кайзера: выбирайте ПК с собственными значениями не менее 1.
- График пропорции дисперсии: выбранные ПК должны уметь описывать не менее 80% дисперсии.
Если у вас будет слишком много основных компонентов (более 3), PCA может оказаться не лучшим способом визуализировать ваши данные. Вместо этого рассмотрите другие методы уменьшения размерности, такие как t-SNE и MDS.
Вкратце: Двухуровневый график PCA показывает как оценки ПК для выборок (точки), так и загрузки переменных (векторы). Чем дальше эти векторы находятся от компьютера-источника, тем большее влияние они оказывают на этот компьютер. Графики загрузки также намекают на то, как переменные коррелируют друг с другом: малый угол означает положительную корреляцию, большой - отрицательную корреляцию, а угол 90 ° указывает на отсутствие корреляции между двумя характеристиками. График на осыпях показывает, сколько вариаций улавливает каждый главный компонент из данных.Если первых двух или трех ПК достаточно для описания сути данных, осыпной график представляет собой крутой кривой, которая быстро изгибается и сглаживается.
Ищете способ легко создавать биплоты PCA и диаграммы осыпи? Попробуйте BioVinci, программу перетаскивания, которая может запускать PCA и строить все, как никто другой, всего за несколько щелчков мышью.
Посмотрите короткое видео о том, как быстро запустить PCA с BioVinci:
.