


Контактор 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ)
Главная >Низковольтное оборудование >Контакторы >Магнитный пускатель, контактор перемен. тока (AC) >EATON >Контактор 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON (#511084)
| Наименование | Наличие | Цена
опт с НДС |
Дата обновления |
Добавить в корзину |
Срок поставки |
|---|---|---|---|---|---|
| Контактор DILM25-10 (230В 50Гц/240В 60Гц) EATON 277132 | 918 |
3 125. |
12.09.2022 | От 5 дней |
Условия поставки контактора 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON
Купить контакторы 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON могут физические и юридические лица, по безналичному и наличному расчету, отгрузка производится с пункта выдачи на следующий день после поступления оплаты.
Цена контактора 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON 50Гц/240В 60Гц) зависит от общей суммы заказа, на сайте указана оптовая цена.
Доставим контактор 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON на следующий день после оплаты, по Москве и в радиусе 200 км от МКАД, в другие регионы РФ отгружаем транспортными компаниями.
Похожие товары
Миниконтактор 12А 230В AC 1НO категория применения AC-3/АС4, DILEM12-10(230V50Hz) — 127075 EATON | 162 | 1 271.16 р. | |
Контактор 32А 230В AC 1НЗ категория применения AC-3/AC-4, DILM32-01(230V50HZ, 240V60HZ) — 277292 EATON | 21 | 4 836.06 р. | |
Контактор 32 А, управляющее напряжение 230В (АС), 4 полюса, категория применения AC-3, AC-4, DILMP32-10(230V50HZ, 240V60HZ) EATON 109797 | Под заказ | 3 297. 79 р. 79 р. | |
Контактор 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON | 1 | 4 734.70 р. | |
Контактор 25А 24-27В DC 1НО категория применения AC-3/AC-4, DILM25-10(RDC24) — 277146 EATON | 21 | 5 291.82 р. | |
Сопутствующие товары
Реле перегрузки 1НЗ+1НО 24-32А для DILM17-38/SDAINLM30-45/DIULM17-32, ZB32-32 — 278454 EATON | 17 | 4 320. | |
Реле перегрузки 1НЗ+1НО 16-24А для DILM17-38/SDAINLM30-45/DIULM17-32, ZB32-24 — 278453 EATON | 88 | 2 823.03 р. | |
Блок вспомогательных контактов 4п 2НО+2НЗ пружинные зажимы, DILA-XHIC22 — 276532 EATON | 6 | 784.73 р. | |
Блок вспомогательных контактов 4п 4НЗ винтовые зажимы, DILA-XHI04 — 276424 EATON | 1 | 808. 05 р. 05 р. | |
Блок вспомогательных контактов 4п 1НО+3НЗ винтовые зажимы, DILA-XHI13 — 276425 EATON | 3 | 747.25 р. | |
Контактор 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ)
Уважаемые Клиенты! В связи со сложившейся ситуацией, просим Вас актуальные цены на продукцию уточнять у персональных менеджеров. Благодарим за взаимопонимание и сотрудничество!
- Низковольтное оборудование
- Низковольтные устройства различного назначения и аксессуары
- Пускорегулирующая аппаратура
- Аксессуары для аппаратов защиты
- Контакторы
- Защита от перенапряжения
- Магнитный пускатель, контактор перемен.
 тока (AC)
тока (AC) - Вспомогательный контактор, реле
- Комбинированный пускатель электродвигателя
- Контакторный блок, пускатель комбинированный
- Усилительный модуль для контактора
- Катушка для контактора, реле
- Магнитный пускатель (контактор) для емкостной нагрузки
- Модульный контактор для распределительного щита
- Реле перегрузки тепловое
- Силовой контактор постоянного тока (DC)
- Компоненты светосигнальной арматуры
- Автоматы защиты двигателя
- Автоматические выключатели модульные
- Светосигнальная арматура в сборе
- Элементы управления для светосигнальной арматуры
- Выключатели нагрузки (рубильники)
- Измерительные приборы для установки в щит
- Автоматические выключатели стационарные
- Предохранители
- Автоматические выключатели дифференциального тока (диффавтоматы)
- Устройства защитного отключения (УЗО)
- Клеммные колодки
- Устройства оптической (световой) и акустической (звуковой) сигнализации
- Светосигнальная арматура на дин-рейку
- Автоматы селективной защиты
- Электрооборудование
- Кабель-Провод
- Светотехника
- Электроустановочные изделия
- Общая рубрика
- Отделка и декор
- Инженерные системы
- Инструмент и крепеж
- Общестроительные материалы
Главная
>Низковольтное оборудование
>Контакторы
>Магнитный пускатель, контактор перемен.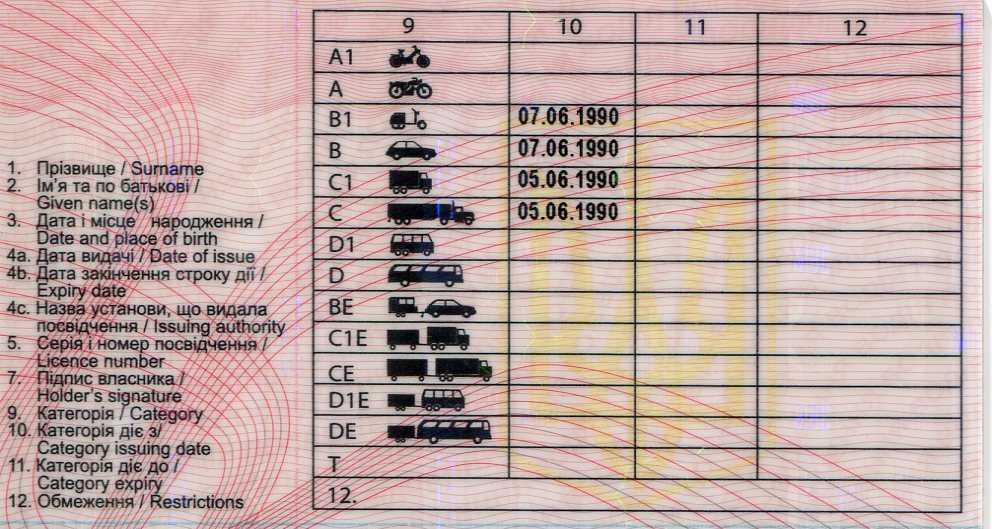 тока (AC)
>EATON
>Контактор 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON (#512011)
тока (AC)
>EATON
>Контактор 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON (#512011)
| Наименование | Наличие | Цена
опт с НДС |
Дата обновления |
Добавить в корзину |
Срок поставки |
|---|---|---|---|---|---|
| Контактор DILM32-10(230В 50Гц/240В 60Гц) EATON 277260 | 1 | 4 734.70 р. | 12.09.2022 | От 5 дней |
Условия поставки контактора 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON
Купить контакторы 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON могут физические и юридические лица, по безналичному и наличному расчету,
отгрузка производится с пункта выдачи на следующий день после поступления оплаты.
Цена контактора 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON пол винт пер.ток 50Гц/240В 60Гц) зависит от общей суммы заказа, на сайте указана оптовая цена.
Доставим контактор 32А 230В AC 1НО категория применения AC-3/AC-4, DILM32-10(230V50HZ, 240V60HZ) — 277260 EATON на следующий день после оплаты, по Москве и в радиусе 200 км от МКАД, в другие регионы РФ отгружаем транспортными компаниями.
Похожие товары
Контактор 18А 230В AC 1НО категория применения AC-3/AC-4, DILM17-10(230V50HZ, 240V60HZ) — 277004 EATON | 457 | 2 269.93 р. | |
Контактор 32 А, управляющее напряжение 230В (АС), 4 полюса, категория применения AC-3, AC-4, DILMP32-10(230V50HZ, 240V60HZ) EATON 109797 | Под заказ | 3 297. 79 р. 79 р. | |
Контактор 32А 230В AC 1НЗ категория применения AC-3/AC-4, DILM32-01(230V50HZ, 240V60HZ) — 277292 EATON | 21 | 4 836.06 р. | |
Контактор 25А 230В AC 1НО категория применения AC-3/AC-4, DILM25-10(230V50HZ,240V60HZ) — 277132 EATON | 918 | 3 125.02 р. | |
Контактор 38 А, управляющее напряжение 230В (АС), 1НЗ доп. | 3 | 5 869.21 р. | |
 контакт, категория применения AC-3, AC-4, DILM38-01(230V50HZ,240V60HZ) EATON 112456
контакт, категория применения AC-3, AC-4, DILM38-01(230V50HZ,240V60HZ) EATON 112456Сопутствующие товары
Реле перегрузки 1НЗ+1НО 10-16А для DILM17-38/SDAINLM30-45/DIULM17-32, ZB32-16 — 278452 EATON | 22 | 2 852.47 р. | |
Контакт дополнительный DILA-XHI31 фронт. | 30 | 779.27 р. | |
Вспомогательный блок-контакт DILM32-XHI11 2 пол. винт. 1НО+1НЗ | 277376 EATON | 1330 | 409.01 р. | |
Блок вспомогательных контактов 4п 4НЗ винтовые зажимы, DILA-XHI04 — 276424 EATON | 1 | 808.05 р. | |
Блок вспомогательных контактов 4п 4НО винтовые зажимы, DILA-XHI40 — 276428 EATON | 3 | 876. 08 р. 08 р. | |
 EATON 276427
EATON 276427API | Категории масел
Skip to main contentНиже представлены текущие и предыдущие категории обслуживания API в удобном табличном формате. Прежде чем обращаться к этим таблицам, владельцам транспортных средств следует изучить руководство по эксплуатации своего автомобиля. У масла может быть несколько эксплуатационных уровней. В случае автомобильных бензиновых двигателей последняя категория обслуживания масла включает эксплуатационные свойства каждой предшествующей категории. Если, согласно руководству по эксплуатации, требуется масло API SJ или SL, то масло API SN обеспечит полную защиту. В случае дизельных двигателей последняя категория обычно, но не всегда, включает эксплуатационные свойства предшествующей категории.
Спецификации API FA-4 и FA-4 Donut выделяют определенные масла XW-30, разработанные специально для использования в отдельных высокоскоростных четырехтактных дизельных двигателях, отвечающих стандартам парниковых выбросов от автомобильных двигателей 2017 модельного года. Масла API FA-4 не являются взаимозаменяемыми или обратно совместимыми с маслами CK-4, CJ-4, CI-4 PLUS, CI-4 и CH-4. Чтобы определить, подходят ли для использования масла API FA-4, изучите рекомендации производителя двигателя.
- ILSAC
- Бензиновые категории
- Дизельные категории C
- Дизельная категория F
Стандарты ILSAC для моторных масел легковых автомобилей
Здесь перечислены текущие и предыдущие стандарты ILSAC. Прежде чем обращаться к этим таблицам, владельцам транспортных средств следует изучить руководство по эксплуатации своего автомобиля.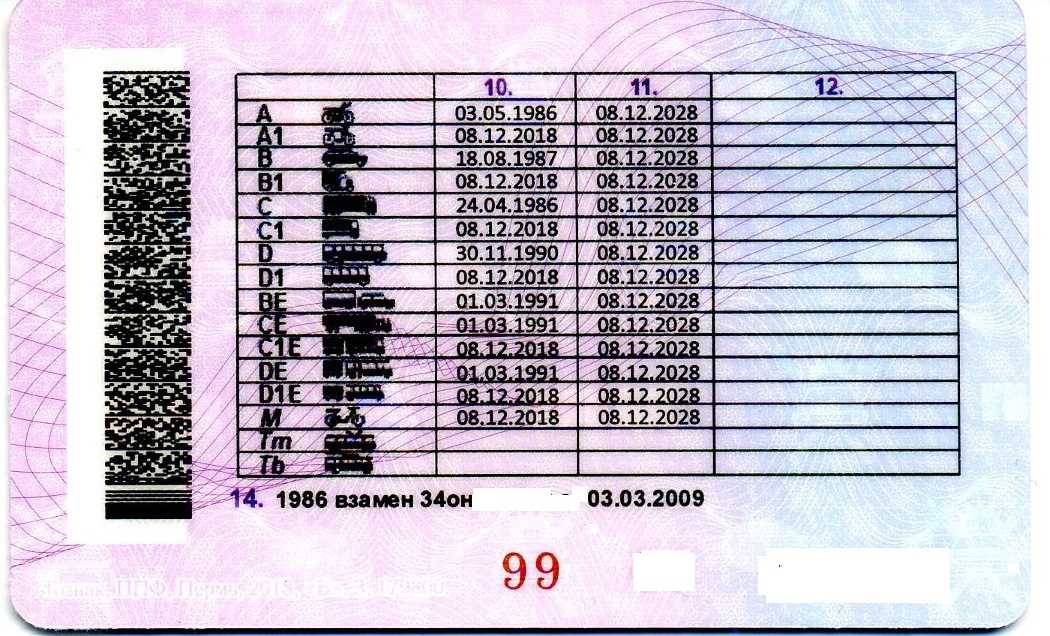 У масла может быть несколько эксплуатационных уровней.
У масла может быть несколько эксплуатационных уровней.
В случае автомобильных бензиновых двигателей последний стандарт ILSAC включает эксплуатационные свойства каждой предшествующей категории и может использоваться для обслуживания более старых двигателей, для которых рекомендовались масла предшествующих категорий.
Название | Статус | Обслуживание |
| GF-5 | Актуально | Категория введена в октябре 2010 года и призвана обеспечить улучшенную защиту от высокотемпературных отложений на поршнях и турбокомпрессорах, более жесткий контроль окисления, повышенную экономию топлива, улучшенную совместимость с системой понижения токсичности выхлопа, совместимость с уплотнителями и защиту двигателей, работающих на маслах с содержанием этанола вплоть до E85. |
| GF-4 | Устарело | Использовать GF-5, если рекомендуется GF-4. |
| GF-3 | Устарело | Использовать GF-5, если рекомендуется GF-3. |
| GF-2 | Устарело | Использовать GF-5, если рекомендуется GF-2. |
| GF-1 | Устарело | Использовать GF-5, если рекомендуется GF-1. |
Бензиновые двигатели
Ниже представлены текущие и предыдущие категории обслуживания API. Прежде чем обращаться к этим таблицам, владельцам транспортных средств следует изучить руководство по эксплуатации своего автомобиля. У масла может быть несколько эксплуатационных уровней.
В случае автомобильных бензиновых двигателей последняя категория обслуживания API включает эксплуатационные свойства каждой предшествующей категории и может использоваться для обслуживания более старых двигателей, для которых рекомендовались масла предшествующих категорий.
Категория | Статус | Обслуживание |
| SN | Актуально | Категория введена в октябре 2010 года и призвана обеспечить улучшенную защиту от высокотемпературных отложений на поршнях и турбокомпрессорах, более жесткий контроль окисления и улучшенную совместимость с уплотнителями. Масла категории API SN с Resource Conserving соответствуют стандарту ILSAC GF-5, обладают эксплуатационными характеристиками API SN, а также улучшенной экономией топлива, защитой турбокомпрессоров, совместимостью с системой понижения токсичности выхлопа и защитой двигателей, работающих на маслах с содержанием этанола вплоть до E85. |
| SM | Актуально | Для автомобильных двигателей 2010 года выпуска и старше. |
| SL | Актуально | Для автомобильных двигателей 2004 года выпуска и старше. |
| SJ | Актуально | Для автомобильных двигателей 2001 года выпуска и старше. |
| SH | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1996 года. Может не обеспечивать адекватную защиту от отложений, окисления и износа двигателя. |
| SG | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1993 года. Может не обеспечивать адекватную защиту от отложений, окисления и износа двигателя.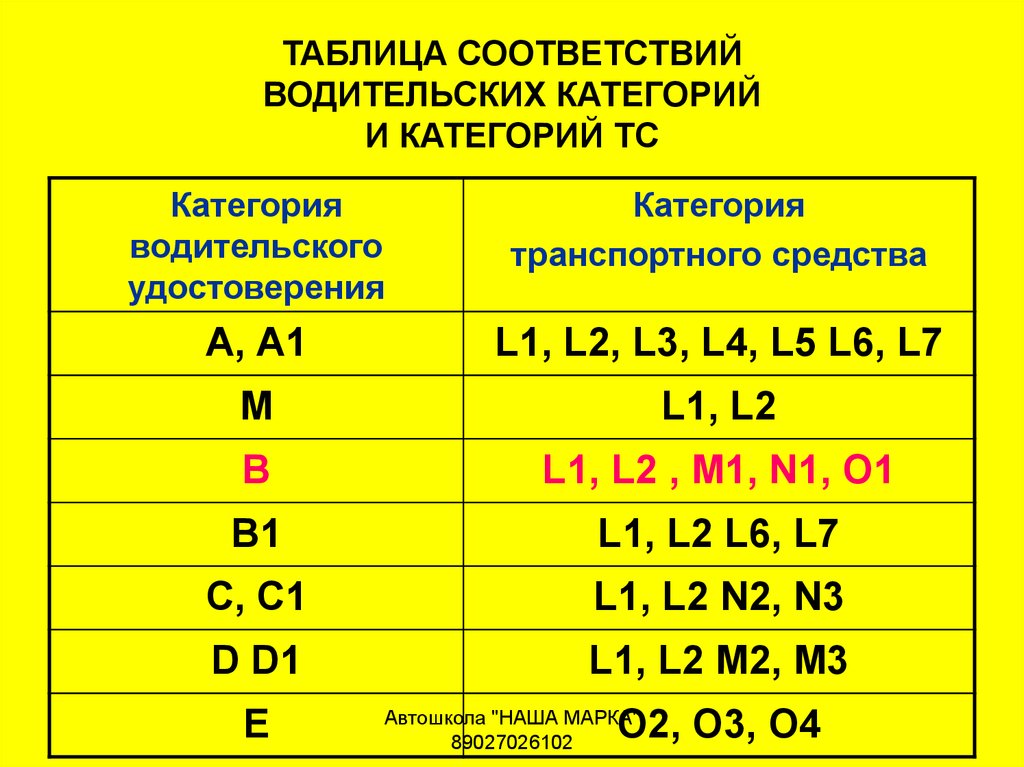 |
| SF | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1988 года. Может не обеспечивать адекватную защиту от отложений в двигателе. |
| SE | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1979 года. |
| SD | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1971 года. В более современных двигателях может работать неудовлетворительно или наносить вред оборудованию. |
| SC | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1967 года. В более современных двигателях может работать неудовлетворительно или наносить вред оборудованию. В более современных двигателях может работать неудовлетворительно или наносить вред оборудованию. |
| SB | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1951 года. В более современных двигателях может работать неудовлетворительно или наносить вред оборудованию. |
| SA | Устарело | ВНИМАНИЕ! Не содержит присадок. Не подходит для использования в большинстве автомобильных бензиновых двигателей, выпущенных после 1930 года. В современных двигателях может работать неудовлетворительно или наносить вред оборудованию. |
Дизельные двигатели
(Придерживайтесь рекомендаций производителя автомобиля в отношении эксплуатационных уровней масла.)
Категория | Статус | Обслуживание |
| CK-4 | Актуально | Категория обслуживания API CK-4 описывает масла, предназначенные для использования в высокоскоростных четырехтактных дизельных двигателях, отвечающих стандартам выбросов от автомобильных двигателей 2017 модельного года и двигателей неавтомобильного применения 4 категории, а также в дизельных двигателях предыдущего модельного года. Эти масла разработаны для использования во всех двигателях с дизельным топливом с содержанием серы до 500 мг/кг (0,05% веса). Однако использование этих масел в топливе с содержанием серы сверх 15 мг/кг (0,0015% веса) может повлиять на долговечность системы нейтрализации выхлопных газов и (или) интервалы замены масла. Эти масла особенно эффективно поддерживают долговечность системы понижения токсичности выхлопа в случаях, когда используются сажевые фильтры и другие усовершенствованные системы нейтрализации выхлопных газов. Масла категории API CK-4 обеспечивают усиленную защиту от окисления масла, потери вязкости из-за сдвигов и аэрации масла, а также защиту от отравления катализатора, закупоривания сажевого фильтра, износа двигателя, отложений на поршнях, ухудшения низкотемпературных и высокотемпературных свойств и повышения вязкости в связи с нагаром. Масла API CK-4 превосходят по эксплуатационным свойствам масла API CJ-4, CI-4 с CI-4 PLUS, CI-4 и CH-4 и служат эффективным смазочным материалом для двигателей, требующих этих категорий обслуживания API. Эти масла разработаны для использования во всех двигателях с дизельным топливом с содержанием серы до 500 мг/кг (0,05% веса). Однако использование этих масел в топливе с содержанием серы сверх 15 мг/кг (0,0015% веса) может повлиять на долговечность системы нейтрализации выхлопных газов и (или) интервалы замены масла. Эти масла особенно эффективно поддерживают долговечность системы понижения токсичности выхлопа в случаях, когда используются сажевые фильтры и другие усовершенствованные системы нейтрализации выхлопных газов. Масла категории API CK-4 обеспечивают усиленную защиту от окисления масла, потери вязкости из-за сдвигов и аэрации масла, а также защиту от отравления катализатора, закупоривания сажевого фильтра, износа двигателя, отложений на поршнях, ухудшения низкотемпературных и высокотемпературных свойств и повышения вязкости в связи с нагаром. Масла API CK-4 превосходят по эксплуатационным свойствам масла API CJ-4, CI-4 с CI-4 PLUS, CI-4 и CH-4 и служат эффективным смазочным материалом для двигателей, требующих этих категорий обслуживания API. При использовании масла CK-4 с топливом с содержанием серы более 15 мг/кг необходимо проконсультироваться с производителем двигателя для получения рекомендаций касательно интервалов обслуживания. При использовании масла CK-4 с топливом с содержанием серы более 15 мг/кг необходимо проконсультироваться с производителем двигателя для получения рекомендаций касательно интервалов обслуживания. |
| CJ-4 | Актуально | Описывает масла, предназначенные для использования в высокоскоростных четырехтактных дизельных двигателях, отвечающих стандартам выбросов от автомобильных двигателей 2010 модельного года и двигателей неавтомобильного применения 4 категории, а также в дизельных двигателях предыдущего модельного года. Эти масла разработаны для использования во всех двигателях с дизельным топливом с содержанием серы до 500 мг/кг (0,05% веса). Однако использование этих масел в топливе с содержанием серы сверх 15 мг/кг (0,0015% веса) может повлиять на долговечность системы нейтрализации выхлопных газов и (или) интервалы замены масла. Масла API CJ-4 превосходят по эксплуатационным свойствам масла API CI-4 с CI-4 PLUS, CI-4, CH-4, CG-4 и CF-4 и служат эффективным смазочным материалом для двигателей, требующих этих категорий обслуживания API. При использовании масла CJ-4 с топливом с содержанием серы более 15 мг/кг необходимо проконсультироваться с производителем двигателя для получения рекомендаций касательно интервалов обслуживания. При использовании масла CJ-4 с топливом с содержанием серы более 15 мг/кг необходимо проконсультироваться с производителем двигателя для получения рекомендаций касательно интервалов обслуживания. |
| CI-4 | Актуально | Введена в 2002 году. Предназначена для высокоскоростных четырехтактных дизельных двигателей, отвечающих стандартам выбросов выхлопных газов на 2004 год, введенным в 2002 году. Масла CI-4 поддерживают долговечность двигателей, в которых применяется рециркуляция выхлопных газов, и предназначены для использования с дизельным топливом с содержанием серы до 0,5% веса. Можно использовать в качестве замены масел CD, CE, CF-4, CG-4 и CH-4. Некоторые масла CI-4 также могут соответствовать категории CI-4 PLUS. |
| CH-4 | Актуально | Введена в 1998 году. Предназначена для высокоскоростных четырехтактных дизельных двигателей, отвечающих стандартам выбросов выхлопных газов 1998 года. |
| CG-4 | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 2009 года. |
| CF-4 | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 2009 года. |
| CF-2 | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 2009 года. У двухтактных двигателей могут быть иные требования к смазке, чем у четырехтактных, поэтому за соответствующими рекомендациями следует обращаться к производителю. |
| CF | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 2009 года. Как правило, масла более новой категории C являются более подходящими или предпочтительными для автомобильных дизельных двигателей, для которых указывались масла CF. Однако старое оборудование и (или) двухтактные дизельные двигатели, особенно ориентированные на однодиапазонные масла, могут требовать использования масел категории CF. |
| CE | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 1994 года. |
| CD-II | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 1994 года. |
| CD | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве автомобильных дизельных двигателей, выпущенных после 1994 года. |
| CC | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве дизельных двигателей, выпущенных после 1990 года. |
| CB | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве дизельных двигателей, выпущенных после 1961 года. |
| CA | Устарело | ВНИМАНИЕ! Не подходит для использования в большинстве дизельных двигателей, выпущенных после 1959 года. |
Дизельные двигатели
(Придерживайтесь рекомендаций производителя автомобиля в отношении эксплуатационных уровней масла. )
)
Категория | Статус | Обслуживание |
| FA-4 | Актуально | Категория обслуживания API FA-4 выделяет определенные масла XW-30, разработанные специально для использования в отдельных высокоскоростных четырехтактных дизельных двигателях, отвечающих стандартам парниковых выбросов от автомобильных двигателей 2017 модельного года. Эти масла разработаны для использования в автомобильных двигателях с дизельным топливом с содержанием серы до 15 мг/кг (0,0015% веса). За индивидуальными рекомендациями по совместимости с маслами API FA-4 следует обращаться к производителю двигателя. Эти масла разработаны для диапазона высокотемпературной вязкости при высокой скорости сдвига в 2,9–3,2 сП в целях снижения парниковых выбросов. Эти масла особенно эффективно поддерживают долговечность системы понижения токсичности выхлопа в случаях, когда используются сажевые фильтры и другие усовершенствованные системы нейтрализации выхлопных газов. Масла категории API FA-4 обеспечивают усиленную защиту от окисления масла, потери вязкости из-за сдвигов и аэрации масла, а также защиту от отравления катализатора, закупоривания сажевого фильтра, износа двигателя, отложений на поршнях, ухудшения низкотемпературных и высокотемпературных свойств и повышения вязкости в связи с нагаром. Масла API FA-4 не являются взаимозаменяемыми или обратно совместимыми с маслами API CK-4, CJ-4, CI-4 с CI-4 PLUS, CI-4 и CH-4. Чтобы определить, подходят ли для использования масла API FA-4, изучите рекомендации производителя двигателя. Масла API FA-4 не рекомендуется использовать с топливом с содержанием серы более 15 мг/кг. За рекомендациями в отношении топлива с содержанием серы более 15 мг/кг следует обращаться к производителю двигателя. Масла категории API FA-4 обеспечивают усиленную защиту от окисления масла, потери вязкости из-за сдвигов и аэрации масла, а также защиту от отравления катализатора, закупоривания сажевого фильтра, износа двигателя, отложений на поршнях, ухудшения низкотемпературных и высокотемпературных свойств и повышения вязкости в связи с нагаром. Масла API FA-4 не являются взаимозаменяемыми или обратно совместимыми с маслами API CK-4, CJ-4, CI-4 с CI-4 PLUS, CI-4 и CH-4. Чтобы определить, подходят ли для использования масла API FA-4, изучите рекомендации производителя двигателя. Масла API FA-4 не рекомендуется использовать с топливом с содержанием серы более 15 мг/кг. За рекомендациями в отношении топлива с содержанием серы более 15 мг/кг следует обращаться к производителю двигателя. |
Thank you for Subscribing Unable to Process Request x
Использование вложенных функций в формуле
Использование функции в качестве одного из аргументов в формуле, использующей функцию, называется вложенным, и мы будем называть ее вложенной функцией. Например, при вложении функций СНВП и СУММ в аргументы функции ЕСЛИ следующая формула суммирует набор чисел (G2:G5), только если среднее значение другого набора чисел (F2:F5) больше 50. В противном случае она возвращает значение 0.
Например, при вложении функций СНВП и СУММ в аргументы функции ЕСЛИ следующая формула суммирует набор чисел (G2:G5), только если среднее значение другого набора чисел (F2:F5) больше 50. В противном случае она возвращает значение 0.
Функции СРЗНАЧ и СУММ вложены в функцию ЕСЛИ.
В формулу можно вложить до 64 уровней функций.
-
Щелкните ячейку, в которую нужно ввести формулу.
-
Чтобы начать формулу с функции, щелкните Вставить функцию в .
Знак равенства (=) будет вставлен автоматически.
 org/ListItem»>
org/ListItem»>
В поле Категория выберите пункт Все.
Если вы знакомы с категориями функций, можно также выбрать категорию.
Если вы не знаете, какую функцию использовать, можно ввести вопрос, описывающий необходимые действия, в поле Поиск функции (например, при вводе «добавить числа» возвращается функция СУММ).
-
Чтобы ввести другую функцию в качестве аргумента, введите функцию в поле этого аргумента.
Части формулы, отображенные в диалоговом окне Аргументы функции, отображают функцию, выбранную на предыдущем шаге.
Если щелкнуть элемент ЕСЛИ, в диалоговом окне Аргументы функции отображаются аргументы для функции ЕСЛИ.
 Чтобы вложить другую функцию, можно ввести ее в поле аргумента. Например, можно ввести СУММ(G2:G5) в поле Значение_если_истина функции ЕСЛИ.
Чтобы вложить другую функцию, можно ввести ее в поле аргумента. Например, можно ввести СУММ(G2:G5) в поле Значение_если_истина функции ЕСЛИ. -
Введите дополнительные аргументы, необходимые для завершения формулы.
Вместо того, чтобы вводить ссылки на ячейки, можно также выделить ячейки, на которые нужно сослаться. Щелкните , чтобы свернуть диалоговое окно, выйдите из ячеек, на которые нужно со ссылкой, , чтобы снова развернуть диалоговое окно.
Совет: Для получения дополнительных сведений о функции и ее аргументах щелкните ссылку Справка по этой функции.
-
После ввода всех аргументов формулы нажмите кнопку ОК.

-
Щелкните ячейку, в которую нужно ввести формулу.
-
Чтобы начать формулу с функции, щелкните Вставить функцию в .
-
В диалоговом окне Вставка функции в поле Выбрать категорию выберите все.
Если вы знакомы с категориями функций, можно также выбрать категорию.
-
Чтобы ввести другую функцию в качестве аргумента, введите ее в поле аргумента в построитель формул или непосредственно в ячейку.

-
Введите дополнительные аргументы, необходимые для завершения формулы.
-
Завершив ввод аргументов формулы, нажмите ввод.
Примеры
Ниже приведен пример использования вложенных функций ЕСЛИ для назначения буквенных категорий числовым результатам тестирования.
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Оценка |
||
|---|---|---|
|
45 |
||
|
90 |
||
|
78 |
||
|
Формула |
Описание |
Результат |
|
‘=ЕСЛИ(A2>89,»A»,ЕСЛИ(A2>79,»B», ЕСЛИ(A2>69,»C»,ЕСЛИ(A2>59,»D»,»F»)))) |
Использует вложенные функции ЕСЛИ для назначения буквенной категории оценке в ячейке A2. |
=ЕСЛИ(A2>89;»A»;ЕСЛИ(A2>79;»B»; ЕСЛИ(A2>69;»C»;ЕСЛИ(A2>59;»D»;»F»)))) |
|
‘=ЕСЛИ(A3>89,»A»,ЕСЛИ(A3>79,»B», ЕСЛИ(A3>69,»C»,ЕСЛИ(A3>59,»D»,»F»)))) |
Использует вложенные функции ЕСЛИ для назначения буквенной категории оценке в ячейке A3. |
=ЕСЛИ(A3>89,»A»,ЕСЛИ(A3>79,»B»,ЕСЛИ(A3>69,»C»,ЕСЛИ(A3>59,»D»,»F»)))) |
|
‘=ЕСЛИ(A4>89,»A»,ЕСЛИ(A4>79,»B», ЕСЛИ(A4>69,»C»,ЕСЛИ(A4>59,»D»,»F»)))) |
Использует вложенные функции ЕСЛИ для назначения буквенной категории оценке в ячейке A4. |
=ЕСЛИ(A4>89,»A»,ЕСЛИ(A4>79,»B»,ЕСЛИ(A4>69,»C»,ЕСЛИ(A4>59,»D»,»F»)))) |

Советы:
-
Дополнительные сведения о формулах см. в общих сведениях о формулах.
-
Список доступных функций см. в разделе Функции Excel (по алфавиту) или Функции Excel (по категориям).
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Видео: вложенные функции ЕСЛИ
Гостиница в Улан-Удэ.
 Официальный сайт гостиницы Бурятия, тел. 8-800-222-09-30
Официальный сайт гостиницы Бурятия, тел. 8-800-222-09-30панорамный вид на город – все достопримечательности как на ладони
Поселитесь в нашей гостинице Улан-Удэ, и у вас останутся приятные воспоминания от поездки в столицу Бурятии. В свободное время вы сможете осмотреть достопримечательности – рядом с отелем расположен Театр оперы и балета, площадь Советов, здание Правительства Республики. В 5 минутах ходьбы находятся остановки общественного транспорта – легко уехать в любую точку города.
Наш внимательный и заботливый персонал — всегда к вашим услугам! Независимо от цели вашей поездки, будь это командировка, семейный отдых или деловая поездка, мы обеспечим максимально комфортное и приятное пребывание в нашем отеле.
Смотрите отзывы>>
Находимся в 5 минутах езды от ж/д вокзала, в 15 минутах – от аэропорта Байкал:
Улан-Удэ, Коммунистическая,47a
Показать полную карту
Самый большой отель в Улан-Удэ: примем более 300 гостей одновременно
Одноместный «Комфорт» (I категория)Забронировать
4 000-10%
3 600 Р
Двухместный «Комфорт» (I категория)Забронировать
5 000-10%
4 500 Р
Одноместный «Стандарт» (I категория)Забронировать
3 500-10%
3 150 Р
Двухместный «Стандарт» (I категория)Забронировать от
4 000-10%
3 600 Р
«Джуниор Сюит» (Высшая категория)Забронировать
5 500-10%
4 950 Р
«Люкс» (Высшая категория)Забронировать
7 000-10%
6 300 Р
«Апартамент» (Высшая категория)Забронировать
9 500-10%
8 550 Р
Комфорт и высокий уровень сервиса по доступной цене
Современное оснащение, качественный сервис и уют — мы делаем все, чтобы вы могли наслаждаться отдыхом.
Специально для вашего комфорта:
Великолепные завтраки, обеды и ужины в кафе «Чашка» на первом этаже;
Конференц-залы для проведения деловых мероприятий и другие дополнительные услуги;
Внимание к каждому гостю – доброжелательный персонал поможет решить любые возникающие вопросы;
Тренажерный зал и сауна – позволят поддерживать фигуру и здоровье даже на отдыхе или в командировке.
- Отличный завтрак (шведский стол) — включен в стоимость номера (кроме категории Эконом)
- Доступ к беспроводному интернету Wi-Fi
- Бесплатная автостоянка для гостей отеля
Номерной фонд →
Забронируйте номер в нашей гостинице в Улан-Удэ без предоплаты – 8 (3012) 58-02-04, 8-800-222-09-30
позвоните по тел.
Спецпредложения
Программа лояльности
Предлагаем Вашему вниманию обновленную программу лояльности
Подробнее
Тариф «Свадебный»
Воспользуйтесь эксклюзивным предложением для новобрачных в Отеле «Бурятия»!
Подробнее
Бесплатный трансфер!
При проживании более 7 суток — всем гостям бесплатный трансфер до международного аэропорта «Байкал» или до железнодорожного вокзала!
Подробнее
Комплимент от отеля в день рождения!
Фруктовая ваза в подарок
Подробнее
10% на ваш телефон
Наш отель присоединился к бонусной системе «Гостинец».
Подробнее
Услуги
Конференц-залы
Предлагаем многофункциональные конференц-площадки для проведения деловых мероприятий от 10 до 500 человек. Все залы оснащены качественным современным оборудованием. Возможна организация кофе-брейков, фуршетов и ужинов для участников мероприятия. Подробнее>>
Ресторан
Банкетные залы ресторана «Бурятия» идеально подойдут для организации торжественных и официальных мероприятий любого уровня. Вас ждет изысканная кухня и высокий уровень сервиса. Просторные залы оснащены современной аудиотехникой и светиодным экраном и вмещают до 500 персон. Подробнее>>
Посмотреть все услуги
Забронируйте номер в гостинице «Бурятия» по тел. 8 (3012) 58-02-04, 8-800-222-09-30
У нас всегда есть свободные номера
Новости
7 сентября 2022 Приглашаем на работу
24 августа 2022 Кешбэк 20%
10 августа 2022 В 2023 г стену нашей гостиницы украсит «Мантра»
19 июля 2022
Гостиница «Бурятия» получила сертификат участника Международного проекта «Экологическая культура. Мир и согласие»
14 июля 2022 Музыкальный фестиваль «Голос Кочевника» 15-16 июля
5 июля 2022 Вчера прошла презентация ресторана «Тэнгис» для представителей туристической отрасли
Отзывы
Потрясающий вид с 12го этажа на город. Приветливый персонал. Адекватные цены. Всем остались довольны.
Читать полностью
Мария С., 6 августа 2022
Гостиница очень уютная, приятно зайти в номер все чисто и аккуратно, очень порадовал завтрак, шведский стол, все продукты свежие, большой выбор для полноценного завтрака. Всем рекомендую посетить эту гостиницу.

Читать полностью
Артём К., 4 августа 2022
Очень достойное обслуживание, чистые современные номера, удобное расположение в центре города , вкусная национальная кухня.
Читать полностью
yury Skitskiy, 22 июля 2022
Забронируй со скидкой 10%
Преображенская площадь, Щелковская, Тушино, Строгино
Обучение водителейсм.расписание занятий
Категория A, А1
МОТО Мото с 16 лет от — 15000
Мото с 18 лет от — 15000
Категория B
АВТО МКПП от — 24000
АКПП от — 26000
Категория А+B
АВТО+МОТО МКПП+МОТО от — 35500
АКПП+МОТО от — 39500
Подробнее. ..
Ассоциация Автошкол
Напиши письмо
Режим работы:
Теоретические занятия
см.расписание занятий
Понедельник, среда Идет набор!
Вторник, четверг Идет набор!
Пятница Идет набор!
Суббота Идет набор!
Воскресенье Идет набор!
Экспресс-курс Идет набор!
Практические занятия
Понедельник-воскресенье
07:00 — 21:00
Водительские права нового образца — 2015г
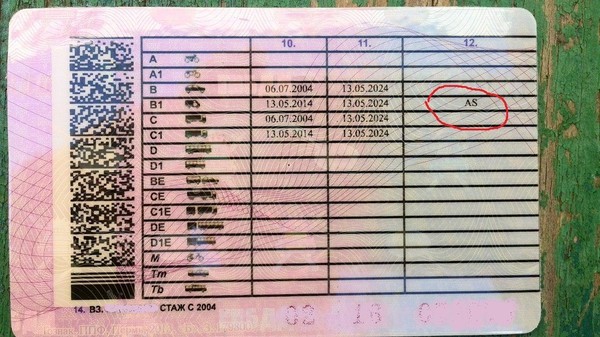
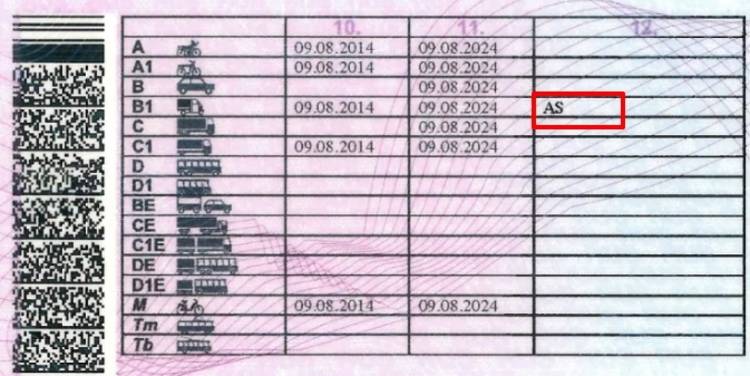
Обратите внимание на фото водительских прав нового образца 2015 года в России, так выглядит новое водительское удостоверение. В каждом удостоверении в обязательном порядке указывается следующая информация:
Запись в удостоверении ведется буквами кириллического алфавита, в случае использовании букв другого алфавита, должен быть рядом написан транслит латинскими буквами.
Более подробно о категориях и подкатегориях ВУ смотрите в таблице:
Категория и подкатегория | Вид транспорта | Описание категории |
| А | Мотоциклы | Категория «А» дает возможность управлять мотоциклом. Согласно пункту 1.1 главы 1 ПДД, мотоцикл — двухколесное механическое транспортное средство с боковым прицепом или без него. К мотоциклам приравниваются трех- и четырехколесные механические транспортные средства, имеющие массу в снаряженном состоянии не более 400 кг. Мнение о том, что управлять данным транспортным средством необходимо только со специальными водительскими правами на мотоцикл – можно считать абсурдным. |
| A1 | Легкие мотоциклы с мощностью двигателя от 50 до 125 куб.см и максимальной мощностью до 11кВт | Категория «А1» водительских прав также относится к разряду мотоциклов, но единственное отличие между предыдущей категорией и этой то, что открывая данную подкатегорию, управлять можно мотоциклом только с мощностью от 50 до 125 куб.см, а так же с максимальной мощностью до 11кВт. Другими словами, транспорт, которым можно управлять с категорией А1 в водительском удостоверении 2015 года – скутер. Но стоит отметить тот факт, что, имея открытую категорию в водительском удостоверении на мотоцикл, данная подкатегория присваивается автоматически |
| B | Автомобили с максимальным весом, не превышающим 3,5 тонны и числом мест, помимо сиденья водителя, не превышает восьми | Категория «В» водительских прав дает возможность управлять легковым автомобилем, масса которого не превышает 3,5 тонн, а количество сидячих мест, помимо места водителя, не превышает восьми. Так же водительское удостоверение категории В разрешает управление транспортным средством массой не более 3,5 тонн, сцепленных с прицепом, масса которого не превышает 750 кг. Помимо этого, не исключено управление транспортного средства массой не более 3,5 тонн, сцепленного с прицепом, превышающим массу 750 килограмм, но не превышает массу автомобиля без нагрузки, при этом общая сумма веса не должна превышать 3,5 тонны. Согласно пункту 1.1 главы 1 ПДД, прицеп — транспортное средство, не оборудованное двигателем и предназначенное для движения в составе с механическим транспортным средством. Термин распространяется также на полуприцепы и прицепы-роспуски. Управлять можно так же микроавтобусами и джипами, главное условие – соответствие вышеприведенных правил с вашим автомобилем. |
| В1 | Трициклы и квадрициклы | Категория «В1» водительских прав предоставляет возможность управлять трех- или четырехколесным автомобилем, порожняя масса которого не превышает 550 кг. Его изготовительская скорость превышает 50 км/ч. В случае, если транспорт имеет двигатель внутреннего сгорания, то его рабочий объем будет более 50 куб.см. При порожней массе, в транспорте с электрическим приводом, масса аккумулятора не учитывается. Согласно ГОСТу Р 41.73-99, порожняя масса – это масса транспортного средства в снаряженном состоянии без водителя и пассажиров, без груза, но полностью заправленного топливом, охлаждающей жидкостью, смазочными материалами и с инструментом и запасным колесом, если оно прилагается предприятием-изготовителем транспортного средства в качестве комплектного оборудования. Соответственно, если у вас в водительском удостоверении категория В1 открыта, то вы можете управлять трициклом и квадрициклом. Стоит заметить, что квадрицикл и квадроцикл — это две совершенно разные вещи, поэтому управлять квадроциклом с обычными водительскими правами нельзя. |
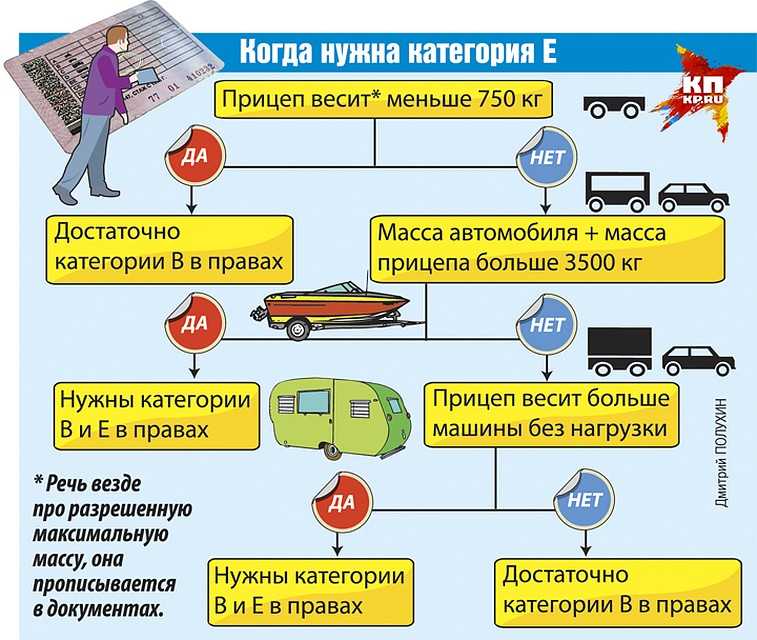
| ВЕ | Автомобили категории В с прицепом, масса которого превышает 750 килограммов | Категория «ВЕ» позволяет управлять транспортом категории В, сцепленным с прицепом, масса которого превышает 750 килограмм, а также превышает массу самого автомобиля без нагрузки. При этом основное условие данного состава – разрешенная общая масса превышает 3,5 тонны. |
| C | Автомобили, масса которого превышает 3,5 тонны, в том числе с прицепом до 750 кг | Категория «С» Имея данную категорию, можно управлять автомобилями, масса которых превышает 3,5 тонны, а так же сцепленными с прицепами, масса которых не превышает 750 килограмм. Данная категория предназначена только для грузовиков массой более 3,5 тонн и не относится к автомобилям категории D. Помимо того, недопустимо управление легкими грузовиками и легковыми автомобилями, масса которых не превышает 3500 килограмм. |
| С1 | Автомобили с максимальным весом от 3,5 тонн до 7,5 тонн | Категория «С1» исключает автомобили категории D. Разрешенная масса транспортного средства категории С1 составляет от 3,5 тонн 7,5 тонн. Также не исключается возможность управлять данным видом транспорта сцепленным с прицепом, масса которого не превышает 750 килограмм. Стоит отметить тот факт, водитель, который имеет категорию С, может беспрепятственно управлять автомобилями категории С1. |
| СE | Автомобили категории С с прицепом, масса которого составляет от 750 кг до 3,5 тонн | Категория «СЕ» – это категория, которая позволяет управлять транспортом категории С сцепленного прицепом, масса которого не менее 750 килограмм, но не превышает 3,5 тонны. Для того чтобы открыть данную категорию, необходимо изначально открыть категорию С. |
| С1E | Автомобили категории С1, масса которых превышает 3,5 тонн, но не превышает 7.5 тонн сцепленных с прицепом, масса которого превышает 750 кг, при общей сумме не более 12 тонн | Категория «С1Е» предоставляет право на управление транспортом категории С1, вес которого составляет от 3,5 тонн до 7,5 тонн, сцепленного с прицепом, масса которого превышает 750 килограмм, но не превышает массы автомобиля без нагрузки. Главное условие данного состава, это чтобы суммарный вес не превышал 12 тонн. Водители с открытой категорией СЕ имеет право управлять транспортом категории С1Е. |
| D | Автомобили для перевозки пассажиров, которые имеют более 8 сидячих мест, помимо места водителя, в том числе с прицепом массой до 750 кг. | Категория «D» в водительских правах позволяет управлять автомобилями, которые предназначены для перевозки людей и имеют, помимо сиденья водителя, более 8 сидячих мест. Также можно управлять автомобилем категории D, сцепленным с прицепом, масса которого не превышает 750 килограмм. Под эту категорию попадают различные автобусы. |
| D1 | Автомобили с количеством мест 8-16, помимо места водителя | Категория «D1» – это транспорт, который предназначен для перевозки пассажиров и имеет более 8 пассажирских мест, но не более 16. Помимо этого, разрешено использование прицепа, масса которого не превышает 750 килограмм. Водители, имеющую категорию D, могут управлять данной категорией. |
| DE | Автомобили категории D с прицепом массой от 750 кг до 3,5 тонн | Категория «DЕ» – это автомобили категории D, сцепленные с прицепом, масса которого не менее 750 килограмм, но не более 3,5 тонн. Под эту категорию попадают также сочлененные автобусы. |
| D1E | Автомобили категории DE с прицепом, масса которого не менее 750 кг, но не более 12 тонн | Категория «D1Е» предоставляет возможность управления транспортным средством категории D1, сцепленным с прицепом, масса которого превышает 750 килограмм, но при этом общая масса транспортного состава не должна превышать 12 тонн. Стоит отметить тот факт, что прицеп не должен быть предназначен для перевозки людей. Для тех, кто имеет в водительском удостоверении открытую категорию DE, данная подкатегория открывается автоматически. |
| M | Мопеды, скутеры и квадрициклы объемом до 50 куб. см | Категория «М» водительских прав в 2015 году обозначает наличие права управления мопедами и легкими квадрициклами. Для того чтобы сделать водительское удостоверение категории М, достаточно иметь открытую любую другую категорию. |
| Tm | Трамваи | Категория «Tm» обозначает возможность управлять трамваем. |
| Tb | Троллейбусы | Категория «Tb» обозначает возможность управлять троллейбусом. |
Категория «Е» На сегодняшний день водительские права категории Е исчезли из обихода водителей. На смену ей пришли, представленные выше, категории BE, CE, C1E, DE, D1E.
Вернуться назад.
Фотографии2015 — 2019 © Сайт-агрегатор альянса автошкол «МЕГАПОЛИС»
Лицензия №036270 от 17. 06.2015 и №037526 от 26.05.2016
Главная| Новости| Обучение| Цены| Акции| Отзывы| Контакты| Расписание занятий| Наши преподаватели| Фотографии| #АВТОШКОЛАМЕГАПОЛИС| Онлайн экзамен ПДД
Категориальные данные — документация pandas 1.4.4
Это введение в категориальный тип данных pandas, включая краткое сравнение
с коэффициентом R .
Categoricals — это тип данных pandas, соответствующий категориальным переменным в
статистика. Категориальная переменная принимает ограниченное и обычно фиксированное значение.
количество возможных значений ( категории ; уровня в R). Примеры: пол,
социальный класс, группа крови, принадлежность к стране, время наблюдения или рейтинг через
шкалы Лайкерта.
В отличие от статистических категориальных переменных, категориальные данные могут иметь порядок (например,
«полностью согласен» против «согласен» или «первое наблюдение» против «второго наблюдения»), но числовые
операции (сложения, деления и т. д.) невозможны.
Все значения категорийных данных находятся либо в категориях , либо в np.nan . Порядок определяется
порядок категории , не лексический порядок значений. Внутренняя структура данных
состоит из категории массив и целочисленный массив кодов которые указывают на реальное значение в
массив категорий .
Категориальный тип данных полезен в следующих случаях:
Строковая переменная, состоящая всего из нескольких различных значений. Преобразование такой строки переменная в категориальную переменную сэкономит немного памяти, см. здесь.
Лексический порядок переменной не совпадает с логическим («один», «два», «три»). Путем преобразования в категориальный и указания порядка категорий, сортировки и min/max будет использовать логический порядок вместо лексического, см. здесь.
Как сигнал другим библиотекам Python, что этот столбец следует рассматривать как категориальный переменной (например, для использования подходящих статистических методов или типов графиков).
См. также документацию API по категориям.
Создание объекта
Создание серии
Категориальный Серия или столбцы в DataFrame могут быть созданы несколькими способами:
Путем указания dtype="category" при построении Серия :
В [1]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [2]: с Выход[2]: 0 а 1 б 2 с 3 часа тип: категория Категории (3, объект): ['a', 'b', 'c']
Путем преобразования существующей серии или столбца в категорию dtype:
В [3]: df = pd.DataFrame({"A": ["a", "b", "c", "a"]})
В [4]: df["B"] = df["A"].astype("категория")
В [5]: дф
Выход[5]:
А Б
0 а а
1 б б
2 с с
3 а а
С помощью специальных функций, таких как cut() , который группирует данные в
дискретные бункеры. См. пример тайлинга в документации.
В [6]: df = pd.DataFrame({"значение": np.random. randint(0, 100, 20)})
В [7]: labels = ["{0} - {1}".format(i, i + 9) для i в диапазоне (0, 100, 10)]
В [8]: df["group"] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels)
В [9]: df.head(10)
Выход[9]:
группа значений
0 65 60 - 69
1 49 40 - 49
2 56 50 - 59
3 43 40 - 49
4 43 40 - 49
5 91 90 - 99
6 32 30 - 397 87 80 - 89
8 36 30 - 39
9 8 0 - 9
Передав объект pandas.Categorical серии или назначив его DataFrame .
В [10]: raw_cat = pd.Categorical(
....: ["a", "b", "c", "a"], Categories=["b", "c", "d"], order=False
.... :)
....:
В [11]: s = pd.Series(raw_cat)
В [12]: с
Выход[12]:
0 NaN
1 б
2 с
3 NaN
тип: категория
Категории (3, объект): ['b', 'c', 'd']
В [13]: df = pd.DataFrame({"A": ["a", "b", "c", "a"]})
В [14]: df["B"] = raw_cat
В [15]: дф
Исход[15]:
А Б
0 NaN
1 б б
2 с с
3 NaN
Категориальные данные имеют определенную категорию dtype:
В [16]: df.dtypes Вышли[16]: Объект категория Б тип: объект
Создание кадра данных
Аналогично предыдущему разделу, где один столбец был преобразован в категориальный, все столбцы в DataFrame может быть пакетно преобразован в категориальный во время или после построения.
Это можно сделать во время строительства, указав dtype="category" в DataFrame конструктор:
В [17]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")}, dtype="category")
В [18]: df.dtypes
Вышли[18]:
Категория
категория Б
тип: объект
Обратите внимание, что категории в каждом столбце различаются; преобразование выполняется столбец за столбцом, поэтому только ярлыки, присутствующие в данном столбце, являются категориями:
В [19]: df["A"] Вышли[19]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [20]: df["B"] Исход[20]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Аналогично, все столбцы в существующем DataFrame могут быть преобразованы в пакетном режиме с использованием DataFrame.astype() :
В [21]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")})
В [22]: df_cat = df.astype("категория")
В [23]: df_cat. dtypes
Вышли[23]:
Категория
категория Б
тип: объект
Это преобразование также выполняется столбец за столбцом:
В [24]: df_cat["A"] Вышли[24]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [25]: df_cat["B"] Вышли[25]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Управление поведением
В приведенных выше примерах, где мы передали dtype='category' , мы использовали значение по умолчанию
поведение:
Категории выводятся из данных.
Категории неупорядочены.
Чтобы управлять этим поведением, вместо передачи «категории» используйте экземпляр
из КатегориальныйDтип .
В [26]: из pandas.api.types импортировать CategoricalDtype В [27]: s = pd.Series(["a", "b", "c", "a"]) В [28]: cat_type = CategoricalDtype(categories=["b", "c", "d"], order=True) В [29]: s_cat = s.astype(cat_type) В [30]: s_cat Исход[30]: 0 NaN 1 б 2 с 3 NaN тип: категория Категории (3, объект): ['b' < 'c' < 'd']
Аналогично, CategoricalDtype можно использовать с DataFrame , чтобы гарантировать, что категории
согласованы между всеми столбцами.
В [31]: из pandas.api.types импортировать CategoricalDtype
В [32]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")})
В [33]: cat_type = CategoricalDtype(categories=list("abcd"), order=True)
В [34]: df_cat = df.astype(cat_type)
В [35]: df_cat["A"]
Вышли[35]:
0 а
1 б
2 с
3 часа
Имя: A, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
В [36]: df_cat["B"]
Вышел[36]:
0 б
1 с
2 с
3 д
Имя: B, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
Примечание
Для выполнения табличного преобразования, когда все метки во всем DataFrame используются как
категорий для каждого столбца, параметр категорий может быть определен программно путем категории = pd.unique(df.to_numpy().ravel()) .
Если у вас уже есть коды и категории , вы можете использовать from_codes() конструктор для сохранения шага факторизации
в обычном режиме конструктора:
В [37]: splitter = np.
Восстановление исходных данных
Чтобы вернуться к исходному массиву серии или NumPy, используйте Series.astype(original_dtype) или np.asarray(категориальный) :
В [39]: s = pd.Series(["a", "b", "c", "a"])
В [40]: с.
Вышли[40]:
0 а
1 б
2 с
3 часа
тип: объект
В [41]: s2 = s.astype("категория")
В [42]: s2
Вышел[42]:
0 а
1 б
2 с
3 часа
тип: категория
Категории (3, объект): ['a', 'b', 'c']
В [43]: s2.astype(str)
Вышел[43]:
0 а
1 б
2 с
3 часа
тип: объект
В [44]: np.asarray(s2)
Out[44]: массив(['a', 'b', 'c', 'a'], dtype=object)
Примечание
В отличие от функции R factor , категориальные данные не преобразуют входные значения в
струны; категории будут иметь тот же тип данных, что и исходные значения.
Примечание
В отличие от функции R factor , в настоящее время нет возможности назначать/изменять метки в
время создания. Используйте категории для изменения категорий после времени создания.
КатегориальныйDтип
Категориальный тип полностью описан
категории: последовательность уникальных значений без пропущенных значенийзаказанный: логическое значение
Эта информация может храниться в CategoricalDtype .
Аргумент категорий является необязательным, что означает, что фактические категории
должны быть выведены из того, что присутствует в данных, когда pandas.Categorical создан. Предполагается, что категории неупорядочены.
по умолчанию.
В [45]: из pandas.api.types импортировать CategoricalDtype В [46]: CategoricalDtype(["a", "b", "c"]) Out[46]: CategoricalDtype(categories=['a', 'b', 'c'], order=False) В [47]: CategoricalDtype(["a", "b", "c"], order=True) Out[47]: CategoricalDtype(categories=['a', 'b', 'c'], order=True) В [48]: КатегориальныйDtype() Out[48]: CategoricalDtype(categories=None, order=False)
A CategoricalDtype можно использовать в любом месте pandas
ожидает dtype . Например панды.read_csv() , pandas.DataFrame.astype() или в конструкторе серии .
Примечание
Для удобства вы можете использовать строку «категория» вместо CategoricalDtype , если вы хотите, чтобы поведение по умолчанию
категории неупорядочены и равны установленным значениям, присутствующим в
множество. Другими словами, dtype='category' эквивалентно dtype=CategoricalDtype() .
Семантика равенства
Два экземпляра CategoricalDtype сравниваются равными
всякий раз, когда они имеют одинаковые категории и порядок. При сравнении двух
неупорядоченные категории, порядок категорий не учитывается.
В [49]: c1 = CategoricalDtype(["a", "b", "c"], order=False) # Равно, так как порядок не учитывается, если order=False В [50]: c1 == CategoricalDtype(["b", "c", "a"], order=False) Выход[50]: Верно # Неравно, так как второй CategoricalDtype упорядочен В [51]: c1 == CategoricalDtype(["a", "b", "c"], order=True) Исход[51]: Ложь
Все экземпляры CategoricalDtype сравниваются со строкой 'category' .
В [52]: c1 == "категория" Исход[52]: Верно
Предупреждение
Поскольку dtype='category' по сути является CategoricalDtype(None, False) ,
и поскольку все экземпляры CategoricalDtype сравниваются с 'category' ,
все экземпляры CategoricalDtype сравниваются равными КатегориальныйDтип(Нет, Ложь) , независимо от категории или заказал .
Описание
Использование description() для категориальных данных даст аналогичный результат.
вывод в Series или DataFrame типа string .
В [53]: cat = pd.Categorical(["a", "c", "c", np.nan], Categories=["b", "a", "c"])
В [54]: df = pd.DataFrame({"cat": cat, "s": ["a", "c", "c", np.nan]})
В [55]: df.describe()
Вышел[55]:
кот с
считать 3 3
уникальный 2 2
топ с с
частота 2 2
В [56]: df["cat"].describe()
Вышел[56]:
считать 3
уникальный 2
топ с
частота 2
Имя: кошка, dtype: объект
Работа с категориями
Категориальные данные имеют категорий и упорядоченных свойства, которые перечисляют их
возможных значений и имеет ли значение порядок или нет. Эти свойства
выставлен как s.cat.categories и s.cat.ordered . Если вы не вручную
укажите категории и порядок, они выводятся из переданных аргументов.
В [57]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [58]: s.cat.categories Out[58]: Index(['a', 'b', 'c'], dtype='object') В [59]: s.cat.ordered Исход[59]: Ложь
Также возможно проходить категории в определенном порядке:
В [60]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], Categories=["c", "b", "a"]) ) В [61]: s.cat.categories Out[61]: Index(['c', 'b', 'a'], dtype='object') В [62]: s.cat.ordered Исход[62]: Ложь
Примечание
Новые категориальные данные не упорядочиваются автоматически. Вы должны явно
pass ordered=True для обозначения заказанного Категориальный .
Примечание
Результат unique() не всегда совпадает с Series.cat.categories ,
потому что Series. имеет пару гарантий, а именно то, что он возвращает категории
в порядке появления и включает только те значения, которые действительно присутствуют. unique()
В [63]: s = pd.Series(list("babc")).astype(CategoricalDtype(list("abcd")))
В [64]: с
Вышел[64]:
0 б
1 год
2 б
3 с
тип: категория
Категории (4, объект): ['a', 'b', 'c', 'd']
# категории
В [65]: s.cat.categories
Out[65]: Index(['a', 'b', 'c', 'd'], dtype='object')
# уникальные
В [66]: s.unique()
Вышел[66]:
['б', 'а', 'в']
Категории (4, объект): ['a', 'b', 'c', 'd']
Переименование категорий
Переименование категорий выполняется путем присвоения новых значений Series.cat.categories или с помощью свойства rename_categories() метод:
В [67]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [68]: с Вышел[68]: 0 а 1 б 2 с 3 часа тип: категория Категории (3, объект): ['a', 'b', 'c'] В [69]: s.cat.categories = ["Группа %s" % g для g в s.cat.categories] В [70]: с.
Note
В отличие от R factor , категориальные данные могут иметь категории других типов, кроме строк.
Примечание
Имейте в виду, что назначение новых категорий является операцией на месте, в то время как большинство других операций
под Series.cat по умолчанию возвращает новый Series dtype категории .
Категории должны быть уникальными, иначе возникает ошибка ValueError :
В [75]: попробуйте: .
Категории также не должны быть NaN или ValueError :
В [76]: попробуйте:
....: s.cat.categories = [1, 2, np.nan]
....: кроме ValueError как e:
....: print("ValueError:", str(e))
....:
ValueError: категориальные категории не могут быть нулевыми
Добавление новых категорий
Добавление категорий может быть выполнено с помощью метод add_categories() :
В [77]: s = s.cat.add_categories([4]) В [78]: s.cat.categories Out[78]: Index(['x', 'y', 'z', 4], dtype='object') В [79]: с Вышел[79]: 0 х 1 год 2 з 3 х тип: категория Категории (4, объект): ['x', 'y', 'z', 4]
Удаление категорий
Удаление категорий можно выполнить с помощью метод remove_categories() . Ценности, которые удаляются
заменяются на np..: nan
В [80]: s = s.cat.remove_categories([4]) В [81]: с Вышел[81]: 0 х 1 год 2 з 3 х тип: категория Категории (3, объект): ['x', 'y', 'z']
Удаление неиспользуемых категорий
Также можно удалить неиспользуемые категории:
В [82]: s = pd.Series(pd.Categorical(["a", "b", "a"], Categories=["a", "b", "c", "d"]) ) В [83]: с Вышел[83]: 0 а 1 б 2 часа тип: категория Категории (4, объект): ['a', 'b', 'c', 'd'] В [84]: s.cat.remove_unused_categories() Вышел[84]: 0 а 1 б 2 часа тип: категория Категории (2, объект): ['a', 'b']
Категории настроек
Если вы хотите удалить и добавить новые категории за один шаг (который имеет некоторые
преимущество в скорости) или просто установите категории в предопределенный масштаб,
использовать set_categories() .
В [85]: s = pd.Series(["один", "два", "четыре", "-"], dtype="category") В [86]: с Вышел[86]: 0 один 1 два 2 четыре 3 - тип: категория Категории (4, объект): ['-', 'четыре', 'один', 'два'] В [87]: s = s.
Примечание
Имейте в виду, что Categorical.set_categories() не может знать, пропущена ли какая-либо категория
преднамеренно или потому, что в нем написана ошибка, или (в Python3) из-за различия типов (например,
NumPy S1 dtype и строки Python). Это может привести к неожиданному поведению!
Сортировка и заказ
Если категориальные данные упорядочены ( s.cat.ordered == True ), то порядок категорий имеет
значение и определенные операции возможны. Если категориальное неупорядочено, .min()/.max() вызовет TypeError .
В [89]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], order=False)) В [90]: s.sort_values(inplace=True) В [91]: s = pd.Series(["a", "b", "c", "a"]).astype(CategoricalDtype(ordered=True)) В [92]: s.
Вы можете установить упорядочение категорийных данных с помощью as_ordered() или неупорядоченный с помощью as_unordered() . Это будет
по умолчанию возвращает новый объект .
В [95]: s.cat.as_ordered() Вышел[95]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a' < 'b' < 'c'] В [96]: s.cat.as_unordered() Вышел[96]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a', 'b', 'c']
Сортировка будет использовать порядок, определенный категориями, а не любой лексический порядок, присутствующий в типе данных. Это верно даже для строк и числовых данных:
В [97]: s = pd.Series([1, 2, 3, 1], dtype="category") В [98]: s = s.cat.set_categories([2, 3, 1], order=True) В [99]: с Вышли[99]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [100]: s.
Повторный заказ
Изменение порядка категорий возможно через Категориальная.reorder_categories() и метода Categorical.set_categories() . Для Categorical.reorder_categories() все
старые категории должны быть включены в новые категории, и никакие новые категории не допускаются. Это будет
обязательно сделайте порядок сортировки таким же, как порядок категорий.
В [103]: s = pd.Series([1, 2, 3, 1], dtype="category") В [104]: s = s.cat.reorder_categories([2, 3, 1], order=True) В [105]: с Выход[105]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [106]: s.sort_values(inplace=True) В [107]: с Выход[107]: 1 2 2 3 0 1 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [108]: s.min(), s.max() Исход[108]: (2, 1)
Примечание
Обратите внимание на разницу между назначением новых категорий и изменением порядка категорий: первая
переименовывает категории и, следовательно, отдельные значения в серии , но если первый
позиция была отсортирована последней, переименованное значение все равно будет отсортировано последним. Переупорядочивание означает, что
способ сортировки значений впоследствии отличается, но не отдельные значения в Серия изменена.
Примечание
Если Категория не заказан, Series.min() и Series.max() поднимет Типовая ошибка . Числовые операции типа +, -, *, / и операции на их основе
(например, Series.median() , который должен был бы вычислить среднее между двумя значениями, если длина
массива четные) не работают и поднимают TypeError .
Сортировка по нескольким столбцам
Категориальный столбец dtyped будет участвовать в многостолбцовой сортировке аналогично другим столбцам.
Порядок категориального определяется категории этого столбца.
В [109]: dfs = pd.DataFrame(
.....: {
.....: "A": pd.Категорический(
.....: список("ббиббаа"),
.....: категории=["е", "а", "б"],
. ....: заказано=Истина,
.....: ),
.....: "В": [1, 2, 1, 2, 2, 1, 2, 1],
.....: }
.....: )
.....:
В [110]: dfs.sort_values(by=["A", "B"])
Выход[110]:
А Б
2 е 1
3 е 2
7 в 1
6 в 2
0 б 1
5 б 1
1 б 2
4 б 2
Изменение порядка категорий изменяет будущую сортировку.
В [111]: dfs["A"] = dfs["A"].cat.reorder_categories(["a", "b", "e"]) В [112]: dfs.sort_values(by=["A", "B"]) Выход[112]: А Б 7 в 1 6 в 2 0 б 1 5 б 1 1 б 2 4 б 2 2 е 1 3 е 2
Сравнения
Сравнение категорийных данных с другими объектами возможно в трех случаях:
Сравнение равенства (
==и!=) с объектом, подобным списку (список, серия, массив, …) той же длины, что и категориальные данные.Все сравнения (
==,!=,>,>=,<и<=) категориальных данных с другой категориальный ряд, когдазаказал == Правдаикатегорииодинаковы.Все сравнения категориальных данных со скаляром.
Все другие сравнения, особенно сравнения «не на равенство» двух категорий с разными
категории или категориальный с любым объектом, подобным списку, поднимет Ошибка типа .
Примечание
Любые «неравенские» сравнения категорийных данных с Series , np.array , list или
категориальные данные с разными категориями или порядком вызовут TypeError , потому что пользовательские
порядок категорий можно интерпретировать двояко: один с учетом
заказ и один без.
В [113]: cat = pd.Series([1, 2, 3]).astype(CategoricalDtype([3, 2, 1], order=True)) В [114]: cat_base = pd.Series([2, 2, 2]).astype(CategoricalDtype([3, 2, 1], order=True)) В [115]: cat_base2 = pd.Series([2, 2, 2]).astype(CategoricalDtype(ordered=True)) В [116]: кошка Выход[116]: 0 1 1 2 2 3 тип: категория Категории (3, int64): [3 < 2 < 1] В [117]: cat_base Выход[117]: 0 2 1 2 2 2 тип: категория Категории (3, int64): [3 < 2 < 1] В [118]: cat_base2 Выход[118]: 0 2 1 2 2 2 тип: категория Категории (1, int64): [2]
Сравнение с категориальным с теми же категориями и порядком или со скалярным работает:
В [119]: кошка > cat_base Выход[119]: 0 Верно 1 Ложь 2 Ложь тип: логический В [120]: кошка > 2 Выход[120]: 0 Верно 1 Ложь 2 Ложь тип: логический
Сравнение на равенство работает с любым спискообразным объектом одинаковой длины и скаляров:
В [121]: cat == cat_base Выход[121]: 0 Ложь 1 правда 2 Ложь тип: логический В [122]: cat == np.
Это не работает, потому что категории не совпадают:
В [124]: попробуйте:
.....: кошка > cat_base2
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: Категориалы можно сравнивать только в том случае, если «категории» одинаковы.
Если вы хотите выполнить сравнение «неравенства» категориального ряда со спископодобным объектом которые не являются категориальными данными, вам нужно быть явным и преобразовать категориальные данные обратно в исходные значения:
В [125]: база = np.array([1, 2, 3])
В [126]: попробуйте:
.....: кошка > база
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно сравнить категориальное для op __gt__ с типом .
Если вы хотите сравнить значения, используйте «np.asarray(cat) other».
В [127]: np.asarray(cat) > base
Выход[127]: массив([Ложь, Ложь, Ложь])
При сравнении двух неупорядоченных категорий с одинаковыми категориями порядок не учитывается:
В [128]: c1 = pd.Categorical(["a", "b"], Categories=["a", "b"], order=False) В [129]: c2 = pd.Categorical(["a", "b"], Categories=["b", "a"], order=False) В [130]: с1 == с2 Выход[130]: массив([Истина, Истина])
Операции
Помимо Series.min() , Series.max() и Series.mode() ,
следующие операции возможны с категориальными данными:
Методы Series , такие как Series.value_counts() будет использовать все категории,
даже если некоторые категории отсутствуют в данных:
В [131]: s = pd.Series(pd.Categorical(["a", "b", "c", "c"], Categories=["c", "a", "b", " д"])) В [132]: s.value_counts() Выход[132]: с 2 1 б 1 д 0 тип: int64
Методы DataFrame , такие как DataFrame., также показывают «неиспользуемые» категории. sum()
В [133]: columns = pd.Categorical( .....: ["Один", "Один", "Два"], category=["Один", "Два", "Три"], order=True .....: ) .....: В [134]: df = pd.DataFrame( .....: данные=[[1, 2, 3], [4, 5, 6]], .....: столбцы = pd.MultiIndex.from_arrays ([["A", "B", "B"], столбцы]), .....: ) .....: В [135]: df.groupby(ось=1, уровень=1).sum() Выход[135]: Раз два три 0 3 3 0 1 96 0
Groupby также покажет «неиспользуемые» категории:
В [136]: кошки = pd.Categorical(
.....: ["a", "b", "b", "b", "c", "c", "c"], category=["a", "b", "c" , "д"]
.....: )
.....:
В [137]: df = pd.DataFrame({"кошки": кошки, "значения": [1, 2, 2, 2, 3, 4, 5]})
В [138]: df.groupby("кошки").mean()
Исход[138]:
ценности
кошки
1,0
б 2.0
с 4.0
г NaN
В [139]:cats2 = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c"])
В [140]: df2 = pd.DataFrame(
.....: {
.....: "коты": коты2,
.....: "В": ["в", "д", "в", "д"],
. ....: "значения": [1, 2, 3, 4],
.....: }
.....: )
.....:
В [141]: df2.groupby(["кошки", "B"]).mean()
Выход[141]:
ценности
кошки Б
а в 1,0
д 2.0
б в 3,0
д 4,0
в в NaN
г NaN
Сводные таблицы:
В [142]: raw_cat = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c"])
В [143]: df = pd.DataFrame({"A": raw_cat, "B": ["c", "d", "c", "d"], "values": [1, 2, 3 , 4]})
В [144]: pd.pivot_table(df, values="values", index=["A", "B"])
Исход[144]:
ценности
А Б
а с 1
д 2
б в 3
д 4
Фальсификация данных
Оптимизированные методы доступа к данным pandas .loc , .iloc , .at и .iat ,
работать как обычно. Единственная разница заключается в типе возврата (для получения) и
что только значения уже в категориях могут быть назначены.
Получение
Если операция среза возвращает либо DataFrame , либо столбец типа Series , сохраняется категория dtype.
В [145]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n"])
В [146]: кошки = pd.Series(["a", "b", "b", "b", "c", "c", "c"], dtype="category", index=idx )
В [147]: значения = [1, 2, 2, 2, 3, 4, 5]
В [148]: df = pd.DataFrame({"кошки": кошки, "значения": значения}, index=idx)
В [149]: df.iloc[2:4, :]
Исход[149]:
кошачьи ценности
дж б 2
к б 2
В [150]: df.iloc[2:4, :].dtypes
Выход[150]:
категория кошек
значения int64
тип: объект
В [151]: df.loc["h":"j", "кошки"]
Выход[151]:
ч а
я б
дж б
Имя: кошки, dtype: категория
Категории (3, объект): ['a', 'b', 'c']
В [152]: df[df["кошки"] == "b"]
Выход[152]:
кошачьи ценности
я б 2
дж б 2
к б 2
Пример, когда тип категории не сохраняется, если взять один единственный
ряд: получившаяся Серия относится к объекту dtype :
# получить полную строку "h" в виде серии В [153]: df.loc["h", :] Исход[153]: кошки а значения 1 Имя: h, dtype: объект
При возврате одного элемента из категориальных данных также будет возвращено значение, а не категориальный
длины «1».
В [154]: df.iat[0, 0] Ушел[154]: 'а' В [155]: df["cats"].cat.categories = ["x", "y", "z"] В [156]: df.at["h", "cats"] # возвращает строку Выход[156]: 'x'
Примечание
В отличие от функции R factor , где factor(c(1,2,3))[1] возвращает одно значение фактор .
Чтобы получить одно значение Series типа категории , вы передаете список с
одно значение:
В [157]: df.loc[["h"], "кошки"] Вышли[157]: ч х Имя: кошки, dtype: категория Категории (3, объект): ['x', 'y', 'z']
Средства доступа к строке и дате/времени
Аксессуары .dt и .str будет работать, если s.cat.categories имеют
соответствующий тип:
В [158]: str_s = pd.Series(list("aabb"))
В [159]: str_cat = str_s.astype("категория")
В [160]: str_cat
Выход[160]:
0 а
1 год
2 б
3 б
тип: категория
Категории (2, объект): ['a', 'b']
В [161]: str_cat. str.contains("a")
Исход[161]:
0 Верно
1 правда
2 Ложь
3 Ложь
тип: логический
В [162]: date_s = pd.Series(pd.date_range("1/1/2015", периоды=5))
В [163]: date_cat = date_s.astype("категория")
В [164]: date_cat
Исход[164]:
0 01.01.2015
1 2015-01-02
2 2015-01-03
3 2015-01-04
4 2015-01-05
тип: категория
Категории (5, datetime64[ns]): [2015-01-01, 2015-01-02, 2015-01-03, 2015-01-04, 2015-01-05]
В [165]: date_cat.dt.day
Исход[165]:
0 1
1 2
2 3
3 4
4 5
тип: int64
Примечание
Возвращенный Series (или DataFrame ) имеет тот же тип, что и при использовании .str.<метод> / .dt.<метод> на серии этого типа (и не
тип категория !).
Это означает, что возвращаемые значения из методов и свойств методов доступа Серия и возвращаемые значения из методов и свойств средств доступа этого Серия преобразована в тип категория будет равна:
В [166]: ret_s = str_s.
Примечание
Работа выполняется на категории , а затем создается новая серия . Это имеет
некоторое влияние на производительность, если у вас есть Series типа string, где много элементов
повторяются (т.е. количество уникальных элементов в Серия намного меньше, чем
длина серии ). В этом случае может быть быстрее преобразовать исходный серии к одному из типов категории и используйте для этого .str.<метод> или .dt.<свойство> .
Настройка
Установка значений в категориальном столбце (или Серия ) работает до тех пор, пока
значение включено в категории :
В [170]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n"]) В [171]: кошки = pd.
Установка значений путем присвоения категориальных данных также проверяет соответствие категорий :
В [177]: df.loc["j":"k", "cats"] = pd.Categorical(["a", "a"], Categories=["a", "b"]) В [178]: дф Вышли[178]: кошачьи ценности ч а 1 я 1 Дж а 2 к а 2 л а 1 м а 1 п а 1 В [179]: попробуйте: .....: df.loc["j":"k", "кошки"] = pd.Categorical(["b", "b"], Categories=["a", "b", "c "]) .
При присвоении Категориального частям столбца других типов будут использоваться значения:
В [180]: df = pd.DataFrame({"a": [1, 1, 1, 1, 1], "b": ["a", "a", "a", "a", "а"]})
В [181]: df.loc[1:2, "a"] = pd.Categorical(["b", "b"], Categories=["a", "b"])
В [182]: df.loc[2:3, "b"] = pd.Categorical(["b", "b"], Categories=["a", "b"])
В [183]: дф
Исход[183]:
а б
0 1 а
1 б а
2 б б
3 1 б
4 1 а
В [184]: df.dtypes
Исход[184]:
объект
б объект
тип: объект
Слияние/объединение
По умолчанию объединение Series или DataFrames , которые содержат одинаковые
категории приводит к категории dtype, в противном случае результаты будут зависеть от
dtype базовых категорий. Слияния, которые приводят к некатегоричности
dtypes, вероятно, будут использовать больше памяти. Используйте .astype или union_categoricals для обеспечения результатов категории .
В [185]: из pandas.api.types import union_categoricals
# те же категории
В [186]: s1 = pd.Series(["a", "b"], dtype="category")
В [187]: s2 = pd.Series(["a", "b", "a"], dtype="category")
В [188]: pd.concat([s1, s2])
Вышли[188]:
0 а
1 б
0 а
1 б
2 часа
тип: категория
Категории (2, объект): ['a', 'b']
# разные категории
В [189]: s3 = pd.Series(["b", "c"], dtype="category")
В [190]: pd.concat([s1, s3])
Выход[190]:
0 а
1 б
0 б
1 с
тип: объект
# Выходной dtype выводится на основе значений категорий
В [191]: int_cats = pd.Series([1, 2], dtype="category")
В [192]: float_cats = pd.Series([3.0, 4.0], dtype="category")
В [193]: pd.concat([int_cats, float_cats])
Исход[193]:
0 1,0
1 2,0
0 3,0
1 4,0
тип: float64
В [194]: pd.concat([s1, s3]).astype("категория")
Исход[194]:
0 а
1 б
0 б
1 с
тип: категория
Категории (3, объект): ['a', 'b', 'c']
В [195]: union_categoricals([s1. array, s3.array])
Вышли[195]:
['а', 'б', 'б', 'в']
Категории (3, объект): ['a', 'b', 'c']
В следующей таблице приведены результаты объединения категорий :
арг1 | аргумент2 | идентичный | результат |
|---|---|---|---|
категория | категория | Правда | категория |
категория (объект) | категория (объект) | Ложь | объект (выводится dtype) |
категория (внутренняя) | категория (плавающая) | Ложь | с плавающей запятой (предполагается dtype) |
См. также раздел о типах слияния для заметок о
сохранение типов слияния и производительности.
Объединение
Если вы хотите объединить категории, которые не обязательно имеют одинаковые
категории, функция union_categoricals() будет
объединить список подобных категорий. Новые категории будут представлять собой объединение
категории объединяются.
В [196]: из pandas.api.types import union_categoricals В [197]: a = pd.Categorical(["b", "c"]) В [198]: b = pd.Categorical(["a", "b"]) В [199]: union_categoricals([a, b]) Вышли[199]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a']
По умолчанию результирующие категории будут упорядочены как
они появляются в данных. Если вы хотите, чтобы категории
для лексической сортировки используйте аргумент sort_categories=True .
В [200]: union_categoricals([a, b], sort_categories=True) Выход[200]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals также работает с «простым» случаем объединения двух
категории тех же категорий и информация о заказе
(например, что вы могли бы также добавить для).
В [201]: a = pd.Categorical(["a", "b"], order=True) В [202]: b = pd.Categorical(["a", "b", "a"], order=True) В [203]: union_categoricals([a, b]) Выход[203]: ['а', 'б', 'а', 'б', 'а'] Категории (2, объект): ['a' < 'b']
Приведенное ниже вызывает TypeError , поскольку категории упорядочены и не идентичны.
В [1]: a = pd.Categorical(["a", "b"], order=True) В [2]: b = pd.Categorical(["a", "b", "c"], order=True) В [3]: union_categoricals([a, b]) Выход[3]: TypeError: для объединения упорядоченных категорий все категории должны быть одинаковыми
Упорядоченные категориальные элементы с разными категориями или порядками можно комбинировать с помощью
используя аргумент ignore_ordered=True .
В [204]: a = pd.Categorical(["a", "b", "c"], order=True) В [205]: b = pd.Categorical(["c", "b", "a"], order=True) В [206]: union_categoricals([a, b], ignore_order=True) Исход[206]: ['а', 'б', 'в', 'в', 'б', 'а'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals() также работает с Категориальный индекс или Серия , содержащая категориальные данные, но обратите внимание, что
результирующий массив всегда будет простым Категориальный :
В [207]: a = pd.
Примечание
union_categoricals может перекодировать целые коды для категорий
при объединении категорий. Это, вероятно, то, что вы хотите,
но если вы полагаетесь на точную нумерацию категорий, будьте
осведомленный.
В [210]: c1 = pd.Categorical(["b", "c"]) В [211]: c2 = pd.Categorical(["a", "b"]) В [212]: с1 Выход[212]: ['до н.э'] Категории (2, объект): ['b', 'c'] # "b" кодируется как 0 В [213]: c1.codes Выход[213]: массив([0, 1], dtype=int8) В [214]: с2 Выход[214]: ['а', 'б'] Категории (2, объект): ['a', 'b'] # "b" кодируется как 1 В [215]: c2.codes Выход[215]: массив([0, 1], dtype=int8) В [216]: c = union_categoricals([c1, c2]) В [217]: в Выход[217]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a'] # "b" везде кодируется как 0, так же, как c1, но отличается от c2 В [218]: c.
Получение/вывод данных
Вы можете записать данные, содержащие категории dtypes, в хранилище HDFStore .
См. здесь пример и предостережения.
Также можно записывать данные и считывать данные из файлов формата Stata . См. здесь пример и предостережения.
Запись в CSV-файл преобразует данные, эффективно удаляя любую информацию о
категориальные (категории и порядок). Поэтому, если вы читаете файл CSV, вам нужно преобразовать
соответствующие столбцы назад к категория и назначьте правильные категории и порядок категорий.
В [219]: импорт io В [220]: s = pd.Series(pd.Categorical(["a", "b", "b", "a", "a", "d"])) # переименовать категории В [221]: s.cat.categories = ["очень хорошо", "хорошо", "плохо"] # изменить порядок категорий и добавить недостающие категории В [222]: s = s.cat.set_categories(["очень плохо", "плохо", "средне", "хорошо", "очень хорошо"]) В [223]: df = pd.
То же самое верно для записи в базу данных SQL с to_sql .
Отсутствуют данные
pandas в основном использует значение np.nan для представления отсутствующих данных. Это по
по умолчанию не включены в расчеты. См. раздел «Отсутствующие данные».
Отсутствующие значения должны быть включены , а не в категории категории ,
только в значения .
Вместо этого понятно, что NaN отличается и всегда возможен.
При работе с Категориальным коды , пропущенные значения всегда будут
код -1 .
В [233]: s = pd.Series(["a", "b", np.nan, "a"], dtype="category") # только две категории В [234]: с Выход[234]: 0 а 1 б 2 NaN 3 часа тип: категория Категории (2, объект): ['a', 'b'] В [235]: s.cat.codes Выход[235]: 0 0 1 1 2 -1 3 0 тип: int8
Методы работы с отсутствующими данными, т.е. исна () , заполнение () , dropna() , все работает нормально:
В [236]: s = pd.Series(["a", "b", np.
Отличия от фактора R
Можно наблюдать следующие отличия функций фактора R:
уровней Rназваныкатегориями.Уровни
Rвсегда имеют строковый тип, а категорииНевозможно указать метки во время создания. Используйте
s.cat.rename_categories(new_labels)после.В отличие от функции R
factor, использование категориальных данных в качестве единственного входа для создания новая категорийная серия будет , а не удалить неиспользуемые категории, но создать новый категориальный ряд что равно переданному за единицу!R позволяет включать отсутствующие значения в свои
уровней(категории pandas). панды
не допускает категорий NaN, но пропущенные значения все еще могут быть в значениях
Гочки
Использование памяти
Использование памяти Категорий пропорционально количеству категорий плюс длина данных. Наоборот, объект dtype — это константа, умноженная на длину данных.
В [240]: s = pd.Series(["foo", "bar"] * 1000)
# тип объекта
В [241]: s.nbytes
Выход[241]: 16000
# категория dtype
В [242]: s.astype("category").nbytes
Вышло[242]: 2016 г.
Примечание
Если количество категорий приближается к длине данных, Категориальный будет использовать почти такое же или
больше памяти, чем эквивалентное представление объекта dtype.
В [243]: s = pd.Series(["foo%04d" % i для i в диапазоне (2000)])
# тип объекта
В [244]: s.nbytes
Выход[244]: 16000
# категория dtype
В [245]: s.astype("category").nbytes
Выход[245]: 20000
Категориальный не является массивом numpy В настоящее время категориальные данные и базовый категориальный реализованы как Python
объект, а не как низкоуровневый массив NumPy dtype. Это приводит к некоторым проблемам.
Сам NumPy не знает о новом dtype :
В [246]: попробуйте:
.....: np.dtype ("категория")
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: тип данных «категория» не понят
В [247]: dtype = pd.Categorical(["a"]).dtype
В [248]: попробуйте:
.....: np.dtype(dtype)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно интерпретировать «CategoricalDtype (categories = ['a'], Ordered = False)» как тип данных
Сравнения Dtype работают:
В [249]: dtype == np.str_ Выход[249]: Ложь В [250]: np.str_ == dtype Выход[250]: Ложь
Чтобы проверить, содержит ли серия категориальные данные, используйте hasattr(s, 'cat') :
В [251]: hasattr(pd.Series(["a"], dtype="category"), "cat") Выход[251]: Истина В [252]: hasattr(pd.Series(["a"]), "cat") Выход[252]: Ложь
Использование функций NumPy на серии типа категории не должно работать как Категории не являются числовыми данными (даже в том случае, если . является числовым). categories
В [253]: s = pd.Series(pd.Categorical([1, 2, 3, 4]))
В [254]: попробуйте:
.....: np.sum(s)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: «Категория» с категорией dtype не поддерживает сокращение «сумма»
Примечание
Если такая функция работает, сообщите об ошибке на https://github.com/pandas-dev/pandas!
dtype в приложении
pandas в настоящее время не сохраняет dtype в функциях применения: если вы применяете вдоль строк, вы получаете
a Series of object dtype (так же, как получение строки -> получение одного элемента вернет
базовый тип) и применение вдоль столбцов также преобразуется в объект. NaN Значения не изменяются.
Вы можете использовать fillna для обработки пропущенных значений перед применением функции.
В [255]: df = pd.DataFrame(
.....: {
.....: "а": [1, 2, 3, 4],
. ....: "б": ["а", "б", "в", "д"],
.....: "кошки": pd.Categorical([1, 2, 3, 2]),
.....: }
.....: )
.....:
В [256]: df.apply(лямбда-строка: тип(строка["кошки"]), ось=1)
Исход[256]:
0 <класс 'целое число'>
1 <класс 'целое число'>
2 <класс 'целое число'>
3 <класс 'целое число'>
тип: объект
В [257]: df.apply(лямбда-столбец: col.dtype, ось=0)
Исход[257]:
int64
б объект
категория кошек
тип: объект
Категориальный индекс
CategoricalIndex — тип индекса, полезный для поддержки
индексация с дубликатами. Это контейнер вокруг категории и позволяет эффективно индексировать и хранить индекс с большим количеством повторяющихся элементов.
Более подробные сведения см. в документации по расширенному индексированию.
объяснение.
Установка индекса создаст CategoricalIndex :
В [258]: кошки = pd.Categorical([1, 2, 3, 4], Categories=[4, 2, 3, 1]) В [259]: строки = ["a", "b", "c", "d"] В [260]: значения = [4, 2, 3, 1] В [261]: df = pd.
Побочные эффекты
Создание серии из Категориальный не будет копировать ввод Категориальный . Это означает, что изменения в серии в большинстве случаев
изменить исходный Категориальный :
В [264]: cat = pd.Categorical([1, 2, 3, 10], Categories=[1, 2, 3, 4, 10]) В [265]: s = pd.Series(cat, name="cat") В [266]: кошка Исход[266]: [1, 2, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [267]: s.iloc[0:2] = 10 В [268]: кошка Исход[268]: [10, 10, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [269]: df = pd.DataFrame(s) В [270]: df["cat"].cat.categories = [1, 2, 3, 4, 5] В [271]: кошка Исход[271]: [10, 10, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10]
Используйте copy=True , чтобы предотвратить такое поведение или просто не используйте повторно Категориалы :
В [272]: cat = pd.
Примечание
Это также происходит в некоторых случаях, когда вы предоставляете массив NumPy вместо Категориальный :
использование массива int (например, np.array([1,2,3,4]) ) будет демонстрировать такое же поведение, при использовании
массив строк (например, np.array(["a","b","c","a"]) ) не будет.
Категориальные данные — документация pandas 1.6.0.dev0+130.gfaa81145cd
Это введение в категориальный тип данных pandas, включая краткое сравнение
с R фактор .
Categoricals — это тип данных pandas, соответствующий категориальным переменным в
статистика. Категориальная переменная принимает ограниченное и обычно фиксированное значение. количество возможных значений ( категории ; уровня в R). Примеры: пол,
социальный класс, группа крови, принадлежность к стране, время наблюдения или рейтинг через
шкалы Лайкерта.
В отличие от статистических категориальных переменных, категориальные данные могут иметь порядок (например, «полностью согласен» против «согласен» или «первое наблюдение» против «второго наблюдения»), но числовые операции (сложения, деления и т. д.) невозможны.
Все значения категорийных данных находятся либо в категориях , либо в np.nan . Порядок определяется
порядок категории , не лексический порядок значений. Внутренняя структура данных
состоит из массива категорий и целочисленного массива кодов , которые указывают на реальное значение в
массив категорий .
Категориальный тип данных полезен в следующих случаях:
Строковая переменная, состоящая всего из нескольких различных значений.
Преобразование такой строки
переменная в категориальную переменную сэкономит немного памяти, см. здесь.Лексический порядок переменной не совпадает с логическим («один», «два», «три»). Путем преобразования в категориальный и указания порядка категорий, сортировки и min/max будет использовать логический порядок вместо лексического, см. здесь.
Как сигнал другим библиотекам Python, что этот столбец следует рассматривать как категориальный переменной (например, для использования подходящих статистических методов или типов графиков).
См. также документацию API по категориям.
Создание объекта
Создание серии
Категориальный Серия или столбцы в DataFrame могут быть созданы несколькими способами:
Путем указания dtype="category" при построении серии :
В [1]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [2]: с Выход[2]: 0 а 1 б 2 с 3 часа тип: категория Категории (3, объект): ['a', 'b', 'c']
Путем преобразования существующих Серия или столбец категории dtype:
В [3]: df = pd.
С помощью специальных функций, таких как cut() , которая группирует данные в
дискретные бункеры. См. пример тайлинга в документации.
В [6]: df = pd.DataFrame({"значение": np.random.randint(0, 100, 20)})
В [7]: labels = ["{0} - {1}".format(i, i + 9) для i в диапазоне (0, 100, 10)]
В [8]: df["group"] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels)
В [9]: df.head(10)
Выход[9]:
группа значений
0 65 60 - 69
1 49 40 - 49
2 56 50 - 59
3 43 40 - 49
4 43 40 - 49
5 91 90 - 99
6 32 30 - 39
7 87 80 - 89
8 36 30 - 39
9 8 0 - 9
Передав объект pandas.Categorical серии или назначив его DataFrame .
В [10]: raw_cat = pd.Categorical( ....: ["a", "b", "c", "a"], Categories=["b", "c", "d"], order=False .... :) ....: В [11]: s = pd.Series(raw_cat) В [12]: с Выход[12]: 0 NaN 1 б 2 с 3 NaN тип: категория Категории (3, объект): ['b', 'c', 'd'] В [13]: df = pd.
Категориальные данные имеют определенную категорию dtype:
В [16]: df.dtypes Вышли[16]: Объект категория Б тип: объект
Создание кадра данных
Аналогично предыдущему разделу, где один столбец был преобразован в категориальный, все столбцы в DataFrame может быть пакетно преобразован в категориальный во время или после построения.
Это можно сделать во время строительства, указав dtype="category" в DataFrame конструктор:
В [17]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")}, dtype="category")
В [18]: df.dtypes
Вышли[18]:
Категория
категория Б
тип: объект
Обратите внимание, что категории в каждом столбце различаются; преобразование выполняется столбец за столбцом, поэтому только ярлыки, присутствующие в данном столбце, являются категориями:
В [19]: df["A"] Вышли[19]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [20]: df["B"] Исход[20]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Аналогично, все столбцы в существующем DataFrame могут быть преобразованы в пакетном режиме с использованием DataFrame. : astype()
В [21]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")})
В [22]: df_cat = df.astype("категория")
В [23]: df_cat.dtypes
Вышли[23]:
Категория
категория Б
тип: объект
Это преобразование также выполняется столбец за столбцом:
В [24]: df_cat["A"] Вышли[24]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [25]: df_cat["B"] Вышли[25]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Управление поведением
В приведенных выше примерах, где мы передали dtype='category' , мы использовали значение по умолчанию
поведение:
Категории выводятся из данных.
Категории неупорядочены.
Чтобы управлять этим поведением, вместо передачи «категории» используйте экземпляр
из КатегориальныйDтип .
В [26]: из pandas.api.types импортировать CategoricalDtype В [27]: s = pd.
Аналогично, CategoricalDtype можно использовать с DataFrame , чтобы гарантировать, что категории
согласованы между всеми столбцами.
В [31]: из pandas.api.types импортировать CategoricalDtype
В [32]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")})
В [33]: cat_type = CategoricalDtype(categories=list("abcd"), order=True)
В [34]: df_cat = df.astype(cat_type)
В [35]: df_cat["A"]
Вышли[35]:
0 а
1 б
2 с
3 часа
Имя: A, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
В [36]: df_cat["B"]
Вышел[36]:
0 б
1 с
2 с
3 д
Имя: B, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
Примечание
Для выполнения табличного преобразования, когда все метки во всем DataFrame используются как
категорий для каждого столбца, параметр категорий может быть определен программно путем категории = pd. . unique(df.to_numpy().ravel())
Если у вас уже есть коды и категории , вы можете использовать from_codes() конструктор для сохранения шага факторизации
в обычном режиме конструктора:
В [37]: splitter = np.random.choice([0, 1], 5, p=[0,5, 0,5]) В [38]: s = pd.Series(pd.Categorical.from_codes(splitter, category=["train", "test"]))
Восстановление исходных данных
Чтобы вернуться к исходному массиву серии или NumPy, используйте Series.astype(original_dtype) или np.asarray(категориальный) :
В [39]: s = pd.Series(["a", "b", "c", "a"])
В [40]: с.
Вышли[40]:
0 а
1 б
2 с
3 часа
тип: объект
В [41]: s2 = s.astype("категория")
В [42]: s2
Вышел[42]:
0 а
1 б
2 с
3 часа
тип: категория
Категории (3, объект): ['a', 'b', 'c']
В [43]: s2.astype(str)
Вышел[43]:
0 а
1 б
2 с
3 часа
тип: объект
В [44]: np.asarray(s2)
Out[44]: массив(['a', 'b', 'c', 'a'], dtype=object)
Примечание
В отличие от функции R factor , категориальные данные не преобразуют входные значения в
струны; категории будут иметь тот же тип данных, что и исходные значения.
Примечание
В отличие от функции R factor , в настоящее время нет возможности назначать/изменять метки в
время создания. Используйте категории для изменения категорий после времени создания.
КатегориальныйDтип
Категориальный тип полностью описан
категории: последовательность уникальных значений без пропущенных значенийзаказанный: логическое значение
Эта информация может храниться в CategoricalDtype .
Аргумент категорий является необязательным, что означает, что фактические категории
должны быть выведены из того, что присутствует в данных, когда pandas.Categorical создан. Предполагается, что категории неупорядочены.
по умолчанию.
В [45]: из pandas.api.types импортировать CategoricalDtype В [46]: CategoricalDtype(["a", "b", "c"]) Out[46]: CategoricalDtype(categories=['a', 'b', 'c'], order=False) В [47]: CategoricalDtype(["a", "b", "c"], order=True) Out[47]: CategoricalDtype(categories=['a', 'b', 'c'], order=True) В [48]: КатегориальныйDtype() Out[48]: CategoricalDtype(categories=None, order=False)
A CategoricalDtype можно использовать в любом месте pandas
ожидает dtype . Например панды.read_csv() , pandas.DataFrame.astype() или в конструкторе серии .
Примечание
Для удобства вы можете использовать строку «категория» вместо CategoricalDtype , если вы хотите, чтобы поведение по умолчанию
категории неупорядочены и равны установленным значениям, присутствующим в
множество. Другими словами, dtype='category' эквивалентно dtype=CategoricalDtype() .
Семантика равенства
Два экземпляра CategoricalDtype сравниваются равными
всякий раз, когда они имеют одинаковые категории и порядок. При сравнении двух
неупорядоченные категории, порядок категорий не учитывается.
В [49]: c1 = CategoricalDtype(["a", "b", "c"], order=False) # Равно, так как порядок не учитывается, если order=False В [50]: c1 == CategoricalDtype(["b", "c", "a"], order=False) Выход[50]: Верно # Неравно, так как второй CategoricalDtype упорядочен В [51]: c1 == CategoricalDtype(["a", "b", "c"], order=True) Исход[51]: Ложь
Все экземпляры CategoricalDtype сравниваются со строкой 'category' .
В [52]: c1 == "категория" Исход[52]: Верно
Предупреждение
Поскольку dtype='category' по сути является CategoricalDtype(None, False) ,
и поскольку все экземпляры CategoricalDtype сравниваются с 'category' ,
все экземпляры CategoricalDtype сравниваются равными КатегориальныйDтип(Нет, Ложь) , независимо от категории или заказал .
Описание
Использование description() для категориальных данных даст аналогичный результат.
вывод в Series или DataFrame типа string .
В [53]: cat = pd.Categorical(["a", "c", "c", np.nan], Categories=["b", "a", "c"])
В [54]: df = pd.DataFrame({"cat": cat, "s": ["a", "c", "c", np.nan]})
В [55]: df.describe()
Вышел[55]:
кот с
считать 3 3
уникальный 2 2
топ с с
частота 2 2
В [56]: df["cat"].describe()
Вышел[56]:
считать 3
уникальный 2
топ с
частота 2
Имя: кошка, dtype: объект
Работа с категориями
Категориальные данные имеют категорий и упорядоченных свойства, которые перечисляют их
возможных значений и имеет ли значение порядок или нет. Эти свойства
выставлен как s.cat.categories и s.cat.ordered . Если вы не вручную
укажите категории и порядок, они выводятся из переданных аргументов.
В [57]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [58]: s.cat.categories Out[58]: Index(['a', 'b', 'c'], dtype='object') В [59]: s.cat.ordered Исход[59]: Ложь
Также возможно проходить категории в определенном порядке:
В [60]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], Categories=["c", "b", "a"]) ) В [61]: s.cat.categories Out[61]: Index(['c', 'b', 'a'], dtype='object') В [62]: s.cat.ordered Исход[62]: Ложь
Примечание
Новые категориальные данные не упорядочиваются автоматически. Вы должны явно
pass ordered=True для обозначения заказанного Категориальный .
Примечание
Результат unique() не всегда совпадает с Series.cat.categories ,
потому что Series. имеет пару гарантий, а именно то, что он возвращает категории
в порядке появления и включает только те значения, которые действительно присутствуют. unique()
В [63]: s = pd.Series(list("babc")).astype(CategoricalDtype(list("abcd")))
В [64]: с
Вышел[64]:
0 б
1 год
2 б
3 с
тип: категория
Категории (4, объект): ['a', 'b', 'c', 'd']
# категории
В [65]: s.cat.categories
Out[65]: Index(['a', 'b', 'c', 'd'], dtype='object')
# уникальные
В [66]: s.unique()
Вышел[66]:
['б', 'а', 'в']
Категории (4, объект): ['a', 'b', 'c', 'd']
Переименование категорий
Переименование категорий осуществляется с помощью rename_categories() метод:
В [67]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [68]: с Вышел[68]: 0 а 1 б 2 с 3 часа тип: категория Категории (3, объект): ['a', 'b', 'c'] В [69]: new_categories = ["Группа %s" % g для g в s.cat.categories] В [70]: s = s.cat.rename_categories(new_categories) В [71]: с Вышел[71]: 0 Группа А 1 группа б 2 Группа с 3 Группа А тип: категория Категории (3, объект): ['Группа a', 'Группа b', 'Группа c'] # Вы также можете передать объект, похожий на словарь, чтобы сопоставить переименование В [72]: s = s.
Note
В отличие от R factor , категориальные данные могут иметь категории других типов, кроме строк.
Примечание
Имейте в виду, что назначение новых категорий является операцией на месте, в то время как большинство других операций
под Series.cat по умолчанию возвращает новый Series dtype категории .
Категории должны быть уникальными, иначе возникает ошибка ValueError :
В [74]: попробуйте:
....: s = s.cat.rename_categories([1, 1, 1])
....: кроме ValueError как e:
....: print("ValueError:", str(e))
....:
ValueError: Категориальные категории должны быть уникальными
Категории также не должны быть NaN или ValueError :
В [75]: попробуйте: .
Добавление новых категорий
Добавление категорий может быть выполнено с помощью метод add_categories() :
В [76]: s = s.cat.add_categories([4]) В [77]: s.cat.categories Out[77]: Index(['Группа a', 'Группа b', 'Группа c', 4], dtype='object') В [78]: с Вышел[78]: 0 Группа А 1 группа б 2 Группа с 3 Группа А тип: категория Категории (4, объект): ['Группа а', 'Группа б', 'Группа с', 4]
Удаление категорий
Удаление категорий можно выполнить с помощью метод remove_categories() . Ценности, которые удаляются
заменяются на np.nan .:
В [79]: s = s.cat.remove_categories([4]) В [80]: с Исход[80]: 0 Группа А 1 группа б 2 Группа с 3 Группа А тип: категория Категории (3, объект): ['Группа a', 'Группа b', 'Группа c']
Удаление неиспользуемых категорий
Также можно удалить неиспользуемые категории:
В [81]: s = pd.
Категории настроек
Если вы хотите удалить и добавить новые категории за один шаг (который имеет некоторые
преимущество в скорости) или просто установите категории в предопределенный масштаб,
использовать set_categories() .
В [84]: s = pd.Series(["один", "два", "четыре", "-"], dtype="category") В [85]: с Вышел[85]: 0 один 1 два 2 четыре 3 - тип: категория Категории (4, объект): ['-', 'четыре', 'один', 'два'] В [86]: s = s.cat.set_categories(["один", "два", "три", "четыре"]) В [87]: с Вышел[87]: 0 один 1 два 2 четыре 3 NaN тип: категория Категории (4, объект): ['один', 'два', 'три', 'четыре']
Примечание
Имейте в виду, что Categorical. не может знать, пропущена ли какая-либо категория
преднамеренно или потому, что в нем написана ошибка, или (в Python3) из-за различия типов (например,
NumPy S1 dtype и строки Python). Это может привести к неожиданному поведению! set_categories()
Сортировка и заказ
Если категориальные данные упорядочены ( s.cat.ordered == True ), то порядок категорий имеет
значение и определенные операции возможны. Если категориальное неупорядочено, .min()/.max() вызовет TypeError .
В [88]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], order=False))
В [89]: s.sort_values(inplace=True)
В [90]: s = pd.Series(["a", "b", "c", "a"]).astype(CategoricalDtype(ordered=True))
В [91]: s.sort_values(inplace=True)
В [92]: с
Вышел[92]:
0 а
3 часа
1 б
2 с
тип: категория
Категории (3, объект): ['a' < 'b' < 'c']
В [93]: s.min(), s.max()
Исход[93]: ('а', 'с')
Вы можете установить упорядочение категорийных данных с помощью as_ordered() или неупорядоченный с помощью as_unordered() . Это будет
по умолчанию возвращает новый объект .
В [94]: s.cat.as_ordered() Вышел[94]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a' < 'b' < 'c'] В [95]: s.cat.as_unordered() Вышел[95]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a', 'b', 'c']
Сортировка будет использовать порядок, определенный категориями, а не любой лексический порядок, присутствующий в типе данных. Это верно даже для строк и числовых данных:
В [96]: s = pd.Series([1, 2, 3, 1], dtype="category") В [97]: s = s.cat.set_categories([2, 3, 1], order=True) В [98]: с Вышел[98]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [99]: s.sort_values(inplace=True) В [100]: с Выход[100]: 1 2 2 3 0 1 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [101]: s.min(), s.max() Исход[101]: (2, 1)
Повторный заказ
Изменение порядка категорий возможно через Категориальная.reorder_categories() и метода Categorical.. Для set_categories() Categorical.reorder_categories() все
старые категории должны быть включены в новые категории, и никакие новые категории не допускаются. Это будет
обязательно сделайте порядок сортировки таким же, как порядок категорий.
В [102]: s = pd.Series([1, 2, 3, 1], dtype="category") В [103]: s = s.cat.reorder_categories([2, 3, 1], order=True) В [104]: с Выход[104]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [105]: s.sort_values(inplace=True) В [106]: с Выход[106]: 1 2 2 3 0 1 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [107]: s.min(), s.max() Исход[107]: (2, 1)
Примечание
Обратите внимание на разницу между назначением новых категорий и изменением порядка категорий: первая
переименовывает категории и, следовательно, отдельные значения в серии , но если первый
позиция была отсортирована последней, переименованное значение все равно будет отсортировано последним. Переупорядочивание означает, что
способ сортировки значений впоследствии отличается, но не отдельные значения в Серия изменена.
Примечание
Если Категория не заказан, Series.min() и Series.max() поднимет Типовая ошибка . Числовые операции типа +, -, *, / и операции на их основе
(например, Series.median() , который должен был бы вычислить среднее между двумя значениями, если длина
массива четные) не работают и поднимают TypeError .
Сортировка по нескольким столбцам
Категориальный столбец dtyped будет участвовать в многостолбцовой сортировке аналогично другим столбцам.
Порядок категориального определяется категории этого столбца.
В [108]: dfs = pd.DataFrame(
.....: {
.....: "A": pd.Категорический(
.....: список("ббиббаа"),
.....: категории=["е", "а", "б"],
.....: заказано=Истина,
.....: ),
.....: "В": [1, 2, 1, 2, 2, 1, 2, 1],
.....: }
.....: )
.....:
В [109]: dfs.sort_values(by=["A", "B"])
Выход[109]:
А Б
2 е 1
3 е 2
7 в 1
6 в 2
0 б 1
5 б 1
1 б 2
4 б 2
Изменение порядка категорий изменяет будущую сортировку.
В [110]: dfs["A"] = dfs["A"].cat.reorder_categories(["a", "b", "e"]) В [111]: dfs.sort_values(by=["A", "B"]) Выход[111]: А Б 7 в 1 6 в 2 0 б 1 5 б 1 1 б 2 4 б 2 2 е 1 3 е 2
Сравнения
Сравнение категорийных данных с другими объектами возможно в трех случаях:
Сравнение равенства (
==и!=) с объектом, подобным списку (список, серия, массив, …) той же длины, что и категориальные данные.Все сравнения (
==,!=,>,>=,<и<=) категориальных данных с другой категориальный ряд, когдазаказал == Правдаикатегорииодинаковы.Все сравнения категориальных данных со скаляром.
Все другие сравнения, особенно сравнения «не на равенство» двух категорий с разными
категории или категориальный с любым объектом, подобным списку, поднимет Ошибка типа .
Примечание
Любые «неравенские» сравнения категорийных данных с Series , np.array , list или
категориальные данные с разными категориями или порядком вызовут TypeError , потому что пользовательские
порядок категорий можно интерпретировать двояко: один с учетом
заказ и один без.
В [112]: cat = pd.Series([1, 2, 3]).astype(CategoricalDtype([3, 2, 1], order=True)) В [113]: cat_base = pd.Series([2, 2, 2]).astype(CategoricalDtype([3, 2, 1], order=True)) В [114]: cat_base2 = pd.Series([2, 2, 2]).astype(CategoricalDtype(ordered=True)) В [115]: кошка Выход[115]: 0 1 1 2 2 3 тип: категория Категории (3, int64): [3 < 2 < 1] В [116]: cat_base Выход[116]: 0 2 1 2 2 2 тип: категория Категории (3, int64): [3 < 2 < 1] В [117]: cat_base2 Выход[117]: 0 2 1 2 2 2 тип: категория Категории (1, int64): [2]
Сравнение с категориальным с теми же категориями и порядком или со скалярным работает:
В [118]: cat > cat_base Выход[118]: 0 Верно 1 Ложь 2 Ложь тип: логический В [119]: кошка > 2 Выход[119]: 0 Верно 1 Ложь 2 Ложь тип: логический
Сравнение на равенство работает с любым спискообразным объектом одинаковой длины и скаляров:
В [120]: cat == cat_base Выход[120]: 0 Ложь 1 правда 2 Ложь тип: логический В [121]: cat == np.
Это не работает, потому что категории не совпадают:
В [123]: попробуйте:
.....: кошка > cat_base2
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: Категориалы можно сравнивать только в том случае, если «категории» одинаковы.
Если вы хотите выполнить сравнение «неравенства» категориального ряда со спископодобным объектом которые не являются категориальными данными, вам нужно быть явным и преобразовать категориальные данные обратно в исходные значения:
В [124]: база = np.array([1, 2, 3])
В [125]: попробуйте:
.....: кошка > база
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно сравнить категориальное для op __gt__ с типом .
Если вы хотите сравнить значения, используйте «np.asarray(cat) other».
В [126]: np.asarray(cat) > base
Выход[126]: массив([Ложь, Ложь, Ложь])
При сравнении двух неупорядоченных категорий с одинаковыми категориями порядок не учитывается:
В [127]: c1 = pd.Categorical(["a", "b"], Categories=["a", "b"], order=False) В [128]: c2 = pd.Categorical(["a", "b"], Categories=["b", "a"], order=False) В [129]: c1 == c2 Выход[129]: массив([Истина, Истина])
Операции
Помимо Series.min() , Series.max() и Series.mode() ,
следующие операции возможны с категориальными данными:
Методы Series , такие как Series.value_counts() будет использовать все категории,
даже если некоторые категории отсутствуют в данных:
В [130]: s = pd.Series(pd.Categorical(["a", "b", "c", "c"], Categories=["c", "a", "b", " д"])) В [131]: s.value_counts() Выход[131]: с 2 1 б 1 д 0 тип: int64
Методы DataFrame , такие как DataFrame., также показывают «неиспользуемые» категории. sum()
В [132]: columns = pd.Categorical( .....: ["Один", "Один", "Два"], category=["Один", "Два", "Три"], order=True .....: ) .....: В [133]: df = pd.DataFrame( .....: данные=[[1, 2, 3], [4, 5, 6]], .....: столбцы = pd.MultiIndex.from_arrays ([["A", "B", "B"], столбцы]), .....: ) .....: В [134]: df.groupby(axis=1, level=1).sum() Исход[134]: Раз два три 0 3 3 0 1 96 0
Groupby также покажет «неиспользуемые» категории:
В [135]: кошки = pd.Categorical(
.....: ["a", "b", "b", "b", "c", "c", "c"], category=["a", "b", "c" , "д"]
.....: )
.....:
В [136]: df = pd.DataFrame({"кошки": кошки, "значения": [1, 2, 2, 2, 3, 4, 5]})
В [137]: df.groupby("кошки").mean()
Исход[137]:
ценности
кошки
1,0
б 2.0
с 4.0
г NaN
В [138]:cats2 = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c"])
В [139]: df2 = pd.DataFrame(
.....: {
.....: "коты": коты2,
.....: "В": ["в", "д", "в", "д"],
. ....: "значения": [1, 2, 3, 4],
.....: }
.....: )
.....:
В [140]: df2.groupby(["кошки", "B"]).mean()
Выход[140]:
ценности
кошки Б
а в 1,0
д 2.0
б в 3,0
д 4,0
в в NaN
г NaN
Сводные таблицы:
В [141]: raw_cat = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c"])
В [142]: df = pd.DataFrame({"A": raw_cat, "B": ["c", "d", "c", "d"], "values": [1, 2, 3 , 4]})
В [143]: pd.pivot_table(df, values="values", index=["A", "B"])
Исход[143]:
ценности
А Б
а с 1
д 2
б в 3
д 4
Фальсификация данных
Оптимизированные методы доступа к данным pandas .loc , .iloc , .at и .iat ,
работать как обычно. Единственная разница заключается в типе возврата (для получения) и
что только значения уже в категориях могут быть назначены.
Получение
Если операция среза возвращает либо DataFrame , либо столбец типа Series , сохраняется категория dtype.
В [144]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n"])
В [145]: кошки = pd.Series(["a", "b", "b", "b", "c", "c", "c"], dtype="category", index=idx )
В [146]: значения = [1, 2, 2, 2, 3, 4, 5]
В [147]: df = pd.DataFrame({"кошки": кошки, "значения": значения}, index=idx)
В [148]: df.iloc[2:4, :]
Исход[148]:
кошачьи ценности
дж б 2
к б 2
В [149]: df.iloc[2:4, :].dtypes
Исход[149]:
категория кошек
значения int64
тип: объект
В [150]: df.loc["h":"j", "кошки"]
Выход[150]:
ч а
я б
дж б
Имя: кошки, dtype: категория
Категории (3, объект): ['a', 'b', 'c']
В [151]: df[df["кошки"] == "b"]
Выход[151]:
кошачьи ценности
я б 2
дж б 2
к б 2
Пример, когда тип категории не сохраняется, если взять один единственный
строка: результирующий Series имеет объект dtype :
# получить полную строку "h" в виде серии В [152]: df.loc["h", :] Выход[152]: кошки а значения 1 Имя: h, dtype: объект
При возврате одного элемента из категориальных данных также будет возвращено значение, а не категориальный
длины «1».
В [153]: df.iat[0, 0] Вышел[153]: 'а' В [154]: df["кошки"] = df["кошки"].cat.rename_categories(["x", "y", "z"]) В [155]: df.at["h", "cats"] # возвращает строку Выход[155]: 'x'
Примечание
В отличие от функции R factor , где factor(c(1,2,3))[1] возвращает одно значение фактор .
Чтобы получить одно значение Series типа категории , вы передаете список с
одно значение:
В [156]: df.loc[["h"], "кошки"] Исход[156]: ч х Имя: кошки, dtype: категория Категории (3, объект): ['x', 'y', 'z']
Средства доступа к строке и дате/времени
Аксессуары .dt и .str будут работать, если s.cat.categories имеют
соответствующий тип:
В [157]: str_s = pd.Series(list("aabb"))
В [158]: str_cat = str_s.astype("категория")
В [159]: str_cat
Вышли[159]:
0 а
1 год
2 б
3 б
тип: категория
Категории (2, объект): ['a', 'b']
В [160]: str_cat. str.contains("a")
Выход[160]:
0 Верно
1 правда
2 Ложь
3 Ложь
тип: логический
В [161]: date_s = pd.Series(pd.date_range("1/1/2015", периоды=5))
В [162]: date_cat = date_s.astype("категория")
В [163]: date_cat
Исход[163]:
0 01.01.2015
1 2015-01-02
2 2015-01-03
3 2015-01-04
4 2015-01-05
тип: категория
Категории (5, datetime64[ns]): [2015-01-01, 2015-01-02, 2015-01-03, 2015-01-04, 2015-01-05]
В [164]: date_cat.dt.day
Исход[164]:
0 1
1 2
2 3
3 4
4 5
тип: int64
Примечание
Возвращенный Series (или DataFrame ) имеет тот же тип, что и при использовании .str.<метод> / .dt.<метод> на серии этого типа (и не
тип категория !).
Это означает, что возвращаемые значения из методов и свойств методов доступа Серия и возвращаемые значения из методов и свойств средств доступа этого Серия преобразована в тип категория будет равна:
В [165]: ret_s = str_s.
Примечание
Работа выполняется на категории , а затем создается новая серия . Это имеет
некоторое влияние на производительность, если у вас есть Series типа string, где много элементов
повторяются (т.е. количество уникальных элементов в Серия намного меньше, чем
длина серии ). В этом случае может быть быстрее преобразовать исходный серии к одному из типов категории и используйте для этого .str.<метод> или .dt.<свойство> .
Настройка
Установка значений в категориальном столбце (или Серия ) работает до тех пор, пока
значение включено в категории :
В [169]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n"]) В [170]: кошки = pd.
Установка значений путем присвоения категориальных данных также проверяет соответствие категорий :
В [176]: df.loc["j":"k", "cats"] = pd.Categorical(["a", "a"], Categories=["a", "b"]) В [177]: дф Вышли[177]: кошачьи ценности ч а 1 я 1 Дж а 2 к а 2 л а 1 м а 1 п а 1 В [178]: попробуйте: .....: df.loc["j":"k", "кошки"] = pd.Categorical(["b", "b"], Categories=["a", "b", "c "]) .
При присвоении Категориального частям столбца других типов будут использоваться значения:
В [179]: df = pd.DataFrame({"a": [1, 1, 1, 1, 1], "b": ["a", "a", "a", "a", "а"]})
В [180]: df.loc[1:2, "a"] = pd.Categorical(["b", "b"], Categories=["a", "b"])
В [181]: df.loc[2:3, "b"] = pd.Categorical(["b", "b"], Categories=["a", "b"])
В [182]: дф
Исход[182]:
а б
0 1 а
1 б а
2 б б
3 1 б
4 1 а
В [183]: df.dtypes
Исход[183]:
объект
б объект
тип: объект
Слияние/объединение
По умолчанию объединение Series или DataFrames , которые содержат одинаковые
категории приводит к категории dtype, в противном случае результаты будут зависеть от
dtype базовых категорий. Слияния, которые приводят к некатегоричности
dtypes, вероятно, будут использовать больше памяти. Используйте .astype или union_categoricals для обеспечения результатов категории .
В [184]: из pandas.api.types import union_categoricals
# те же категории
В [185]: s1 = pd.Series(["a", "b"], dtype="category")
В [186]: s2 = pd.Series(["a", "b", "a"], dtype="category")
В [187]: pd.concat([s1, s2])
Вышли[187]:
0 а
1 б
0 а
1 б
2 часа
тип: категория
Категории (2, объект): ['a', 'b']
# разные категории
В [188]: s3 = pd.Series(["b", "c"], dtype="category")
В [189]: pd.concat([s1, s3])
Вышли[189]:
0 а
1 б
0 б
1 с
тип: объект
# Выходной dtype выводится на основе значений категорий
В [190]: int_cats = pd.Series([1, 2], dtype="category")
В [191]: float_cats = pd.Series([3.0, 4.0], dtype="category")
В [192]: pd.concat([int_cats, float_cats])
Исход[192]:
0 1,0
1 2,0
0 3,0
1 4,0
тип: float64
В [193]: pd.concat([s1, s3]).astype("категория")
Исход[193]:
0 а
1 б
0 б
1 с
тип: категория
Категории (3, объект): ['a', 'b', 'c']
В [194]: union_categoricals([s1. array, s3.array])
Исход[194]:
['а', 'б', 'б', 'в']
Категории (3, объект): ['a', 'b', 'c']
В следующей таблице приведены результаты объединения категорий :
арг1 | аргумент2 | идентичный | результат |
|---|---|---|---|
категория | категория | Правда | категория |
категория (объект) | категория (объект) | Ложь | объект (выводится dtype) |
категория (внутренняя) | категория (плавающая) | Ложь | с плавающей запятой (предполагается dtype) |
См. также раздел о типах слияния для заметок о
сохранение типов слияния и производительности.
Объединение
Если вы хотите объединить категории, которые не обязательно имеют одинаковые
категории, функция union_categoricals() будет
объединить список подобных категорий. Новые категории будут представлять собой объединение
категории объединяются.
В [195]: из pandas.api.types import union_categoricals В [196]: a = pd.Categorical(["b", "c"]) В [197]: b = pd.Categorical(["a", "b"]) В [198]: union_categoricals([a, b]) Вышли[198]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a']
По умолчанию результирующие категории будут упорядочены как
они появляются в данных. Если вы хотите, чтобы категории
для лексической сортировки используйте аргумент sort_categories=True .
В [199]: union_categoricals([a, b], sort_categories=True) Вышли[199]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals также работает с «простым» случаем объединения двух
категории тех же категорий и информация о заказе
(например, что вы могли бы также добавить для).
В [200]: a = pd.Categorical(["a", "b"], order=True) В [201]: b = pd.Categorical(["a", "b", "a"], order=True) В [202]: union_categoricals([a, b]) Выход[202]: ['а', 'б', 'а', 'б', 'а'] Категории (2, объект): ['a' < 'b']
Приведенное ниже вызывает TypeError , поскольку категории упорядочены и не идентичны.
В [1]: a = pd.Categorical(["a", "b"], order=True) В [2]: b = pd.Categorical(["a", "b", "c"], order=True) В [3]: union_categoricals([a, b]) Выход[3]: TypeError: для объединения упорядоченных категорий все категории должны быть одинаковыми
Упорядоченные категориальные элементы с разными категориями или порядками можно комбинировать с помощью
используя аргумент ignore_ordered=True .
В [203]: a = pd.Categorical(["a", "b", "c"], order=True) В [204]: b = pd.Categorical(["c", "b", "a"], order=True) В [205]: union_categoricals([a, b], ignore_order=True) Выход[205]: ['а', 'б', 'в', 'в', 'б', 'а'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals() также работает с Категориальный индекс или Серия , содержащая категориальные данные, но обратите внимание, что
результирующий массив всегда будет простым Категориальный :
В [206]: a = pd.
Примечание
union_categoricals может перекодировать целые коды для категорий
при объединении категорий. Это, вероятно, то, что вы хотите,
но если вы полагаетесь на точную нумерацию категорий, будьте
осведомленный.
В [209]: c1 = pd.Categorical(["b", "c"]) В [210]: c2 = pd.Categorical(["a", "b"]) В [211]: с1 Выход[211]: ['до н.э'] Категории (2, объект): ['b', 'c'] # "b" кодируется как 0 В [212]: c1.codes Выход[212]: массив([0, 1], dtype=int8) В [213]: с2 Выход[213]: ['а', 'б'] Категории (2, объект): ['a', 'b'] # "b" кодируется как 1 В [214]: c2.codes Выход[214]: массив([0, 1], dtype=int8) В [215]: c = union_categoricals([c1, c2]) В [216]: в Выход[216]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a'] # "b" везде кодируется как 0, так же, как c1, но отличается от c2 В [217]: c.
Получение/вывод данных
Вы можете записать данные, содержащие категории dtypes, в хранилище HDFStore .
См. здесь пример и предостережения.
Также можно записывать данные и считывать данные из файлов формата Stata . См. здесь пример и предостережения.
Запись в CSV-файл преобразует данные, эффективно удаляя любую информацию о
категориальные (категории и порядок). Поэтому, если вы читаете файл CSV, вам нужно преобразовать
соответствующие столбцы назад к категория и назначьте правильные категории и порядок категорий.
В [218]: импорт io В [219]: s = pd.Series(pd.Categorical(["a", "b", "b", "a", "a", "d"])) # переименовать категории В [220]: s = s.cat.rename_categories(["очень хорошо", "хорошо", "плохо"]) # изменить порядок категорий и добавить недостающие категории В [221]: s = s.cat.set_categories(["очень плохо", "плохо", "средне", "хорошо", "очень хорошо"]) В [222]: df = pd.
То же самое верно для записи в базу данных SQL с to_sql .
Отсутствуют данные
pandas в основном использует значение np.nan для представления отсутствующих данных. Это по
по умолчанию не включены в расчеты. См. раздел «Отсутствующие данные».
Отсутствующие значения должны быть включены , а не в категории категории ,
только в значения .
Вместо этого понятно, что NaN отличается и всегда возможен.
При работе с категориальными кодами пропущенные значения всегда будут иметь
код -1 .
В [232]: s = pd.Series(["a", "b", np.nan, "a"], dtype="category") # только две категории В [233]: с Выход[233]: 0 а 1 б 2 NaN 3 часа тип: категория Категории (2, объект): ['a', 'b'] В [234]: s.cat.codes Выход[234]: 0 0 1 1 2 -1 3 0 тип: int8
Методы работы с отсутствующими данными, т.е. исна () , заполнение () , dropna() , все работает нормально:
В [235]: s = pd.Series(["a", "b", np.
Отличия от фактора R
Можно наблюдать следующие отличия функций фактора R:
уровней Rназваныкатегориями.Уровни
Rвсегда имеют строковый тип, а категорииНевозможно указать метки во время создания. Используйте
s.cat.rename_categories(new_labels)после.В отличие от функции R
factor, использование категориальных данных в качестве единственного входа для создания новый категориальный ряд , а не удалит неиспользуемые категории, но создаст новый категориальный ряд что равно переданному за единицу!R позволяет включать отсутствующие значения в свои
уровней(категории pandas). панды
не допускает категорий NaN, но отсутствующие значения все еще могут быть взначения.
Гочки
Использование памяти
Использование памяти Категорий пропорционально количеству категорий плюс длина данных. Наоборот,
объект dtype — это константа, умноженная на длину данных.
В [239]: s = pd.Series(["foo", "bar"] * 1000)
# тип объекта
В [240]: s.nbytes
Выход[240]: 16000
# категория dtype
В [241]: s.astype("category").nbytes
Вышло[241]: 2016 г.
Примечание
Если количество категорий приближается к длине данных, Категориальный будет использовать почти то же самое или
больше памяти, чем эквивалентное представление объекта dtype.
В [242]: s = pd.Series(["foo%04d" % i для i в диапазоне (2000)])
# тип объекта
В [243]: s.nbytes
Выход[243]: 16000
# категория dtype
В [244]: s.astype("category").nbytes
Выход[244]: 20000
Категориальный не является массивом numpy В настоящее время категориальные данные и базовые Категориальный реализован как Python
объект, а не как низкоуровневый массив NumPy dtype. Это приводит к некоторым проблемам.
Сам NumPy не знает о новом dtype :
В [245]: попробуйте:
.....: np.dtype ("категория")
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: тип данных «категория» не понят
В [246]: dtype = pd.Categorical(["a"]).dtype
В [247]: попробуйте:
.....: np.dtype(dtype)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно интерпретировать «CategoricalDtype (categories = ['a'], Ordered = False)» как тип данных
Сравнения Dtype работают:
В [248]: dtype == np.str_ Выход[248]: Ложь В [249]: np.str_ == dtype Выход[249]: Ложь
Чтобы проверить, содержит ли серия категориальные данные, используйте hasattr(s, 'cat') :
В [250]: hasattr(pd.Series(["a"], dtype="category"), "cat") Выход[250]: Истина В [251]: hasattr(pd.Series(["a"]), "cat") Выход[251]: Ложь
Использование функций NumPy на серии типа категории не должно работать как Категории не являются числовыми данными (даже в том случае, если . является числовым). categories
В [252]: s = pd.Series(pd.Categorical([1, 2, 3, 4]))
В [253]: попробуйте:
.....: np.sum(s)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: «Категория» с категорией dtype не поддерживает сокращение «сумма»
Примечание
Если такая функция работает, сообщите об ошибке на https://github.com/pandas-dev/pandas!
dtype в приложении
pandas в настоящее время не сохраняет dtype в функциях применения: если вы применяете вдоль строк, вы получаете
a Series of object dtype (так же, как получение строки -> получение одного элемента вернет
базовый тип) и применение вдоль столбцов также преобразуется в объект. NaN Значения не изменяются.
Вы можете использовать fillna для обработки пропущенных значений перед применением функции.
В [254]: df = pd.DataFrame(
.....: {
.....: "а": [1, 2, 3, 4],
. ....: "б": ["а", "б", "в", "д"],
.....: "кошки": pd.Categorical([1, 2, 3, 2]),
.....: }
.....: )
.....:
В [255]: df.apply(лямбда-строка: тип(строка["кошки"]), ось=1)
Выход[255]:
0 <класс 'целое число'>
1 <класс 'целое число'>
2 <класс 'целое число'>
3 <класс 'целое число'>
тип: объект
В [256]: df.apply(лямбда-столбец: col.dtype, ось=0)
Исход[256]:
int64
б объект
категория кошек
тип: объект
Категориальный индекс
CategoricalIndex — тип индекса, полезный для поддержки
индексация с дубликатами. Это контейнер вокруг категории и позволяет эффективно индексировать и хранить индекс с большим количеством повторяющихся элементов.
Более подробные сведения см. в документации по расширенному индексированию.
объяснение.
Установка индекса создаст CategoricalIndex :
В [257]: кошки = pd.Categorical([1, 2, 3, 4], Categories=[4, 2, 3, 1]) В [258]: strings = ["a", "b", "c", "d"] В [259]: значения = [4, 2, 3, 1] В [260]: df = pd.
Побочные эффекты
Построение серии из категориального не будет копировать ввод Категориальный . Это означает, что изменения в серии в большинстве случаев
изменить исходный Категориальный :
В [263]: cat = pd.Categorical([1, 2, 3, 10], Categories=[1, 2, 3, 4, 10]) В [264]: s = pd.Series(cat, name="cat") В [265]: кошка Выход[265]: [1, 2, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [266]: s.iloc[0:2] = 10 В [267]: кошка Исход[267]: [10, 10, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [268]: df = pd.DataFrame(s) В [269]: df["cat"].cat.categories = [1, 2, 3, 4, 5] В [270]: кошка Выход[270]: [5, 5, 3, 5] Категории (5, int64): [1, 2, 3, 4, 5]
Используйте copy=True , чтобы предотвратить такое поведение или просто не используйте повторно Категориалы :
В [271]: cat = pd.
Примечание
Это также происходит в некоторых случаях, когда вы предоставляете массив NumPy вместо Категориальный :
использование массива int (например, np.array([1,2,3,4]) ) будет демонстрировать такое же поведение, при использовании
массив строк (например, np.array(["a","b","c","a"]) ) не будет.
Категориальные данные — документация pandas 1.2.5
Это введение в тип категориальных данных pandas, включая краткое сравнение
с коэффициентом R .
Категориалы — это тип данных pandas, соответствующий категориальным переменным в
статистика. Категориальная переменная принимает ограниченное и обычно фиксированное значение. количество возможных значений ( категории ; уровня в R). Примеры: пол,
социальный класс, группа крови, принадлежность к стране, время наблюдения или рейтинг через
шкалы Лайкерта.
В отличие от статистических категориальных переменных, категориальные данные могут иметь порядок (например, «полностью согласен» против «согласен» или «первое наблюдение» против «второго наблюдения»), но числовые операции (сложения, деления и т. д.) невозможны.
Все значения категорийных данных находятся либо в категориях , либо в нп.нан . Порядок определяется
порядок категории , не лексический порядок значений. Внутренняя структура данных
состоит из массива категорий и целочисленного массива кодов , которые указывают на реальное значение в
массив категорий .
Категориальный тип данных полезен в следующих случаях:
Строковая переменная, состоящая всего из нескольких различных значений.
Преобразование такой строки
переменная в категориальную переменную сэкономит немного памяти, см. здесь.Лексический порядок переменной не совпадает с логическим («один», «два», «три»). Путем преобразования в категориальный и указания порядка категорий, сортировки и min/max будет использовать логический порядок вместо лексического, см. здесь.
Как сигнал другим библиотекам Python, что этот столбец следует рассматривать как категориальный переменной (например, для использования подходящих статистических методов или типов графиков).
См. также документацию API по категориям.
Создание объекта
Создание серии
Категориальная серия или столбцы в DataFrame можно создать несколькими способами:
, указав Dtype = "Категория" . 1]: s = pd.Series(["a", "b", "c", "a"], dtype="category")
В [2]: с
Выход[2]:
0 а
1 б
2 с
3 часа
тип: категория
Категории (3, объект): ['a', 'b', 'c']
Путем преобразования существующей серии или столбец в категорию dtype:
В [3]: df = pd.
С помощью специальных функций, таких как cut() , которые группируют данные в
дискретные бункеры. См. пример тайлинга в документации.
В [6]: df = pd.DataFrame({"value": np.random.randint(0, 100, 20)})
В [7]: labels = ["{0} - {1}".format(i, i + 9) для i в диапазоне (0, 100, 10)]
В [8]: df["group"] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels)
В [9]: df.head(10)
Выход[9]:
группа значений
0 65 60 - 69
1 49 40 - 49
2 56 50 - 59
3 43 40 - 49
4 43 40 - 49
5 91 90 - 99
6 32 30 - 39
7 87 80 - 89
8 36 30 - 39
9 8 0 - 9
Передав объект pandas.Categorical серии или назначив его DataFrame .
В [10]: raw_cat = pd.Categorical( ....: ["a", "b", "c", "a"], Categories=["b", "c", "d"], order=False .... :) ....: В [11]: s = pd.Series(raw_cat) В [12]: с Выход[12]: 0 NaN 1 б 2 с 3 NaN тип: категория Категории (3, объект): ['b', 'c', 'd'] В [13]: df = pd.
Категориальные данные имеют определенную категорию dtype:
В [16]: df.dtypes Вышли[16]: Объект категория Б тип: объект
Создание DataFrame
Как и в предыдущем разделе, где один столбец был преобразован в категориальный, все столбцы в DataFrame может быть пакетно преобразован в категориальный во время или после построения.
Это можно сделать во время строительства, указав dtype="category" в DataFrame конструктор:
В [17]: df = pd.DataFrame({"A": список("abca"), "B": список("bccd")}, dtype="category")
В [18]: df.dtypes
Вышли[18]:
Категория
категория Б
тип: объект
Обратите внимание, что категории в каждом столбце различаются; преобразование выполняется столбец за столбцом, поэтому только метки, присутствующие в данном столбце, являются категориями:
В [19]: df["A"] Вышли[19]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [20]: df["B"] Исход[20]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Аналогично, все столбцы в существующем DataFrame могут быть преобразованы в пакетном режиме с использованием DataFrame. : astype()
В [21]: df = pd.DataFrame({"A": list("abca"), "B": список("bccd")})
В [22]: df_cat = df.astype("категория")
В [23]: df_cat.dtypes
Вышли[23]:
Категория
категория Б
тип: объект
Это преобразование также выполняется столбец за столбцом:
В [24]: df_cat["A"] Вышли[24]: 0 а 1 б 2 с 3 часа Имя: A, dtype: категория Категории (3, объект): ['a', 'b', 'c'] В [25]: df_cat["B"] Вышли[25]: 0 б 1 с 2 с 3 д Имя: B, dtype: категория Категории (3, объект): ['b', 'c', 'd']
Управление поведением
В приведенных выше примерах, где мы передали dtype='category' , мы использовали значение по умолчанию
поведение:
Категории выводятся из данных.
Категории неупорядочены.
Чтобы управлять этим поведением, вместо передачи «категории» используйте экземпляр
из КатегориальныйDтип .
В [26]: из pandas.api.types import CategoricalDtype В [27]: s = pd.
Аналогично, CategoricalDtype можно использовать с DataFrame , чтобы гарантировать, что категории
согласованы между всеми столбцами.
В [31]: из pandas.api.types import CategoricalDtype
В [32]: df = pd.DataFrame({"A": list("abca"), "B": list("bccd")})
В [33]: cat_type = CategoricalDtype(categories=list("abcd"), order=True)
В [34]: df_cat = df.astype(cat_type)
В [35]: df_cat["A"]
Вышли[35]:
0 а
1 б
2 с
3 часа
Имя: A, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
В [36]: df_cat["B"]
Вышел[36]:
0 б
1 с
2 с
3 д
Имя: B, dtype: категория
Категории (4, объект): ['a' < 'b' < 'c' < 'd']
Примечание
Для выполнения табличного преобразования, когда все метки во всем DataFrame используются как
категорий для каждого столбца, параметр категорий может быть определен программно путем категории = pd. . unique(df.to_numpy().ravel())
Если у вас уже есть коды и категории , вы можете использовать from_codes() конструктор для сохранения шага факторизации
в обычном режиме конструктора:
В [37]: splitter = np.random.choice([0, 1], 5, p=[0,5, 0,5]) В [38]: s = pd.Series(pd.Categorical.from_codes(splitter, category=["train", "test"]))
Восстановление исходных данных
Чтобы вернуться к исходному массиву серии или NumPy, используйте Series.astype(original_dtype) или np.asarray(категориальный) :
В [39]: s = pd.Series(["a", "b", "c", "a"])
В [40]: с.
Вышли[40]:
0 а
1 б
2 с
3 часа
тип: объект
В [41]: s2 = s.astype("категория")
В [42]: s2
Вышел[42]:
0 а
1 б
2 с
3 часа
тип: категория
Категории (3, объект): ['a', 'b', 'c']
В [43]: s2.astype(str)
Вышел[43]:
0 а
1 б
2 с
3 часа
тип: объект
В [44]: np.asarray(s2)
Out[44]: массив(['a', 'b', 'c', 'a'], dtype=object)
Примечание
В отличие от функции R factor , категориальные данные не преобразуют входные значения в
струны; категории будут иметь тот же тип данных, что и исходные значения.
Примечание
В отличие от функции R factor , в настоящее время нет возможности назначать/изменять метки в
время создания. Используйте категории для изменения категорий после времени создания.
CategoricalDtype
Категориальный тип полностью описывается
категории: последовательность уникальных значений без пропущенных значенийзаказанный: логическое значение
Эта информация может храниться в CategoricalDtype .
Аргумент категорий является необязательным, что означает, что фактические категории
должны быть выведены из того, что присутствует в данных, когда pandas.Categorical создан. Предполагается, что категории неупорядочены.
по умолчанию.
В [45]: из pandas.api.types import CategoricalDtype В [46]: CategoricalDtype(["a", "b", "c"]) Out[46]: CategoricalDtype(categories=['a', 'b', 'c'], order=False) В [47]: CategoricalDtype(["a", "b", "c"], order=True) Out[47]: CategoricalDtype(categories=['a', 'b', 'c'], order=True) В [48]: КатегориальныйDtype() Out[48]: CategoricalDtype(categories=None, order=False)
A CategoricalDtype можно использовать в любом месте pandas
ожидает dtype . Например панды.read_csv() , pandas.DataFrame.astype() или в конструкторе серии .
Примечание
Для удобства можно использовать строку «категория» вместо CategoricalDtype , если вы хотите, чтобы поведение по умолчанию
категории неупорядочены и равны установленным значениям, присутствующим в
множество. Другими словами, dtype='category' эквивалентно dtype=CategoricalDtype() .
Семантика равенства
Два экземпляра CategoricalDtype сравниваются равными
всякий раз, когда они имеют одинаковые категории и порядок. При сравнении двух
неупорядоченные категории, порядок категорий не учитывается.
В [49]: c1 = CategoricalDtype(["a", "b", "c"], order=False) # Равно, так как порядок не учитывается, если order=False В [50]: c1 == CategoricalDtype(["b", "c", "a"], order=False) Выход[50]: Верно # Неравно, так как второй CategoricalDtype упорядочен В [51]: c1 == CategoricalDtype(["a", "b", "c"], order=True) Исход[51]: Ложь
Все экземпляры CategoricalDtype сравниваются со строкой 'category' .
В [52]: c1 == "категория" Исход[52]: Верно
Предупреждение
Поскольку dtype='category' по сути является CategoricalDtype(None, False) ,
и поскольку все экземпляры CategoricalDtype сравниваются с 'category' ,
все экземпляры CategoricalDtype сравниваются равными КатегориальныйDтип(Нет, Ложь) , независимо от категории или заказал .
Описание
Использование description() для категориальных данных даст аналогичный результат.
вывод в Series или DataFrame типа string .
В [53]: cat = pd.Categorical(["a", "c", "c", np.nan], Categories=["b", "a", "c"])
В [54]: df = pd.DataFrame({"cat": cat, "s": ["a", "c", "c", np.nan]})
В [55]: df.describe()
Вышел[55]:
кот с
считать 3 3
уникальный 2 2
топ с с
частота 2 2
В [56]: df["cat"].describe()
Вышел[56]:
считать 3
уникальный 2
топ с
частота 2
Имя: кошка, dtype: объект
Работа с категориями
Категориальные данные имеют категории и упорядоченное свойство , в которых перечислены их
возможных значений и имеет ли значение порядок или нет. Эти свойства
выставлен как s.cat.categories и s.cat.ordered . Если вы не вручную
укажите категории и порядок, они выводятся из переданных аргументов.
В [57]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [58]: s.cat.categories Out[58]: Index(['a', 'b', 'c'], dtype='object') В [59]: s.cat.ordered Исход[59]: Ложь
Также возможен переход по категориям в определенном порядке:
В [60]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], категории=["с", "б", "а"])) В [61]: s.cat.categories Out[61]: Index(['c', 'b', 'a'], dtype='object') В [62]: s.cat.ordered Исход[62]: Ложь
Примечание
Новые категориальные данные , а не упорядочиваются автоматически. Вы должны явно
pass ordered=True для обозначения заказанного Категориальный .
Примечание
Результат unique() не всегда совпадает с Series.cat.categories ,
потому что Series. имеет пару гарантий, а именно то, что он возвращает категории
в порядке появления и включает только те значения, которые действительно присутствуют. unique()
В [63]: s = pd.Series(list("babc")).astype(CategoricalDtype(list("abcd")))
В [64]: с
Вышел[64]:
0 б
1 год
2 б
3 с
тип: категория
Категории (4, объект): ['a', 'b', 'c', 'd']
# категории
В [65]: s.cat.categories
Out[65]: Index(['a', 'b', 'c', 'd'], dtype='object')
# уникальные
В [66]: s.unique()
Вышел[66]:
['б', 'а', 'в']
Категории (3, объект): ['b', 'a', 'c']
Переименование категорий
Переименование категорий выполняется путем присвоения новых значений Series.cat.categories или с помощью свойства rename_categories() метод:
В [67]: s = pd.Series(["a", "b", "c", "a"], dtype="category") В [68]: с Вышел[68]: 0 а 1 б 2 с 3 часа тип: категория Категории (3, объект): ['a', 'b', 'c'] В [69]: s.cat.categories = ["Группа %s" % g для g в s.cat.categories] В [70]: с.
Примечание
В отличие от R factor , категориальные данные могут иметь категории других типов, кроме строк.
Примечание
Имейте в виду, что назначение новых категорий является операцией на месте, в то время как большинство других операций
под Series.cat по умолчанию возвращает новый Series dtype категории .
Категории должны быть уникальными, иначе возникает ошибка ValueError :
В [75]: попробуйте: .
Категории также не должны быть NaN или ValueError :
В [76]: попробуйте:
....: s.cat.categories = [1, 2, np.nan]
....: кроме ValueError как e:
....: print("ValueError:", str(e))
....:
ValueError: категориальные категории не могут быть нулевыми
Добавление новых категорий
Добавление категорий можно выполнить с помощью add_categories() метод:
В [77]: s = s.cat.add_categories([4]) В [78]: s.cat.categories Out[78]: Index(['x', 'y', 'z', 4], dtype='object') В [79]: с Вышел[79]: 0 х 1 год 2 з 3 х тип: категория Категории (4, объект): ['x', 'y', 'z', 4]
Удаление категорий
Удаление категорий можно выполнить с помощью метод remove_categories() . Ценности, которые удаляются
заменяются на np. .: nan
В [80]: s = s.cat.remove_categories([4]) В [81]: с Вышел[81]: 0 х 1 год 2 з 3 х тип: категория Категории (3, объект): ['x', 'y', 'z']
Удаление неиспользуемых категорий
Также можно удалить неиспользуемые категории:
В [82]: s = pd.Series(pd.Categorical(["a", "b", "a"], Categories=["a", "b ", "CD"])) В [83]: с Вышел[83]: 0 а 1 б 2 часа тип: категория Категории (4, объект): ['a', 'b', 'c', 'd'] В [84]: s.cat.remove_unused_categories() Вышел[84]: 0 а 1 б 2 часа тип: категория Категории (2, объект): ['a', 'b']
Настройка категорий
Если вы хотите удалить и добавить новые категории за один шаг (который имеет некоторые
преимущество в скорости) или просто установите категории в предопределенный масштаб,
использовать set_categories() .
В [85]: s = pd.Series(["один", "два", "четыре", "-"], dtype="category") В [86]: с Вышел[86]: 0 один 1 два 2 четыре 3 - тип: категория Категории (4, объект): ['-', 'четыре', 'один', 'два'] В [87]: s = s.
Примечание
Имейте в виду, что Categorical.set_categories() не может знать, пропущена ли какая-либо категория
преднамеренно или потому, что в нем написана ошибка, или (в Python3) из-за различия типов (например,
NumPy S1 dtype и строки Python). Это может привести к неожиданному поведению!
Сортировка и порядок
Если категориальные данные упорядочены ( s.cat.ordered == True ), то порядок категорий имеет
значение и определенные операции возможны. Если категориальное неупорядочено, .min()/.max() вызовет TypeError .
В [89]: s = pd.Series(pd.Categorical(["a", "b", "c", "a"], order=False)) В [90]: s.sort_values(inplace=True) В [91]: s = pd.Series(["a", "b", "c", "a"]).astype(CategoricalDtype(ordered=True)) В [92]: s.
Вы можете установить упорядоченные данные категорий с помощью as_ordered() или неупорядоченные с помощью as_unordered() . Это будет
по умолчанию возвращает новый объект .
В [95]: s.cat.as_ordered() Вышел[95]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a' < 'b' < 'c'] В [96]: s.cat.as_unordered() Вышел[96]: 0 а 3 часа 1 б 2 с тип: категория Категории (3, объект): ['a', 'b', 'c']
При сортировке будет использоваться порядок, определенный категориями, а не любой лексический порядок, присутствующий в типе данных. Это верно даже для строк и числовых данных:
В [97]: s = pd.Series([1, 2, 3, 1], dtype="category") В [98]: s = s.cat.set_categories([2, 3, 1], order=True) В [99]: с Вышли[99]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [100]: s.
Изменение порядка
Изменение порядка категорий возможно через Категориальная.reorder_categories() и метода Categorical.set_categories() . Для Categorical.reorder_categories() все
старые категории должны быть включены в новые категории, и никакие новые категории не допускаются. Это будет
обязательно сделайте порядок сортировки таким же, как порядок категорий.
В [103]: s = pd.Series([1, 2, 3, 1], dtype="category") В [104]: s = s.cat.reorder_categories([2, 3, 1], order=True) В [105]: с Выход[105]: 0 1 1 2 2 3 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [106]: s.sort_values(inplace=True) В [107]: с Выход[107]: 1 2 2 3 0 1 3 1 тип: категория Категории (3, int64): [2 < 3 < 1] В [108]: s.min(), s.max() Исход[108]: (2, 1)
Примечание
Обратите внимание на разницу между назначением новых категорий и изменением порядка категорий: первая
переименовывает категории и, следовательно, отдельные значения в серии , но если первый
позиция была отсортирована последней, переименованное значение все равно будет отсортировано последним. Переупорядочивание означает, что
способ сортировки значений впоследствии отличается, но не отдельные значения в Серия изменена.
Примечание
Если Категориальный не заказан, Series.min() и Series.max() поднимет Типовая ошибка . Числовые операции типа +, -, *, / и операции на их основе
(например, Series.median() , который должен был бы вычислить среднее между двумя значениями, если длина
массива четные) не работают и поднимают TypeError .
Сортировка по нескольким столбцам
Категориальный столбец dtyped будет участвовать в сортировке по нескольким столбцам так же, как и другие столбцы.
Порядок категориального определяется категории этого столбца.
В [109]: dfs = pd.DataFrame(
.....: {
.....: "A": pd.Категорический(
.....: список("ббиббаа"),
.....: категории=["е", "а", "б"],
. ....: заказано=Истина,
.....: ),
.....: "В": [1, 2, 1, 2, 2, 1, 2, 1],
.....: }
.....: )
.....:
В [110]: dfs.sort_values(by=["A", "B"])
Выход[110]:
А Б
2 е 1
3 е 2
7 в 1
6 в 2
0 б 1
5 б 1
1 б 2
4 б 2
Изменение порядка категорий изменяет будущую сортировку.
В [111]: dfs["A"] = dfs["A"].cat.reorder_categories(["a", "b", "e"]) В [112]: dfs.sort_values(by=["A", "B"]) Выход[112]: А Б 7 в 1 6 в 2 0 б 1 5 б 1 1 б 2 4 б 2 2 е 1 3 е 2
Сравнения
Сравнение категориальных данных с другими объектами возможно в трех случаях:
Сравнение равенства (
==и!=) с объектом, подобным списку (список, серия, массив, …) той же длины, что и категориальные данные.Все сравнения (
==,!=,>,>=,<и<=) категориальных данных с другой категориальный ряд, когдазаказал == Правдаикатегорииодинаковы.Все сравнения категориальных данных со скаляром.
Все другие сравнения, особенно сравнения «не на равенство» двух категорий с разными
категории или категориальный с любым объектом, подобным списку, поднимет Ошибка типа .
Примечание
Любые сравнения категорийных данных «не на равенство» с серией , np.array , list или
категориальные данные с разными категориями или порядком вызовут TypeError , потому что пользовательские
порядок категорий можно интерпретировать двояко: один с учетом
заказ и один без.
В [113]: cat = pd.Series([1, 2, 3]).astype(CategoricalDtype([3, 2, 1], order=True)) В [114]: cat_base = pd.Series([2, 2, 2]).astype(CategoricalDtype([3, 2, 1], order=True)) В [115]: cat_base2 = pd.Series([2, 2, 2]).astype(CategoricalDtype(ordered=True)) В [116]: кошка Выход[116]: 0 1 1 2 2 3 тип: категория Категории (3, int64): [3 < 2 < 1] В [117]: cat_base Выход[117]: 0 2 1 2 2 2 тип: категория Категории (3, int64): [3 < 2 < 1] В [118]: cat_base2 Выход[118]: 0 2 1 2 2 2 тип: категория Категории (1, int64): [2]
Сравнение с категориальным с теми же категориями и порядком или со скаляром работает:
В [119]: cat > cat_base Выход[119]: 0 Верно 1 Ложь 2 Ложь тип: логический В [120]: кошка > 2 Выход[120]: 0 Верно 1 Ложь 2 Ложь тип: логический
Сравнение на равенство работает с любым спископодобным объектом одинаковой длины и скаляров:
В [121]: cat == cat_base Выход[121]: 0 Ложь 1 правда 2 Ложь тип: логический В [122]: cat == np.
Это не работает, потому что категории не совпадают:
В [124]: попробуйте:
.....: кошка > cat_base2
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: Категориалы можно сравнивать только в том случае, если «категории» одинаковы.
Если вы хотите выполнить сравнение «неравенства» категориального ряда со спископодобным объектом которые не являются категориальными данными, вам нужно быть явным и преобразовать категориальные данные обратно в исходные значения:
В [125]: база = np.array([1, 2, 3])
В [126]: попробуйте:
.....: кошка > база
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно сравнить категориальное для op __gt__ с типом .
Если вы хотите сравнить значения, используйте «np.asarray(cat) other».
В [127]: np.asarray(cat) > base
Выход[127]: массив([Ложь, Ложь, Ложь])
При сравнении двух неупорядоченных категорий с одинаковыми категориями порядок не учитывается:
В [128]: c1 = pd.Categorical(["a", "b"], Categories=["a", "b"], order=False) В [129]: c2 = pd.Categorical(["a", "b"], Categories=["b", "a"], order=False) В [130]: с1 == с2 Выход[130]: массив([Истина, Истина])
Операции
Кроме Series.min() , Series.max() и Series.mode() ,
Следующие операции возможны с категориальными данными:
Методы Series , такие как Series.value_counts() , будут использовать все категории,
даже если некоторые категории отсутствуют в данных:
В [131]: s = pd.Series(pd.Categorical(["a", "b", "c", "c"], Categories=["c", "a", "b", "д"])) В [132]: s.value_counts() Выход[132]: с 2 1 б 1 д 0 тип: int64
Методы DataFrame , такие как DataFrame.sum() , также показывают «неиспользуемые» категории.
В [133]: columns = pd.Categorical( .....: ["Один", "Один", "Два"], category=["Один", "Два", "Три"], order=True .....: ) .....: В [134]: df = pd.DataFrame( .....: данные=[[1, 2, 3], [4, 5, 6]], .....: столбцы = pd.MultiIndex.from_arrays ([["A", "B", "B"], столбцы]), .....: ) .....: В [135]: df.sum(ось=1, уровень=1) Выход[135]: Раз два три 0 3 3 0 1 96 0
Groupby также покажет «неиспользуемые» категории:
В [136]: кошки = pd.Categorical(
.....: ["a", "b", "b", "b", "c", "c", "c"], category=["a", "b", "c" , "д"]
.....: )
.....:
В [137]: df = pd.DataFrame({"кошки": кошки, "значения": [1, 2, 2, 2, 3, 4, 5]})
В [138]: df.groupby("кошки").mean()
Исход[138]:
ценности
кошки
1,0
б 2.0
с 4.0
г NaN
В [139]:cats2 = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c"])
В [140]: df2 = pd.DataFrame(
.....: {
.....: "коты": коты2,
.....: "В": ["в", "д", "в", "д"],
.....: "значения": [1, 2, 3, 4],
.....: }
. ....: )
.....:
В [141]: df2.groupby(["кошки", "B"]).mean()
Выход[141]:
ценности
кошки Б
а в 1,0
д 2.0
б в 3,0
д 4,0
в в NaN
г NaN
Сводные таблицы:
В [142]: raw_cat = pd.Categorical(["a", "a", "b", "b"], Categories=["a", "b", "c" ])
В [143]: df = pd.DataFrame({"A": raw_cat, "B": ["c", "d", "c", "d"], "values": [1, 2, 3 , 4]})
В [144]: pd.pivot_table(df, values="values", index=["A", "B"])
Исход[144]:
ценности
А Б
а с 1
д 2
б в 3
д 4
Подмена данных
Оптимизированные методы доступа к данным pandas .loc , .iloc , .at и .иат ,
работать как обычно. Единственная разница заключается в типе возврата (для получения) и
что только значения уже в категориях могут быть назначены.
Получение
Если операция нарезки возвращает либо DataFrame , либо столбец типа Series , сохраняется категория dtype.
В [145]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n"])
В [146]: кошки = pd.Series(["a", "b", "b", "b", "c", "c", "c"], dtype="category", index=idx )
В [147]: значения = [1, 2, 2, 2, 3, 4, 5]
В [148]: df = pd.DataFrame({"кошки": кошки, "значения": значения}, index=idx)
В [149]: df.iloc[2:4, :]
Исход[149]:
кошачьи ценности
дж б 2
к б 2
В [150]: df.iloc[2:4, :].dtypes
Выход[150]:
категория кошек
значения int64
тип: объект
В [151]: df.loc["h":"j", "кошки"]
Выход[151]:
ч а
я б
дж б
Имя: кошки, dtype: категория
Категории (3, объект): ['a', 'b', 'c']
В [152]: df[df["кошки"] == "b"]
Выход[152]:
кошачьи ценности
я б 2
дж б 2
к б 2
Пример, когда тип категории не сохраняется, если взять один единственный
ряд: получившаяся Серия имеет dtype объект :
# получить полную строку "h" как серию В [153]: df.loc["h", :] Исход[153]: кошки а значения 1 Имя: h, dtype: объект
При возврате одного элемента из категориальных данных также будет возвращено значение, а не категориальное
длины «1».
В [154]: df.iat[0, 0] Ушел[154]: 'а' В [155]: df["cats"].cat.categories = ["x", "y", "z"] В [156]: df.at["h", "cats"] # возвращает строку Выход[156]: 'x'
Примечание
В отличие от функции R factor , где factor(c(1,2,3))[1] возвращает одно значение фактор .
Чтобы получить одно значение Series типа категории , вы передаете список с
одно значение:
В [157]: df.loc[["h"], "cats"] Вышли[157]: ч х Имя: кошки, dtype: категория Категории (3, объект): ['x', 'y', 'z']
Средства доступа String и datetime
Средства доступа .dt и .str будет работать, если s.cat.categories имеют
соответствующий тип:
В [158]: str_s = pd.Series(list("aabb"))
В [159]: str_cat = str_s.astype("категория")
В [160]: str_cat
Выход[160]:
0 а
1 год
2 б
3 б
тип: категория
Категории (2, объект): ['a', 'b']
В [161]: str_cat.str.contains("a")
Исход[161]:
0 Верно
1 правда
2 Ложь
3 Ложь
тип: логический
В [162]: date_s = pd. Series(pd.date_range("1/1/2015", периоды=5))
В [163]: date_cat = date_s.astype("категория")
В [164]: date_cat
Исход[164]:
0 01.01.2015
1 2015-01-02
2 2015-01-03
3 2015-01-04
4 2015-01-05
тип: категория
Категории (5, datetime64[ns]): [2015-01-01, 2015-01-02, 2015-01-03, 2015-01-04, 2015-01-05]
В [165]: date_cat.dt.day
Исход[165]:
0 1
1 2
2 3
3 4
4 5
тип: int64
Примечание
Возвращенный Series (или DataFrame ) имеет тот же тип, как если бы вы использовали .str.<метод> / .dt.<метод> на серии этого типа (и не
тип категория !).
Это означает, что возвращаемые значения из методов и свойств методов доступа Серия и возвращаемые значения из методов и свойств средств доступа этого Серия преобразована в тип категория будет равна:
В [166]: ret_s = str_s.str.contains("a")
В [167]: ret_cat = str_cat.str.contains("a")
В [168]: ret_s. dtype == ret_cat.dtype
Выход[168]: Верно
В [169]: ret_s == ret_cat
Вышли[169]:
0 Верно
1 правда
2 Правда
3 Правда
тип: логический
Примечание
Работа выполняется по категории , а затем создается новая серия . Это имеет
некоторое влияние на производительность, если у вас есть Series типа string, где много элементов
повторяются (т.е. количество уникальных элементов в Серия намного меньше, чем
длина серии ). В этом случае может быть быстрее преобразовать исходный серии к одному из типов категории и используйте для этого .str.<метод> или .dt.<свойство> .
Настройка
Установка значений в категориальном столбце (или Серия ) работает до тех пор, пока
значение включено в категории :
В [170]: idx = pd.Index(["h", "i", "j", "k", "l", "m", "n" ]) В [171]: кошки = pd.Categorical(["а", "а", "а", "а", "а", "а", "а"], категории = ["а", "б "]) В [172]: значения = [1, 1, 1, 1, 1, 1, 1] В [173]: df = pd.
Установка значений путем присвоения категориальных данных также проверяет соответствие категорий :
В [177]: df.loc["j":"k", "cats"] = pd.Categorical(["a" , "а"], категории=["а", "б"])
В [178]: дф
Вышли[178]:
кошачьи ценности
ч а 1
я 1
Дж а 2
к а 2
л а 1
м а 1
п а 1
В [179]: попробуйте:
.....: df.loc["j":"k", "кошки"] = pd.Categorical(["b", "b"], Categories=["a", "b", "c "])
.....: кроме ValueError как e:
.....: print("ValueError:", ул(е))
.....:
ValueError: невозможно установить категориальный с другим, без идентичных категорий
При присвоении Категориального частям столбца других типов будут использоваться значения:
В [180]: df = pd.
Слияние/конкатенация
По умолчанию объединение Series или DataFrames , содержащих одинаковые
категории приводит к категории dtype, в противном случае результаты будут зависеть от
dtype базовых категорий. Слияния, которые приводят к некатегоричности
dtypes, вероятно, будут использовать больше памяти. Используйте .astype или union_categoricals для обеспечения результатов категории .
В [185]: из pandas.api.types import union_categoricals # те же категории В [186]: s1 = pd.Series(["a", "b"], dtype="category") В [187]: s2 = pd.Series(["a", "b", "a"], dtype="category") В [188]: pd.
В следующей таблице приведены результаты объединения категорий :
arg1 аргумент2 идентичный результат | |||
|---|---|---|---|
категория | категория | Правда | категория |
категория (объект) | категория (объект) | Ложь | объект (выводится dtype) |
категория (внутренняя) | категория (плавающая) | Ложь | с плавающей запятой (предполагается dtype) |
См. также раздел о типах слияния для заметок о
сохранение типов слияния и производительности.
Объединение
Если вы хотите объединить категории, которые не обязательно имеют одинаковые
категории, функция union_categoricals() будет
объединить список подобных категорий. Новые категории будут представлять собой объединение
категории объединяются.
В [196]: из pandas.api.types import union_categoricals В [197]: a = pd.Categorical(["b", "c"]) В [198]: b = pd.Categorical(["a", "b"]) В [199]: union_categoricals([a, b]) Вышли[199]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a']
По умолчанию результирующие категории будут упорядочены как
они появляются в данных. Если вы хотите, чтобы категории
для лексической сортировки используйте аргумент sort_categories=True .
В [200]: union_categoricals([a, b], sort_categories=True) Выход[200]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals также работает с «простым» случаем объединения двух
категории тех же категорий и информация о заказе
(например, что вы могли бы также добавить для).
В [201]: a = pd.Categorical(["a", "b"], order=True) В [202]: b = pd.Categorical(["a", "b", "a"], order=True) В [203]: union_categoricals([a, b]) Выход[203]: ['а', 'б', 'а', 'б', 'а'] Категории (2, объект): ['a' < 'b']
Приведенное ниже вызывает TypeError , поскольку категории упорядочены и не идентичны.
В [1]: a = pd.Categorical(["a", "b"], order=True) В [2]: b = pd.Categorical(["a", "b", "c"], order=True) В [3]: union_categoricals([a, b]) Выход[3]: TypeError: для объединения упорядоченных категорий все категории должны быть одинаковыми
Упорядоченные категории с различными категориями или порядками могут быть объединены с помощью
используя аргумент ignore_ordered=True .
В [204]: a = pd.Categorical(["a", "b", "c"], order=True) В [205]: b = pd.Categorical(["c", "b", "a"], order=True) В [206]: union_categoricals([a, b], ignore_order=True) Исход[206]: ['а', 'б', 'в', 'в', 'б', 'а'] Категории (3, объект): ['a', 'b', 'c']
union_categoricals() также работает с Категориальный индекс или Серия , содержащая категориальные данные, но обратите внимание, что
результирующий массив всегда будет простым Категориальный :
В [207]: a = pd.
Примечание
union_categoricals может перекодировать целые коды для категорий
при объединении категорий. Это, вероятно, то, что вы хотите,
но если вы полагаетесь на точную нумерацию категорий, будьте
осведомленный.
В [210]: c1 = pd.Categorical(["b", "c"]) В [211]: c2 = pd.Categorical(["a", "b"]) В [212]: с1 Выход[212]: ['до н.э'] Категории (2, объект): ['b', 'c'] # "b" кодируется как 0 В [213]: c1.codes Выход[213]: массив([0, 1], dtype=int8) В [214]: с2 Выход[214]: ['а', 'б'] Категории (2, объект): ['a', 'b'] # "b" кодируется как 1 В [215]: c2.codes Выход[215]: массив([0, 1], dtype=int8) В [216]: c = union_categoricals([c1, c2]) В [217]: в Выход[217]: ['б', 'в', 'а', 'б'] Категории (3, объект): ['b', 'c', 'a'] # "b" везде кодируется как 0, так же, как c1, но отличается от c2 В [218]: c.
Получение/вывод данных
Вы можете записать данные, содержащие категории dtypes, в хранилище HDFStore .
См. здесь пример и предостережения.
Также можно записывать данные и считывать данные из файлов формата Stata . См. здесь пример и предостережения.
Запись в CSV-файл преобразует данные, эффективно удаляя любую информацию о
категориальные (категории и порядок). Поэтому, если вы читаете файл CSV, вам нужно преобразовать
соответствующие столбцы назад к категория и назначьте правильные категории и порядок категорий.
В [219]: импорт io В [220]: s = pd.Series(pd.Categorical(["a", "b", "b", "a", "a", "d"])) # переименовать категории В [221]: s.cat.categories = ["очень хорошо", "хорошо", "плохо"] # изменить порядок категорий и добавить недостающие категории В [222]: s = s.cat.set_categories(["очень плохо", "плохо", "средне", "хорошо", "очень хорошо"]) В [223]: df = pd.
То же самое верно для записи в базу данных SQL с to_sql .
Отсутствующие данные
pandas в основном использует значение np.nan для представления отсутствующих данных. Это по
по умолчанию не включены в расчеты. См. раздел «Отсутствующие данные».
Отсутствующие значения должны быть включены , а не в категории категории ,
только в значения .
Вместо этого понятно, что NaN отличается и всегда возможен.
При работе с Категориальным коды , пропущенные значения всегда будут
код -1 .
В [233]: s = pd.Series(["a", "b", np.nan, "a"], dtype="category") # только две категории В [234]: с Выход[234]: 0 а 1 б 2 NaN 3 часа тип: категория Категории (2, объект): ['a', 'b'] В [235]: s.cat.codes Выход[235]: 0 0 1 1 2 -1 3 0 тип: int8
Методы работы с отсутствующими данными, т.е. исна () , заполнение () , dropna() , все работает нормально:
В [236]: s = pd.Series(["a", "b", np.
Различия с факторами R
Можно наблюдать следующие отличия функций факторов R:
уровней Rназваныкатегориями.Уровни
Rвсегда имеют строковый тип, а категорииНевозможно указать метки во время создания. Используйте
s.cat.rename_categories(new_labels)после.В отличие от функции R
factor, использование категориальных данных в качестве единственного входа для создания новая категорийная серия будет , а не удалить неиспользуемые категории, но создать новый категориальный ряд что равно переданному за единицу!R позволяет включать отсутствующие значения в свои
уровней(категории pandas). панды
не допускает категорий NaN, но пропущенные значения все еще могут быть в значениях
Подвохи
Использование памяти
Использование памяти Категорий пропорционально числу категорий плюс длина данных. Наоборот, объект dtype — это константа, умноженная на длину данных.
В [240]: s = pd.Series(["foo", "bar"] * 1000)
# тип объекта
В [241]: s.nbytes
Выход[241]: 16000
# категория dtype
В [242]: s.astype("category").nbytes
Вышло[242]: 2016 г.
Примечание
Если количество категорий приближается к длине данных, Категориальный будет использовать почти такое же или
больше памяти, чем эквивалентное представление объекта dtype.
В [243]: s = pd.Series(["foo%04d" % i для i в диапазоне (2000)])
# тип объекта
В [244]: s.nbytes
Выход[244]: 16000
# категория dtype
В [245]: s.astype("category").nbytes
Выход[245]: 20000
Категориальный не является массивом numpy В настоящее время категориальные данные и базовый Категориальный реализованы как Python
объект, а не как низкоуровневый массив NumPy dtype. Это приводит к некоторым проблемам.
Сам NumPy не знает о новом dtype :
В [246]: попробуйте:
.....: np.dtype ("категория")
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: тип данных «категория» не понят
В [247]: dtype = pd.Categorical(["a"]).dtype
В [248]: попробуйте:
.....: np.dtype(dtype)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: невозможно интерпретировать «CategoricalDtype (categories = ['a'], Ordered = False)» как тип данных
Сравнения Dtype работают:
В [249]: dtype == np.str_ Выход[249]: Ложь В [250]: np.str_ == dtype Выход[250]: Ложь
Чтобы проверить, содержит ли серия категориальные данные, используйте hasattr(s, 'cat') :
В [251]: hasattr(pd.Series(["a"], dtype="category"), " кошка") Выход[251]: Истина В [252]: hasattr(pd.Series(["a"]), "cat") Выход[252]: Ложь
Использование функций NumPy на серии типа категории не должно работать как Категориальные не являются числовыми данными (даже в том случае, если . является числовым). categories
В [253]: s = pd.Series(pd.Categorical([1, 2, 3, 4]))
В [254]: попробуйте:
.....: np.sum(s)
.....: кроме TypeError как e:
.....: print("TypeError:", str(e))
.....:
TypeError: «Категорический» не реализует сокращение «сумма»
Примечание
Если такая функция работает, сообщите об ошибке на https://github.com/pandas-dev/pandas!
dtype в приложении
pandas в настоящее время не сохраняет dtype в функциях применения: если вы применяете по строкам, вы получаете Series of object dtype (так же, как получение строки -> получение одного элемента вернет
базовый тип) и применение вдоль столбцов также преобразуется в объект. NaN Значения не изменяются.
Вы можете использовать fillna для обработки пропущенных значений перед применением функции.
В [255]: df = pd.DataFrame(
.....: {
.....: "а": [1, 2, 3, 4],
.....: "б": ["а", "б", "в", "д"],
. ....: "кошки": pd.Categorical([1, 2, 3, 2]),
.....: }
.....: )
.....:
В [256]: df.apply(лямбда-строка: тип(строка["кошки"]), ось=1)
Исход[256]:
0 <класс 'целое число'>
1 <класс 'целое число'>
2 <класс 'целое число'>
3 <класс 'целое число'>
тип: объект
В [257]: df.apply(лямбда-столбец: col.dtype, ось=0)
Исход[257]:
int64
б объект
категория кошек
тип: объект
Категориальный индекс
CategoricalIndex — тип индекса, полезный для поддержки
индексация с дубликатами. Это контейнер вокруг категории и позволяет эффективно индексировать и хранить индекс с большим количеством повторяющихся элементов.
Более подробные сведения см. в документации по расширенному индексированию.
объяснение.
Установка индекса создаст CategoricalIndex :
В [258]: кошки = pd.Categorical([1, 2, 3, 4], Categories=[4, 2, 3, 1])
В [259]: строки = ["a", "b", "c", "d"]
В [260]: значения = [4, 2, 3, 1]
В [261]: df = pd.DataFrame({"strings": строки, "values": значения}, index=cats)
В [262]: df. index
Out[262]: CategoricalIndex([1, 2, 3, 4], Categories=[4, 2, 3, 1], Ordered=False, dtype='category')
# Теперь это сортируется по порядку категорий
В [263]: df.sort_index()
Исход[263]:
строковые значения
4 д 1
2 б 2
3 с 3
1 а 4
Побочные эффекты
Создание серии из Категориальный не будет копировать ввод Категориальный . Это означает, что изменения в серии в большинстве случаев
изменить исходный Категориальный :
В [264]: cat = pd.Categorical([1, 2, 3, 10], Categories=[1, 2, 3, 4, 10]) В [265]: s = pd.Series(cat, name="cat") В [266]: кошка Исход[266]: [1, 2, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [267]: s.iloc[0:2] = 10 В [268]: кошка Исход[268]: [10, 10, 3, 10] Категории (5, int64): [1, 2, 3, 4, 10] В [269]: df = pd.DataFrame(s) В [270]: df["cat"].cat.categories = [1, 2, 3, 4, 5] В [271]: кошка Исход[271]: [5, 5, 3, 5] Категории (5, int64): [1, 2, 3, 4, 5]
Используйте copy=True , чтобы предотвратить такое поведение или просто не используйте повторно Категориалы :
В [272]: cat = pd.
Примечание
Это также происходит в некоторых случаях, когда вы предоставляете массив NumPy вместо Категориальный :
использование массива int (например, np.array([1,2,3,4]) ) будет демонстрировать такое же поведение, при использовании
массив строк (например, np.array(["a","b","c","a"]) ) не будет.
Шкала ураганного ветра Saffir-Simpson
Анализы и прогнозы
- Продукция для тропических циклонов
- Прогноз погоды в тропиках
- Морские продукты
- Аудио/Подкасты
- RSS-каналы
- Продукты ГИС
- Альтернативные форматы
- Тропический циклон Описание продукта
- Описание морской продукции
▾
Данные и инструменты
- Спутниковые снимки
- Радиолокационные изображения
- Самолет-разведчик
- Инструменты для тропического анализа
- Экспериментальные продукты
- Калькулятор широты/долготы
- Пустые карты отслеживания
▾
Образовательные ресурсы
- Будьте готовы!
Ураган NWS
Неделя подготовки - NWS Защита от ураганов
- Информационная документация
- Штормовой нагон
- Контрольные точки/предупреждения
- Климатология
- Названия тропических циклонов
- Шкала ветра
- Записи и факты
- Исторические сводки об ураганах
- Прогнозные модели
- Публикации NHC
- Глоссарий NHC
- Акронимы
- Часто задаваемые вопросы
- Будьте готовы!
▾
Архивы
- Информационные бюллетени по тропическим циклонам
- Прогноз погоды в тропиках
- Отчеты о тропических циклонах
- Проверка прогноза тропических циклонов
- Сводка сезона атлантического течения
- E. Сводка текущего сезона Pacific
- C. Резюме текущего сезона Pacific
- Архив новостей NHC
- Объявления о продуктах и услугах
- Другие архивы: HURDAT,
Track Maps,
Marine Products,
и другие
▾
О
- Национальный центр ураганов
- Центральная часть Тихого океана
Центр ураганов - Свяжитесь с нами
▾
Поиск
ИщиNWS Все NOAA
▾
Климатология | Имена | Шкала ветра | Крайности | Модели | Точки останова
Шкала ураганного ветра Саффира-Симпсона представляет собой оценку от 1 до 5, основанную только на максимальной устойчивой скорости ветра урагана. Эта шкала не учитывает другие потенциально смертельные опасности, такие как штормовые нагоны, ливневые наводнения и торнадо.
Шкала ураганного ветра Saffir-Simpson оценивает потенциальный материальный ущерб. В то время как все ураганы вызывают опасные для жизни ветры, ураганы категории 3 и выше известны как сильные ураганы*. Сильные ураганы могут причинить разрушительный или катастрофический ущерб ветру и привести к значительным человеческим жертвам просто из-за силы их ветра. Ураганы всех категорий могут вызывать смертоносные штормовые волны, вызванные дождями наводнения и торнадо. Эти опасности требуют от людей принятия защитных мер, включая эвакуацию из районов, уязвимых для штормовых нагонов.
* В западной части северной части Тихого океана термин «супертайфун» используется для тропических циклонов с устойчивыми ветрами, превышающими 150 миль в час.
| Категория | Постоянный ветер | Виды повреждений из-за ураганных ветров |
|---|---|---|
| | ||
| 1 | 74-95 миль/ч 64-82 узла 119-153 км/ч | Очень опасные ветры могут причинить некоторые повреждения: в хорошо сконструированных каркасных домах могут быть повреждены крыша, черепица, виниловый сайдинг и водосточные желоба. Большие ветки деревьев ломаются, а деревья с неглубокими корнями могут быть повалены. Обширные повреждения линий электропередач и столбов, вероятно, приведут к перебоям в подаче электроэнергии, которые могут длиться от нескольких до нескольких дней. |
| 2 | 96-110 миль/ч 83-95 узлов 154-177 км/ч | Чрезвычайно опасные ветры нанесут значительный ущерб: Хорошо построенные каркасные дома могут выдержать серьезные повреждения крыши и сайдинга. Многие деревья с неглубокими корнями будут сломаны или вырваны с корнем, что заблокирует многочисленные дороги. Ожидается почти полная потеря электроэнергии с перебоями, которые могут длиться от нескольких дней до недель. |
| 3 (основной) | 111-129 миль/ч 96-112 узлов 178-208 км/ч | Будет нанесен сокрушительный урон:
Хорошо построенные каркасные дома могут подвергнуться серьезному повреждению или удалению настила крыши и концов фронтонов. Многие деревья будут сломаны или вырваны с корнем, что заблокирует многочисленные дороги. Электричество и вода будут недоступны в течение нескольких дней или недель после окончания урагана. |
| 4 (основной) | 130-156 миль/ч 113-136 узлов 209-251 км/ч | Произойдет катастрофический ущерб: Хорошо построенные каркасные дома могут получить серьезные повреждения с потерей большей части конструкции крыши и / или некоторых наружных стен. Большинство деревьев будет сломано или вырвано с корнем, а столбы электропередач повалены. Упавшие деревья и столбы электропередач изолируют жилые районы. Отключения электроэнергии продлятся от нескольких недель до, возможно, месяцев. Большая часть территории будет непригодна для проживания в течение нескольких недель или месяцев. |
| 5 (основной) | 157 миль/ч или выше 137 узлов или выше 252 км/ч или выше | Произойдет катастрофический ущерб:
Большой процент каркасных домов будет разрушен с полным обрушением крыши и обрушением стен. Упавшие деревья и столбы электропередач изолируют жилые районы. Отключения электроэнергии продлятся от нескольких недель до, возможно, месяцев. Большая часть территории будет непригодна для проживания в течение нескольких недель или месяцев. |
Ваш браузер не поддерживает видео тег.
Дополнительная информация
- О шкале ураганного ветра Саффира-Симпсона (PDF)
- Расширенная таблица Saffir-Simpson Hurricane Wind Scale (PDF)
- 2012 Пересмотр Шкалы ураганного ветра Саффира Симпсона (PDF)
- Штормовые волны и масштабы (PDF)
Если у вас возникли проблемы с просмотром связанных файлов, получите бесплатную программу просмотра для формата файла:
- Adobe Acrobat (pdf)
Ураган Ирма обрушился на Карибские острова как шторм категории 5 ДЖОНС, Антигуа (AP) — Ураган «Ирма» пронесся по Карибскому морю с рекордной силой рано утром в среду, сотрясая людей в их домах на островах Антигуа и Барбуда на пути к Пуэрто-Рико и, возможно, к выходным Флориде.
Ирма, самый сильный атлантический ураган, когда-либо зарегистрированный к северу от Карибского моря и к востоку от Мексиканского залива, прошел почти прямо над островом Барбуда, по данным Национального центра США по ураганам в Майами.
Власти небольших островов в восточной части Карибского моря все еще оценивали ситуацию, когда взошло солнце, хотя поступали многочисленные сообщения о наводнениях и поваленных деревьях. Полиция Антигуа дождалась, пока стихнет ветер, прежде чем отправить вертолеты для проверки отчетов о повреждениях на Барбуде. Немедленных сообщений о жертвах не поступало.
«Пока мы рады хорошим новостям, которые у нас есть до сих пор», — сказал Дональд Макфейл, исполнительный директор Управления гражданской авиации Восточного Карибского бассейна, рано утром в среду, когда он услышал от сотрудников по всему региону после ночевки. дома на Антигуа.
На острове Ангилья наблюдались «чрезвычайно сильные ветры и дожди», по данным Департамента по борьбе со стихийными бедствиями, и поступали сообщения о наводнениях, но подробностей пока нет.
Центр урагана находился примерно в 15 милях (25 км) к западу от Сент-Мартина и Ангильи около 8 часов утра в среду, сообщил центр урагана. Он двигался с запада на северо-запад со скоростью 16 миль в час (26 км/ч).
Когда глаз урагана Ирма прошел над Барбудой около 2 часов ночи, телефонные линии вышли из строя из-за проливного дождя и завывающего ветра, который разбрасывал обломки, когда люди ютились в своих домах или правительственных убежищах.
На Барбуде ураган сорвал крышу с полицейского участка острова, вынудив офицеров искать убежища в пожарной части и в общественном центре, который служил официальным убежищем. Шторм 5-й категории также прервал связь между островами. Мидси Фрэнсис из Национального управления по ликвидации последствий стихийных бедствий подтвердил, что несколько домов были повреждены, но сказал, что еще слишком рано оценивать степень ущерба.
По данным Центра ураганов, максимальная скорость ветра во время шторма составляла 185 миль в час (295 км/ч). В нем говорится, что ветер, вероятно, будет немного колебаться, но шторм останется на уровне 4 или 5 категории в течение следующих дня или двух. Согласно прогнозам, самые опасные ветры, обычно ближайшие к глазу, в среду будут проходить вблизи северных Виргинских островов и недалеко или к северу от Пуэрто-Рико.
Президент Дональд Трамп объявил чрезвычайные ситуации во Флориде, Пуэрто-Рико и Виргинских островах США, а власти Багамских островов заявили, что эвакуируют шесть южных островов.
Теплая вода является топливом для ураганов, и Ирма двигалась над водой, которая была на 1,8 градуса (1 градус Цельсия) теплее, чем обычно. Вода с температурой 79 градусов (26 по Цельсию), необходимая для ураганов, ушла на глубину около 250 футов (80 метров), сказал Джефф Мастерс, директор по метеорологии частной службы прогнозирования Weather Underground.
Четыре других шторма сопровождались такими же сильными ветрами во всем Атлантическом регионе, но они были в Карибском море или Мексиканском заливе, вода в которых обычно теплее. Ураган Аллен достиг 190 миль в час в 1980 году, в то время как Вильма 2005 года, Гилберт 1988 года и великий шторм Флорида-Кис 1935 года имели скорость ветра 185 миль в час.
Ожидается, что на северных Подветренных островах нормальный уровень прилива поднимется на целых 11 футов (3,3 метра), в то время как на островах Теркс и Кайкос и на юго-востоке Багамских островов может наблюдаться подъем волн на 20 футов (6 метров) и выше позже в неделе, говорят синоптики.
Премьер-министр Багамских островов Хьюберт Миннис заявил, что его правительство эвакуирует шесть островов на юге, потому что власти не смогут помочь никому, кто попал в «потенциально катастрофический» ветер, наводнение и штормовой нагон. Людей оттуда отправят в Нассау, что, по его словам, станет крупнейшей эвакуацией из-за шторма в истории страны.
«Цена, которую вы можете заплатить за отказ от эвакуации, — это ваша жизнь или серьезный физический вред», — сказал Миннис.
Национальная метеорологическая служба США заявила, что Пуэрто-Рико не видел урагана такой силы, как Ирма, со времен урагана Сан-Фелипе в 1928 году, в результате которого погибло 2748 человек в Гваделупе, Пуэрто-Рико и Флориде.
«Опасность этого события не похожа ни на что, что мы когда-либо видели», — сказал губернатор Пуэрто-Рико Рикардо Росселло. «Большая часть инфраструктуры не сможет противостоять такой силе».
Ожидалось, что центр шторма пойдет на запад по пути, пролегающему немного севернее Пуэрто-Рико, Доминиканской Республики, Гаити и Кубы.
В северных частях Доминиканской Республики и на Гаити выпало 10 дюймов (25 сантиметров) дождя, а на юго-востоке Багамских островов и островов Теркс и Кайкос — до 20 дюймов (50 сантиметров).
Шторм почти наверняка обрушится на Соединенные Штаты к началу следующей недели.
«Трудно найти модель, которая не оказала бы влияния на Флориду». — сказал старший исследователь ураганов Университета Майами Брайан Макнолди.
Во Флориде люди запаслись питьевой водой и другими припасами.
Губернатор Флориды Рик Скотт задействовал 100 членов Национальной гвардии Флориды для развертывания по всему штату, а 7000 членов Национальной гвардии должны были явиться на дежурство в пятницу, когда шторм мог приближаться к этому району. В понедельник Скотт объявил чрезвычайное положение во всех 67 округах Флориды.
Чиновники во Флорида-Кис подготовились, чтобы убрать туристов и жителей с пути Ирмы, а мэр округа Майами-Дейд заявил, что люди должны быть готовы эвакуировать Майами-Бич и большинство прибрежных районов.
Мэр Карлос Хименес сказал, что добровольная эвакуация может начаться уже в среду вечером. Он активировал оперативный штаб и призвал жителей запастись едой и водой на три дня.
Центр ураганов в Майами сообщил, что ураганные ветры распространялись на 50 миль (85 километров) от центра Ирмы, а тропические штормовые ветры распространялись на 175 миль (280 километров).
Также в среду утром в Мексиканском заливе у побережья Мексики образовался новый тропический шторм. Тропический шторм Катя имел максимальную скорость ветра 40 миль в час (65 км / ч) с некоторым усилением прогноза в течение следующих двух дней. Но центр ураганов сообщил, что Катя, как ожидается, останется в море до утра пятницы.
Ожидалось, что еще один тропический шторм дальше на восток в Атлантике перерастет в ураган к ночи среды. Максимальная скорость ветра во время тропического шторма Хосе увеличилась почти до 60 миль в час (95 км/ч). Центр шторма находился примерно в 1255 милях (2020 км) к востоку от Малых Антильских островов и двигался на запад со скоростью около 13 миль в час (20 км/ч).
___
Авторы Associated Press, участвовавшие в подготовке этого отчета, включали Данику Кото из Пуэрто-Рико; Сет Боренштейн в Вашингтоне; Майкл Вайссенштейн в Гаване, Куба; Бен Фокс из Майами внес свой вклад в этот отчет.
Плагины отнесены к категории | WordPress.org
Нет базы категорий (WPML)
Этот плагин удаляет обязательную «базу категорий» из постоянных ссылок вашей категории. Он совместим с WPML.
Мариос Александру Более 100 000 активных установок Протестировано с 5.9.4 Обновлено 7 месяцев назад
TaxoPress — это менеджер тегов, категорий и таксономии WordPress
TaxoPress позволяет вам управлять тегами, категориями и всеми терминами таксономии WordPress.
ТаксоПресс 70 000+ активных установок Протестировано с 6.0.2 Обновлено 3 недели назад
Виджет сообщений категории
Добавляет виджет, показывающий самые последние сообщения из одной категории.
ТипТопПресс 70 000+ активных установок Протестировано с 6.
0.2 Обновлено 3 месяца назадУдалить URL категории
Этот плагин удаляет '/category' из постоянных ссылок вашей категории. (например, /категория/моя-категория/ в /моя-категория/)
Валерио Соуза, Creativemotion 70 000+ активных установок Протестировано с 5.3.13 Обновлено 3 года назад
Показать идентификаторы
Что делает этот плагин, так это показывает наиболее удаленные идентификаторы на страницах администратора, поскольку это…
Оливер Шлёбе 60 000+ активных установок Протестировано с 6.1 Обновлено 4 месяца назад
Исключатель высшей категории
Ultimate Category Excluder позволяет быстро и легко исключать категории с главной страницы,…
Мариос Александру 50 000+ активных установок Протестировано с 5.9.4 Обновлено 4 месяца назад
Поиск и фильтрация
Поиск и фильтрация пользовательских сообщений, категорий, тегов, таксономий, дат и типов сообщений
Код Усилитель 50 000+ активных установок Протестировано с 5.
9.4 Обновлено 4 месяца назадДобавить категорию на страницы
Легко добавить категории записей на страницы WordPress
а.анкит 30 000+ активных установок Протестировано с 5.2.16 Обновлено 3 года назад
Категории библиотеки мультимедиа
Добавляет возможность использования категорий в библиотеке мультимедиа.
Джеффри-WP 30 000+ активных установок Протестировано с 6.0.2 Обновлено 4 месяца назад
Инструменты управления терминами
Позволяет объединять термины, перемещать термины между таксономиями и устанавливать родительские термины индивидуально или…
theMikeD, писатель 20 000+ активных установок Протестировано с 5.6.9 Обновлено 2 года назад
Taxonomy Images
Свяжите изображения из вашей медиатеки с категориями, тегами и пользовательскими таксономиями.
Майкл Филдс, Бен Хьюсон 10 000+ активных установок Протестировано с 5.2.16 Обновлено 3 года назад
Страницы тегов категорий
Добавляет функции категорий и тегов для ваших страниц.
Марцио Карро 10 000+ активных установок Протестировано с 5.3.13 Обновлено 2 года назад
WP No Base Permalink
Удаляет базу категорий или родительские категории или базу тегов из ваших постоянных ссылок. Совместимость с WPML…
Серджио (каллуку) 10 000+ активных установок Протестировано с 4.8.20 Обновлено 2 года назад
PS Taxonomy Expander
Делает категории, теги и пользовательские таксономии более полезными.
Хитоши Омагари 10 000+ активных установок Протестировано с 4.5.27 Обновлено 6 лет назад
Список виджетов пользовательской таксономии
Виджет «Список пользовательских таксономий» — это быстрый и простой способ отображения пользовательских таксономий.…
Ник Хэлси 10 000+ активных установок Протестировано с 6.0.2 Обновлено 2 месяца назад
Страницы с категорией и тегом
Добавление категорий и тегов к страницам.
ЯХМАН 10 000+ активных установок Протестировано с 6.