


РСА опроверг утечку данных 1 млн московских водителей от страховщиков
МОСКВА, 3 авг — ПРАЙМ. Российский союз автостраховщиков (РСА) опроверг возможность утечки личных данных более миллиона московских водителей от союза или страховых компаний, заявив, что в их базах даже нет таких полей, как в выставленной на продажу.
Ранее газета «Коммерсант» сообщила, что в интернете выставлена на продажу база личных данных около 1 миллиона автомобилистов Москвы и Подмосковья. База, по данным газеты, появилась 24 июля, ее стоимость составляет 1,5 тысячи долларов. В ней содержатся дата регистрации автомобиля, государственный регистрационный знак, марка, модель, год выпуска, фамилия, имя и отчество владельца, его телефон и дата рождения, регион регистрации, VIN-код, серия и номер свидетельства о регистрации и ПТС.
Основатель компании DeviceLock и сервиса разведки утечек DLBI Ашот Оганесян сообщил РИА Новости, что база личных данных автомобилистов Москвы и Подмосковья продается в сети уже несколько лет и ежемесячно обновляется актуальными данными, а значит, стоять за этой утечкой может инсайдер в крупной страховой компании.
«РСА опровергает возможный факт утечки информации о автовладельцах из баз союза и страховщиков: выставленные на продажу поля данных отсутствуют в их информационных системах», — заявила пресс-служба объединения.
«Так, данные о регистрации, постановке на регистрационный учет и дата снятия автомобиля с учета, это та информация, которая отсутствует у страховщиков», — говорится у сообщении.
Между тем в базе союза АИС ОСАГО содержится информация или о государственном регистрационном знаке, или о VIN-номере, а в базе РСА и страховщиков содержатся данные о номере полиса и о дате заключения договора страхования, чего нет в утекших базах данных, отметил союз.
Вдобавок в РСА обратили внимание на то, что страхователь и автовладелец не всегда совпадают, поскольку страхователь, заключивший договор, может быть иным лицом, не управляющим автомобилем.
ОСАГО онлайн 2021 — калькулятор, стоимость, покупка ОСАГО
3 причины оформить онлайн ОСАГО
- Быстро.
 Вы оформляете полис без очередей и походов в офис, он сразу приходит на электронную почту после расчета и оплаты.
Вы оформляете полис без очередей и походов в офис, он сразу приходит на электронную почту после расчета и оплаты. - Удобно. Ваш полис всегда доступен в личном кабинете, на e-mail или Passbook/PassWallet на смартфоне.
- Надежно. Более 250 пунктов урегулирования убытков по ОСАГО на территории России готовы оказать поддержку при страховом случае.
2
Транспортное средство
- Город собственника: Москва, Санкт-Петербург, Казань, другой.
- Категория ТС: A — мотоциклы, B — легковые, BE — легковые, C — грузовые, другая.
- Марка и модель автомобиля.
- Год выпуска: 2019, 2018, 2017, другой.
- VIN номер.
- Мощность двигателя, л.с.
- Период использования: 20 дней — 1 год.
- Цель использования: личная, учебная, такси, прокат, другая.
3
Клиент
- Фамилия, Имя, Отчество.
- Возраст.
- Стаж вождения.
- Удостоверение личности.
- Адрес по паспорту.
- Мобильный телефон.
4
Получение полиса
- Оформите полис еОСАГО и получите его на ваш email.
- Доставка: не требуется, вам достаточно распечатать полученный файл.
- Оплата: к оплате принимаются только карты VISA, MASTERCARD, MAESTRO и «МИР».
Согласно Указанию ЦБ РФ, договор еОСАГО начинает действовать не ранее чем через 3 дня после дня оформления.
Рекомендуем планировать покупку заранее, как минимум за 3 дня. Оформите онлайн сейчас.

Электронный полис ОСАГО такой же действительный, как бумажный.
Что понадобится для оформления ОСАГО
Паспорт страхователя и владельца автомобиля.Водительские удостоверения всех допущенных водителей.
Свидетельство о регистрации ТС.
Паспорт транспортного средства (ПТС).
Действительная диагностическая карта.
Банковская карта Visa, Mastercard или «Мир».
Покупка электронного полиса ОСАГО состоит из 3 шагов:
Расчет
Рассчитайте стоимость в калькуляторе всего за 4 этапа. Не забывайте, что электронное ОСАГО начинает действовать через 3 дня после дня оформления.
Оплата
Вы можете купить полис ОСАГО с помощью кредитных или дебетовых карт VISA, Mastercard и «Мир».
Использование
Полис е-ОСАГО можно распечатать на принтере или предъявлять для проверки с экрана смартфона или планшета.
Остерегайтесь мошенников!
Будьте внимательны, покупайте электронное ОСАГО только на официальном сайте www.rgs.ru. Не прибегайте к помощи посредников – это незаконно! Вы рискуете приобрести недействующий или фальшивый полис ОСАГО. Проверить подлинность любого полиса ОСАГО можно на сайте РСА.
Урегулирование онлайн
Вы можете оперативно проверить статус вашего выплатного дела по полису ОСАГО или заявить о наступлении страхового случая.
Другие страховые продукты «Росгосстраха»:
Купить ОСАГО
Правила оформления
- Как оформить ОСАГО онлайн?
- Зарегистрироваться в личном кабинете.
- Заполнить все данные в онлайн-калькуляторе.
- Получить расчет стоимости.
- Оплатить полис на сайте банковской картой.
- Получить ОСАГО и сопроводительные документы на email.
 org/Question»>
org/Question»>- Как продлить ОСАГО?
Если Вы уже клиент Росгосстраха, имеете доступ в личный кабинет и хотите продлить полис ОСАГО, вам нужно пройти 5 простых шагов:
- Авторизоваться в личном кабинете.
- Перейти в онлайн-калькулятор ОСАГО — все нужные данные будут уже заполнены.
- Получить стоимость пролонгации.

- Оплатить ОСАГО на сайте банковской картой.
- Получить файл и сопроводительные документы на email.
- Когда пора продлевать ОСАГО?
Продлить полис ОСАГО лучше заранее, до истечения срока действия текущего полиса, чтобы избежать перерывов в страховании.
Продлить полис ОСАГО можно не ранее, чем за 2 месяца (60 дней) до истечения его срока действия.
Напоминаем, что за просроченный полис ОСАГО и за езду без полиса предусмотрен штраф.
- Как проверить полис ОСАГО?
Подлинность полиса ОСАГО можно проверить на сайте РСА (Российского союза страховщиков).

- Какие документы нужны для онлайн-покупки ОСАГО?
Для оформления страхового полиса вам потребуются следующие документы:
- Паспорт страхователя и собственника автомобиля.
- Свидетельство о регистрации транспортного средства (СТС) или паспорт транспортного средства (ПТС), если автомобиль не поставлен на учет..
- Водительские удостоверения всех допущенных к управлению водителей, если условия договора подразумевают ограниченный перечень лиц, допущенных к управлению.
- Действующая диагностическая карта на автомобиль, если автомобиль в соответствии с законодательством РФ проходил техосмотр.
Необходимы данные всех документов для точного расчета КБМ через автоматизированную информационную систему РСА.

- Как оплатить электронное ОСАГО?
Безопасно оплатить полис можно банковской картой Visa, MasterCard, Maestro и национальной платежной картой «Мир».
Перед оплатой убедитесь, что на вашей карте подключен сервис 3DS для защиты платежей в интернете. Если вам приходят смс-коды для подтверждения онлайн-покупок, значит, 3D Secure на вашей карте активирован. Принцип и условия активации сервиса можно уточнить у вашего банка-эмитента.
- У меня новое ТС/ Я новый водитель
Если у вас новое ТС или вы впервые в жизни оформляете ОСАГО, значит, ваших данных еще нет в системе РСА.
Так как для получения полиса всем необходимо пройти эту проверку, то процедура для вас будет следующая:
- Вам нужно заполнить все шаги калькулятора, на Шаге 4 подтвердить корректность заполненных данных и нажать кнопку «Далее».
- После неуспешной проверки РСА вы увидите в том же окне форму для отправки копий ваших документов на проверку. Сделайте скан-копии или четкие фотографии всех указанных документов, добавьте их в форму и нажмите кнопку «Отправить документы на проверку». Сотрудник компании осуществит аутентификацию сведений содержащихся в сканированных копиях документов с данными указанными в калькуляторе.
- В течение 20 минут вам на email придет письмо с результатами проверки и специальной ссылкой на расчет и оплату. Авторизуйтесь в личном кабинете, перейдите по ссылке и оплатите полис.
Важно! Дата оплаты не должна совпадать с датой начала действия полиса, поэтому если полис нужен уже завтра, то оплатить его надо обязательно сегодня.
- Я проездил год без аварий, какую скидку я получу?
При оформлении полиса ОСАГО (в любом виде) применяется коэффициент, соответствующий страховой истории, содержащейся в автоматизированной информационной системе РСА (Российского союза автостраховщиков).
Скидки за безаварийное вождение (если информация о них содержится в РСА) будут применены. За каждый год безаварийной езды начисляется скидка 5%. Максимальный размер скидки за 10 лет страхования может составить 50%.
- Нужно ли заверять печатью электронный полис? Зачем нужна электронная подпись (файл sgn)?
 org/Answer»>
org/Answer»>Электронное ОСАГО — это оригинал вашего полиса.
- Распечатайте файл электронного полиса на принтере и возите с собой в машине.
- Распечатанный полис НЕ нужно заверять печатью или подписью в офисе!
- Его не нужно обменивать на бумажный полис в офисе.
Вместо печати и подписи электронное ОСАГО заверяет электронная подпись, которая приходит вместе с полисом на ваш email. Файл с подписью (sgn) не нужно открывать или распечатывать, он просто хранится у вас. Дополнительная информация о подписи есть в сопроводительном письме, которое приходит с полисом.
- Ответы на прочие вопросы.
Ответы на другие вопросы об ОСАГО (включая электронное ОСАГО и цену полиса) вы найдете в разделе Вопросы и ответы.
Вы также можете задать свой вопрос или подробно описать проблему через форму Обратной связи.
Что делать, если…
- У меня проблемы с паролем
Если вам не приходит временный пароль либо он не подходит, проверьте папку «Спам» на своем email или повторите попытку позднее.
Если не получается установить постоянный пароль, убедитесь, что он содержит не менее 6 символов, обязательно латиницей, должен содержать строчные и заглавные буквы, а также цифры.
- Ошибка «Неправильно выбран тип личного кабинета»
 org/Answer»>
org/Answer»>Убедитесь, что при входе в Личный кабинет вы выбираете правильный его тип: если вы представляете юридическое лицо, то над полем ввода email и пароля нужно отметить галочкой пункт «Отметьте, если вы являетесь юридическим лицом».
- У меня нет с собой ПТС?
Номер и серия паспорта вашего ТС указан как в самом ПТС, так и в свидетельстве о регистрации ТС (СТС):
- Уведомление «Не получено подтверждение от централизованных систем РСА»
Уведомление было получено, потому что введенные вами данные о водителях, автомобиле, собственнике не полностью совпадают с данными, которые содержатся в системе РСА.
- Убедитесь, что вы правильно заполнили все данные заявления на страхование (проверьте опечатки, даты, адреса).
- Если все необходимые условия оформления страховки выполняются, но вы все равно видите уведомление «Не получено подтверждение от централизованных систем РСА», воспользуйтесь специальной формой под расчетом и приложите скан-копии (четкие фотографии) документов, подтверждающие введенную вами информацию. Данные будут проверены сотрудником ПАО СК «Росгосстрах» в течение 20 минут, и вы сможете оформить договор на сайте в тот же день.
- Что делать при техническом сбое?
Напишите нам через Обратную связь. Чтобы проблема решилась как можно быстрее, укажите номер расчета, опишите подробно проблему и по возможности приложите скриншот экрана.

- Данные расчета сохраняются в браузере. Это можно отключить?
Вводимые вами данные сохраняются в браузере для избежания их потери. Если вы используете чужой компьютер или компьютер заражен вредоносным ПО, персональные данные могут попасть в руки злоумышленников.
Желаете отключить функцию или просто очистить поля?
Отметьте, если желаете отключить функцию сохранения вводимых данных в браузере. Очистить поля
- Не нахожу свою марку/модель ТС. Что делать?
Если вы не нашли в раскрывающемся списке свою марку (ни одно из представленных написаний не совпадает с наименованием марки ТС в ваших регистрационных документах), напишите в службу онлайн-поддержки (кнопка «Помощь» внизу экрана > «Задать свой вопрос» > выбрать тему обращения «Не нахожу марку своего ТС в списке» — мы добавим марку вашего ТС в список).

Если вы не нашли свою модель, внесите наименование модели в соответствии с данными регистрационных документов в поле «Отображать в полисе».
- Что делать, если меня остановит ГИБДД?
Распечатайте заранее файл электронного полиса на принтере и возите с собой. Эту бумагу НЕ нужно заверять печатью или подписью — она уже заверена электронной подписью и является оригиналом полиса.
Ездить с распечатанным полисом законно! ГИБДД проверяет действительность вашего полиса по базе РСА. Вы сами тоже всегда можете проверить действительность своего полиса на сайте РСА.
Если вы беспокоитесь насчет проверок ГИБДД, то на этот случай вместе с полисом на электронную почту мы присылаем памятку со ссылками на законодательство в сфере электронного ОСАГО.
Просто покажите ее сотруднику полиции.
Застраховать с ошибками: что показал новый сервис по проверке ОСАГО | Статьи
Автовладельцы могут получить штраф или вообще лишиться страховой выплаты, если при оформлении ОСАГО были указаны неверные данные. Так поступают недобросовестные посредники с целью оформить полис дешевле, а с автовладельца получить обычную сумму. Российский союз автостраховщиков (РСА) запустил сервис, с помощью которого автовладельцы самостоятельно могут проверить указанные в базе АИС ОСАГО сведения. Что делать, если в полисе обнаружились ошибки, разбирались «Известия».
Пробить по базе
Раньше на сайте РСА можно было проверить, является ли полис действующим на момент ДТП. С помощью нового сервиса автовладелец сможет узнать, какие именно параметры были указаны при оформлении полиса — марка, модель и категория транспортного средства, мощность, узнать коэффициент бонус-малус, регион использования автомобиля, количество водителей, допущенных к управлению, и т. д. И, естественно, его цену.
д. И, естественно, его цену.
В РСА сообщили «Известиям», что ограничились добавлением ключевых параметров, которые обычно искажаются недобросовестными посредниками и существенно влияют на цену полиса ОСАГО.
Что показала проверка
Кроме того, в сервисе указаны собственник и страхователь транспортного средства. И хотя все буквы, кроме первой, закрыты звездочками, имя, отчество и год рождения позволяют сопоставить указанных в остальных документах лиц. Это, как и срок действия страховки, важная информация, если ДТП уже произошло и у вас есть сомнения относительно другого участника аварии.
Между тем проверка редакцией «Известий» девяти машин и одного мотоцикла оставила много вопросов. Например, корректный результат дает поиск по серии и номеру полиса, а также по VIN автомобиля. Если искать по госномеру, система в большинстве случаев ничего не находит либо отображает данные старого полиса и прежних владельцев машины.
Фото: ИЗВЕСТИЯ/Зураб Джавахадзе
Автоэксперт Игорь Моржаретто считает, что новый сервис еще будут дорабатывать, и положительно оценил его появление.
«Только когда покупаешь новый полис, выясняется, что у тебя странный какой-то КБМ. Начинаешь выяснять самостоятельно, а для этого нужен источник информации, нужна обратная связь, где я могу сказать: «Вы, ребята, неправы, у меня по-другому», — рассказал он.
Без номера и категории
Обычно госномер не попадает в базу, если автовладелец оформил ОСАГО до того, как поставил автомобиль на учет в ГИБДД. Однако у единственного проверенного мотоцикла не оказалось ни госномера, хотя транспортное средство было поставлено на учет, ни марки и модели, ни мощности. А в качестве категории было указано загадочное: «0 Прочее (категория «с»)». Даже в РСА не смогли объяснить этот термин. В Союзе пообещали дать ответ технического специалиста, но на момент сдачи материала комментарий не предоставили.
Фото: ИЗВЕСТИЯ/Дмитрий Коротаев
Отсутствие госномера автомобиля в базе теоретически грозит добросовестному автовладельцу штрафом, когда автоматическая проверка ОСАГО с помощью камер будет запущена. Проблемы могут возникнуть, подтвердили в РСА и попросили всех, получивших полис ОСАГО до регистрации ТС, сообщить в свою страховую компанию о присвоенном автомобилю госномере.
Внимание, работают мошенники
РСА и страховщики фиксирует большое количество попыток оформить полис ОСАГО с недостоверными сведениями.
«В данном случае стоит говорить о недобросовестных «посредниках», которые, используя незнание автовладельцев, оформляют полис ОСАГО онлайн и вводят недостоверные сведения, например цель использования, мощность и т.д., снижают стоимость полиса, а затем передают клиенту иной полис с иной стоимостью, разницу присваивая себе. В практике «Согласия» есть такие прецеденты, подобные действия «посредников» носят мошеннический характер и наносят вред потребителю и репутации страховщика», — рассказала «Известиям» директор судебно-правового департамента страховой компании «Согласие» Анна Полина-Сташевская. И посоветовала оформлять полис е-ОСАГО, не требующий привлечения посредников.
Президент РСА Игорь Юргенс отметил, что в настоящее время в системе АИС ОСАГО 2.0 работают фильтры, позволяющие отсеивать попытки оформить полис ОСАГО, указав при оформлении заведомо неверные данные.
Офис страховой компании
Фото: ТАСС/Сергей Николаев
«Однако никакие технические решения не могут на 100% защитить от мошенничества», — отметил он.
И действительно, в одном из проверенных «Известиями» полисов в графе «Цель использования» было указано «Учебная езда», хотя машина используется в личных целях. Почему посредник указал ее при оформлении полиса — загадка.
«Указание в графе «Цель использования» варианта «Учебная езда» в настоящее время не влияет на формирование страховой премии по ОСАГО, а также на получение страховой выплаты в случае страхового события. Однако стоит быть внимательным, возможны случаи, когда похожая ошибка может привести к регрессу. Например, если у автомобиля есть лицензия такси, но в страховом полисе указано, что транспортное средство используется для личных целей, в случае аварии страховая компания может выставить регресс лицу, причинившему вред», — рассказали в пресс-службе «Альфастрахования». Кроме того, если полис окажется оформленным на другую машину или другого страхователя, пострадавшему в ДТП вообще могут отказать в страховой выплате.
Ваш полис недействителен
Какой процент неверных сведений в полисе сделает его недействительным? Для договоров ОСАГО нет такого понятия — «процент неправильно указанных данных», уточнили в РСА. В Союзе добавили, что в каждом конкретном случае необходимо разбираться, была ли допущена опечатка или случайная ошибка либо данные были введены заведомо неверно.
Федеральный закон об ОСАГО, Положение о правилах ОСАГО не содержат в себе указаний о проценте неправильных сведений, содержащихся в полисе ОСАГО, чтобы признать его недействительным, отметил ведущий юрист Европейской юридической службы Орест Мацала. По его словам, чтобы досрочно прекратить действие договора ОСАГО либо вовсе признать его недействительным, необходимо установить, что недостоверные сведения были представлены намеренно и это повлекло за собой необоснованное снижение стоимости ОСАГО.
Фото: ТАСС/Ведомости/Евгений Разумный
«Любые недостоверные сведения, которые непосредственно повлияли на размер страховой премии, позволяют страховщику досрочно прекратить договор страхования либо в дальнейшем предъявить регрессные требования в соответствии со ст. 14 закона об ОСАГО. Неправильно указанный VIN при совокупности с иными обстоятельствами свидетельствует о недостижении согласия между сторонами о конкретном имуществе, при использовании которого страхуется ответственность владельца транспортного средства, аналогичную позицию высказал ВС РФ в постановлении пленума ВС РФ № 58», — добавила Анна Полина-Сташевская.
Пишите письма
Что делать, если при проверке полиса ОСАГО в базе обнаружились неверные сведения? Следует обратиться в страховую компанию и написать письменное заявление, чтобы изменения в договоре были сделаны. Если установлено, что имело место мошенничество, эксперты и страховщики рекомендуют обратиться и в правоохранительные органы.
Кроме того, у автовладельца есть шанс получить компенсацию через суд, считает Орест Мацала.
«Поскольку страхование ОСАГО — это услуга, при некачественно оказанной услуге, в том числе и при заключении договора, можно требовать компенсации всех убытков и возмещения морального вреда в соответствии со ст. 15 и 29 закона «О защите прав потребителей», — отметил ведущий юрист Европейской юридической службы.
Как восстановить КБМ в РСА
Нередки ситуации допущения ошибок в расчетах стоимости полиса ОСАГО, когда страховщик забывает или неверно определяет коэффициент водителя за безаварийную езду. Чтобы избежать завышенной оплаты, вы можете сами контролировать показатель скидки, периодически отправляя заявку на проверку КБМ по инструкции на сайте: https://roskbm.ru/kak-uznat-kbm.
Почему скидка на ОСАГО пропала
Нередки случаи, когда при проверке КБМ обнаруживается пропажа или значительное уменьшение скидки на страховой полис. Если вам вернули стандартный класс и КБМ=1, нужно разобраться в причинах и исправить ситуацию.
Как накопить КБМ на скидку
- Год безаварийной езды дает скидку 5% и повышает класс на один.
Если с момента последнего страхования автомобиля прошло менее 12 месяцев, скидка не положена. Аналогично происходит и в случаях вписывания третьих лиц (жены, друга) в страховку в середине срока действия полиса.
- Скидка на полис действует при непрерывном страховании автогражданской ответственности.
После прекращения действия страхового договора скидка остается только на год. Если перерыв в страховании дольше 12 месяцев, дисконт сгорает, нужно начинать копить КБМ с начала.
- Максимальный размер скидки 50 % достигается спустя 10 лет непрерывного вождения без аварий по вине водителя – это самый последний, 13 класс.
После достижения последнего класса последующие классы будут тоже под значением 13, пока вы не попадаете в аварию, и класс не снизится.
Ошибки в запросе на проверку КБМ
Часто ошибочный ответ на запрос выпадает при введении ошибочных данных владельца автомобиля. Если вы поменяли фамилию, в базе содержатся старые данные: обратите внимание на поле «Старая фамилия, если меняли» на странице заполнения формы для восстановления КБМ. Попробуйте ввести старые данные, и тогда увидите действующий КБМ и размер скидки на ОСАГО.
Аналогичная ситуация в случае с заменой водительских прав: введите номер прежнего водительского удостоверения (его можно узнать в разделе «Особые отметки» нового документа) и отправьте запрос.
Ошибка в КБМ по другим полисам
Иногда друзья и родственники вписывают друг друга в страховку на автомобиль, и если это ваш случай, стоит проверить значения КБМ в каждом из полисов, где значится ваша фамилия.
Ошибка могла произойти на стадии расчетов полиса другого человека, когда страховой агент случайно обнуляет скидки по всем полисам с одной фамилией, а владельцы машин не обращают внимания на ее отсутствие. В итоге вы попадаете в базу РСА с обнуленной скидкой, которую придется восстановить. При заполнении формы на проверку КБМ можно проверить, какой страховой полис утратил скидку.
Ошибки в КБМ в базе РСА онлайн
При возникновении проблем с расчетом скидки на ОСАГО страховщики любят ссылаться на ошибки в официальной базе РСА. Но часто это происходит именно по вине страхового агента, который вносит ваши данные в базу с ошибкой.
Дата рождения, фамилия, номер и серия водительского удостоверения – малейшая опечатка в этих сведениях приводит к нулевой скидке и начальному КБМ. Иногда в действиях страховщиков имеется прямой умысел: занесение данных с незаметной опечаткой – буква О вместо цифры 0 в дате рождения – не отображается в полисе ОСАГО и не может быть проверено вами на месте. Обнаружить ошибку можно при запросе справки о безубыточности, где указаны все данные из базы РСА.
Поддельный полис ОСАГО
Если вы страховали автомобиль на сайте непроверенного страховщика, есть риск приобрести липовую страховку. В таком случае естественно, что данные страхового полиса не отображаются в базе РСА – потому что их нет. Также сведения о страховании могут отсутствовать, если страховщик не передал их в базу. Сегодня случаи утраты договора практически исключены, потому что заключение оформляется на компьютере, а не вручную. Но если агент выписал бумажный вариант полиса и случайно утратил его по дороге в страховую, в базу РСА вы вряд ли попадете.
Намеренное сокрытие скидки ОСАГО
Страхование – доходный бизнес, и потому понятно желание страхового агента продать полис подороже. Нередки ситуации намеренного скрывания скидки от страхователя с целью получения крупной комиссии. Финансовая безграмотность клиентов страховой компании играет на руку нечистоплотным страховщикам. Вас могут обмануть сообщением об отсутствии связи с базой РСА или зависании компьютера. Поэтому следует заранее выяснить свой КБМ и положенную скидку, чтобы с этими сведениями идти страховать личный автомобиль.
Как вернуть скидку на ОСАГО
Коэффициент бонус-малус влияет на конечную сумму по оплате страхового полиса. Размер КБМ зависит от количества лет, в течение которых у водителя отсутствовали ДТП по его вине. Чем идеальнее водительская история, тем выше скидка на ОСАГО, которая может достигать 50% в зависимости от тарифа КБМ. Вы можете ознакомиться с таблицей КБМ 2020 года и узнать свой тариф по ссылке: https://roskbm.ru/kbm-tablica.
Введение коэффициента для расчета стоимости полиса стимулирует водителя на аккуратную, безаварийную езду. Если за 10 лет стажа вы не попали ни в одну аварию, полис ОСАГО будет стоить в два раза меньше обычной цены.
Но не всегда сведения о скидке содержатся в базе РСА, нередки случаи ошибок и упущений, из-за которых водитель лишается бонусов при заключении страхового договора. Это может случиться после замены водительского удостоверения, изменения фамилии, в случае перерыва в страховании больше года, но чаще всего – если страховщик просто не передал ваши данные в базу РСА онлайн.
КБМ после замены ВУ
Нередко после замены водительских прав КБМ возвращается к начальному 3 классу и значению 1, а скидка на ОСАГО обнуляется. Чтобы избежать проблем с получением скидки при продлении страхового полиса, необходимо наличие обновленных данных в базе РСА.
Обновление данных водительского удостоверения требует обращения в страховую компанию и внесения изменений в полис ОСАГО.
Страхователь обязан незамедлительно сообщить в письменной форме страховщику об изменении сведений, указанных в договоре страхования, произошедших в период действия полиса.
Если вы поменяли права или сменили фамилию, необходимо сразу сообщить об этом своему страховому агенту, чтобы он внес изменения в страховой договор и базу РСА. Это касается и случаев изменения личных данных других водителей, вписанных в вашу страховку и допущенных к управлению автомобилем. В случае несвоевременного внесения данных ваша скидка может обнулиться, и для продления полиса придется заново восстанавливать КБМ.
Честный и опытный страховой агент легко решит проблему, если обратит внимание на графу «Особые отметки» и предложит ввести номер предыдущего водительского удостоверения или старую фамилию. Он найдет скидку, сделает новый расчет КБМ и продаст полис ОСАГО по заниженной цене.
Как восстановить КБМ
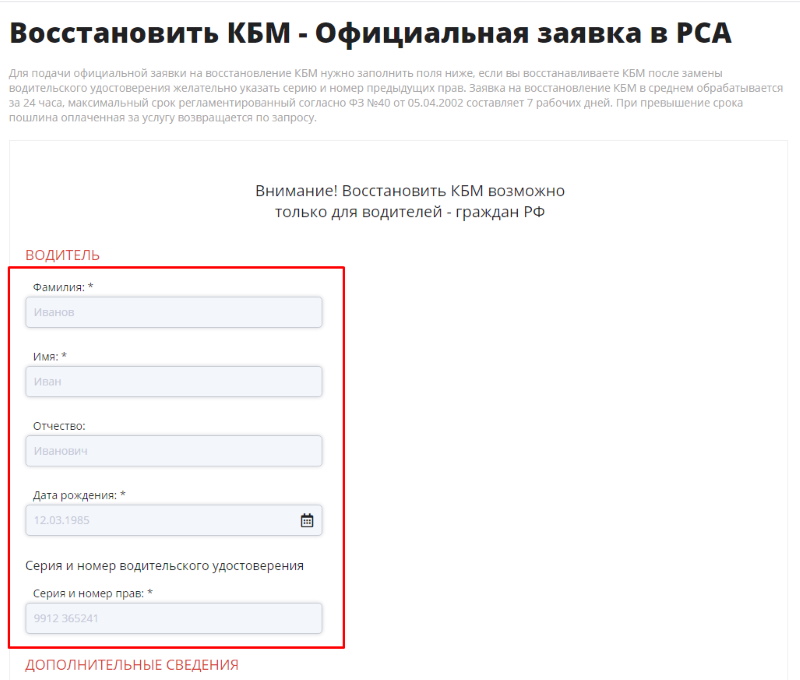
Если скидка на полис ОСАГО была утрачена, необходимо восстановить КБМ. Первый и самый простой способ восстановить коэффициент бонус-малус: отправить запрос в онлайн базу РСА через специальные сервисы, например, на сайте https://roskbm.ru/. Чтобы восстановить КБМ, зайдите на сайт и следуйте инструкции, по выполнению которой вы сможете вернуть коэффициент к исходному значению.
1. В горизонтальном меню главной страницы сайта выберите раздел «Восстановление КБМ за 24 часа» или перейдите по ссылке: https://roskbm.ru/vosstanovit-kbm.
2. Заполните поля заявки: введите ФИО, дату рождения, сведения из старого и текущего водительских удостоверений, в случае смены фамилии не забудьте указать старую фамилию в отдельной графе.
3. После заполнения данных нажмите кнопку «Далее»: через 30 секунд на экране отобразится ваш КБМ и сумма скидки, которую вы должны получить при оплате полиса ОСАГО. В случае загруженности базы РСА, заполните поле с адресом электронной почты – мы направим ответ на запрос туда.
4. Чтобы восстановить КБМ, введите электронную почту и оплатите услугу, после зачисления оплаты запрос на восстановление будет направлен в онлайн базу РСА.
В письме будет указан номер заявки, по всем вопросам оформления и восстановления КБМ можно обратиться в техподдержку по адресу: [email protected]. После успешной обработки запроса вы получите письмо с результатом восстановления коэффициента, который можно проверить в официальной базе РСА. Мы гарантируем восстановление КБМ, в противном случае вернем деньги за оплату услуги.
Как восстановить КБМ бесплатно
Кроме онлайн обращения в базу РСА, вы можете лично подать заявление на восстановление коэффициента в свою страховую компанию, либо своевременно сообщить об изменении данных водительского удостоверения или гражданского паспорта.
Нередки случаи внесения завышенной оплаты по полису ОСАГО, на которые водитель не обращает внимания. Неправильные расчеты страхового агента, ошибка в базе, спешка или халатное отношение к процедуре переоформления договора страхования становятся причинами неверного применения коэффициента бонус-малус и утраты скидки.
Вы должны выяснить, на каком этапе и когда были внесены ошибочные сведения, для этого достаточно заполнить данные в полях заявки на проверку КБМ и выбрать услугу «История изменения КБМ с 2013 года». Полученные сведения приложите к заявлению и направьте в страховую компанию с требованием произвести перерасчет КБМ и положенной скидки на основании обновленной информации. Не забудьте при наличии приложить дополнительные документы:
- предыдущий полис ОСАГО,
- копии старых и новых водительских прав,
- копию документов, подтверждающих изменение фамилии,
- справку из предыдущей страховой компании об отсутствии выплат по ущербу в ДТП.
Если спустя 10 дней страховщик не рассмотрел заявление, подавайте жалобу в РСА или ЦБ. Жалобу можно подать в простой письменной форме или в электронном виде через заполнение заявки на сайте. Не забудьте:
- Приложить выше названные документы, копию обращения в страховую и ответ на него (при наличии).
- Указать страховую компанию.
- Описать, с каким КБМ ранее оформлялись полисы ОСАГО.
- Обозначить число аварий в период страхования.
Жалоба в РСА или ЦБ рассматривается в течение 60 суток. После восстановления КБМ страховая компания пересчитает стоимость полиса и вернет излишне уплаченные суммы.
Как исправить неверный КБМ в базе РСА — Юридическая консультация
Ошибки при расчете коэффициента бонус-малус (КБМ) возникают чаще других.
Причины могут быть разными. Например, человек менял водительское удостоверение или покупал полисы ОСАГО в разных компаниях, и они рассчитывали КБМ только по своим данным.
Бывают случаи, когда водитель меняет права в период, когда у него нет полиса ОСАГО (допустим, несколько месяцев или даже лет он не пользовался машиной). Тогда ему нужно обязательно сообщить о замене удостоверения, когда он придет покупать новый полис.
Если этого не сделать, то страховщик не передаст информацию в Российский союз автостраховщиков (РСА). Новое удостоверение окажется не связанным с предыдущей страховой историей водителя. В базе РСА он будет значиться как новичок. И его КБМ станет равным единице.
Если это обнаружится в момент покупки нового полиса, надо попросить страховую компанию актуализировать информацию в базе РСА. И тогда, если у вас был низкий КБМ, вы сможете получить скидку на новую страховку.
Если водителю кажется, что КБМ в базе РСА указан неверно, нужно обратиться в страховую компанию, которая оформила ему последний полис ОСАГО, написать заявление в свободной форме с требованием проверить коэффициент бонус-малус, указав, в каких страховых компаниях ОСАГО приобреталось ранее.
Страховщик перенаправит запрос в Российский союз автостраховщиков. РСА в течение пяти рабочих дней проведет проверку. Если выяснится, что какие-то компании ранее подали о водителе неверные или противоречивые сведения, РСА будет трактовать любые ошибки в его пользу. И если в базе окажется несколько КБМ по данным от разных страховщиков, в базу РСА будет внесен минимальный.
Затем РСА сообщит об итогах проверки страховой компании, а она должна передать эту информацию водителю. Если выяснится, что какой-то из коэффициентов был неверным, компания пересчитает цену полиса.
Если вы не получите ответ от страховщика в течение 10 дней после запроса, можно обратиться напрямую в РСА или в интернет-приемную Банка России на сайте регулятора.
Даже если водитель заметил ошибку страховой компании уже после покупки полиса, можно потребовать пересчитать его стоимость и вернуть разницу. Более того: это можно сделать, даже если КБМ исправили уже после того, как была куплена страховка.
Если же страховая компания несколько лет подряд рассчитывала завышенную цену полиса из-за неверного КБМ, можете потребовать у нее вернуть деньги, которые водитель переплатил за последние три года.
Нужно прийти в страховую компанию, в которой был куплен полис, и написать заявление в свободной форме. В нем потребовать пересчитать стоимость полиса на основании правильных коэффициентов. В заявлении укажите реквизиты счета, на который нужно перевести возвращенные деньги.
Страховщик обязан внести изменения в полис или выдать водителю новый в течение двух рабочих дней после обращения.
Деньги должны перечислить на счет в течение 14 календарных дней после обращения. Если деньги не вернули и полис не исправили, можно обратиться с жалобой в интернет-приемную Банка России.
ОСАГО от Сбербанка
Для всех страховых механизм внесения изменений разный. Самый действенный способ — дойти до офиса СК и внести все изменения. Если это невозможно, ниже представлен список доступных изменений в личном кабинете каждой СК.Авторизация в личный кабинет клиента возможно только по данным, указанным во время оформления полиса!
АО «Тинькофф». Возможно внести любые изменения. Для этого страхователю необходимо позвонить на горячую линию страховой компании с номера, на который оформлен полис: 8(800)755-80-00.
Веб-сайт страховой компании: https://www.tinkoffinsurance.ru/
СПАО «Ингосстрах». Внести изменения можно на сайте страховой компании. Список доступных изменений: добавление водителя, изменить данные водителя, поменять гос. номер ТС, изменить данные ПТС/СТС.
Веб-сайт страховой компании: https://www.ingos.ru/
АО «Альфастрахование». На сайте alfastrah.ru представлен список доступных изменений: серия, номер ВУ, добавление водителя, гос. номер ТС, ТС используется с прицепом, удаление водителя.
Веб-сайт страховой компании: https://www.alfastrah.ru/
ООО «Ренессанс». Внести изменения возможно на сайте страховой компании. Для просмотра полного списка возможных изменений необходимо авторизоваться в личном кабинете страховой компании.
Веб-сайт страховой компании: https://www.renins.ru/
ООО «СК «Согласие». Внести изменения можно на сайте страховой компании. Список доступных изменений: внесение нового водительского удостоверения, изменение данных водителей, дополнение данных собственника, изменение гос. номера ТС.
Веб-сайт страховой компании: https://lk.soglasie.ru/
САО «ВСК» тел. 8(800)775-15-75, СК «Росгосстрах» тел. 8(800)200-0-900. Внесение изменений возможно только в офисе СК. Подробную информацию необходимо уточнить на сайте страховой компании.
Веб-сайты страховых компаний: https://www.vsk.ru/ и https://www.rgs.ru/
«Mafin» (ООО «Абсолют Страхование») . Есть несколько способов внести изменения. Страхователю необходимо позвонить в контакт-центр: 8-800-555-1-555 или написать на почту: [email protected] . Можно скачать мобильное приложении и внести изменения.
АО «МАКС». Внести изменения можно в офисе страховой компании, в личном кабинете на сайте компании, либо написать на почту: [email protected]
Веб-сайт страховой компании: https://www.makc.ru/
ООО «Зетта Страхование». Внести изменения можно в личном кабинете на сайте, а также в офисе компании. Телефон круглосуточного контакт-центра
8 800 700 77 07 (звонок по РФ бесплатный).
Веб-сайт страховой компании:https://www.zettains.ru/
АО «СОГАЗ». Внести изменения можно в личном кабинете на сайте страховой компании, в мобильном приложении или в офисе компании. Телефон круглосуточного контакт-центра: 8 800 333 0 888. Веб-сайт страховой компании: https://www.sogaz.ru/
АО ГСК «Югория». Внести изменения можно в личном кабинете на сайте страховой компании или в офисе компании. Телефон контакт-центра: 8 800 100-82-00. Веб-сайт страховой компании: https://ugsk.ru/
Нет в базе рса что делать
Что делать, если нет данных в базе РСА либо указаны неправильные?
Содержание страницы
С 2013 года Союзом автостраховщиков РФ (РСА) введена в работу база данных, используемая при проверке коэффициента «бонус-малус» (КБМ). Указанный параметр в обязательном порядке должен использоваться страховыми компаниями при расчете тарифа по страхованию (ОСАГО).
Учитывая собственную страховую историю, водители могут рассчитывать на понижение тарифа за счет бонусов (5% за каждый год) за безаварийное вождение в предыдущий страхованию год. Если в ходе последних двух лет имело место ДТП по вине клиента, то размер тарифа увеличивается (малус).
В чем преимущества метода?
Для клиента выгода от единой базы данных состоит в том, что стоимость полиса должна ему объявляться сотрудником СК только после выполнения запроса в базу РСА и выявления права на получение скидки по стоимости. Ранее расчет часто производился по базовому тарифу без учета имеющегося бонуса.
Для страховой компании положительным моментом является возможность получения реальной картины по водительской истории клиента. Ранее водитель, узнав о повышении тарифа из-за ДТП, переходил на обслуживание в другую СК, которая была не в курсе о происшествии, и страховался по обычной стоимости. Теперь в любой организации будет видна его история, поэтому тариф будет везде одинаковый, то есть повышенный из-за нарушений ПДД и ДТП.
Почему нет сведений в базе?
Персональные данные в единой страховой базе могут отсутствовать по нескольким причинам:
- когда страховая компания по разным причинам не передала информацию об истории вождения клиента;
- когда переданы не правильные данные в РСА, а с ошибками, поэтому они не привязаны в базе к конкретному водителю;
- когда произошел технический сбой в работе программы и какие-то участки с данными оказались поврежденными;
- когда клиент произвел обмен водительского удостоверения, но информация в базе осталась привязанной к устаревшим данным;
- когда клиент только получил права и оформляет самый первый страховой договор.
Что делать при отсутствии информации в базе РСА?
Чтобы убедиться в том, что действительно нет данных в РСА о КБМ, следует направить письменный запрос в Союз автостраховщиков. Если не найдут подтверждения факты передачи сведений страховщиками за предыдущие периоды, водитель должен предпринять следующие действия:
- Подготовить старые страховые полисы ОСАГО. При их отсутствии обратиться в СК, где ранее оформлялись договора, и выяснить номера документов, период их действия и дату выдачи.
- По месту оформления предыдущего полиса получить справку для перехода в другую СК с указанием данных о страховом стаже клиента и страховых случаях (если таковые были).
- Полученную справку отнести в СК, где планируется оформление нового страхового соглашения.
Если договор уже оформлен, то на основании предоставленной справки стоимость полиса должна быть пересчитана, и возвращена часть оплаченной премии при наличии права на скидки (по КБМ).
Почему в единой базе РСА нет данных водительского удостоверения?
Задайте
вопрос
Уже несколько дней пытаюсь купить электронное ОСАГО. Перепробовал сайты десятка страховых компаний, но везде одна и та же ошибка. Программа не находит в единой базе моё водительское удостоверение. Звонил в РСА. Там посоветовали оформить письменное обращение. Вот только ждать ответа нет времени, новый полис нужен на этой неделе. В чём может быть причина того, что мои права не внесены в базу данных, и как мне теперь оформлять электронный полис?
- З
Отвечает Загородский Александрэксперт
Такая ошибка возникает, если при заполнении заявления на страхование в компьютере менеджер переключал раскладку клавиатуры на латинскую. Например, в фамилии Иванов буква «а» из кириллицы была заменена на аналогичную из латиницы. Попробуйте заполнить данные по водительскому удостоверению с учётом этого соображения.
ОСАГО, — водителя нет в базе данных
Мне пришел ответ из страховой.Добрый день.
Благодарим Вас за обращение в ОАО СК «Альянс».
Настоящим письмом сообщаем, что данные по полису ССС-0679639294, период действия 22.04.2014 — 21.04.2015 гг., скорректированы.
Информируем Вас, что сведения в АИС РСА принимаются к расчету по факту завершения действия договора.
На дату, следующую за датой завершения действия полиса ССС-0679639294, 22.04.2015 г., КБМ водителя *****************. И. будет равен 0,65, класс=10.
Лист расчёта на дату 22.04.2015 г. во вложении, код расчёта: 1853689954.
Полис ССС-0679639294 является действующим и на текущую дату не может участвовать в расчёте. Дополнительно был сделан запрос в АИС РСА с целью определения КБМ на сегодняшний день, расчёт был произведён по полису ССС-0679653455, согласно которому расчётным является класс 9, КБМ=0,7 (при пролонгации класс повысится до 10).
Лист расчёта на текущую дату во вложении, код расчёта: 1853690780.
Приносим извинения за доставленные неудобства.
Что делать, если данных о диагностической карте нет в базе данных РСА?
Задайте
вопрос
Купил диагностическую карту. Машину по факту практически не осматривали. Есть такая? И хорошо! Когда пришло время оформлять полис ОСАГО, выяснилось, что моей диагностической карты нет в базе данных Российского Союза Автостраховщиков. Что мне теперь делать-то?
- З
Отвечает Загородский Александрэксперт
Возможны два варианта. Вы могли стать жертвой мошенников. Проверьте название организации, проводившей технический осмотр транспортного средства, на официальном сайте Российского Союза Автостраховщиков в соответствующем реестре. Если ее там не окажется, то незамедлительно обращайтесь в полицию с заявлением о факте мошенничества. При этом Вам придется заново пройти технический осмотр транспорта и получить диагностическую карту, если требуется оформить полис ОСАГО.
Если же организация, проводившая технический осмотр транспорта, числится в списке компаний, аккредитованных РСА. То Вам необходимо обратиться в данную организацию с требованием внести сведения о Вашей диагностической карте в базу РСА. При отсутствии реакции со стороны оператора технического осмотра следует обращаться с жалобой в Российский Союз Автостраховщиков. Как правило, подобные проблемы разрешаются достаточно оперативно.
«Отсутствие данных в базе РСА. КБМ !!!»
татьяна (гость)
Отсутствие данных в базе РСА. КБМ !!!
Решила я продлить полис ОСАГО Росгосстрах и надо же… оказалось что данные о моей истории страхования отсутствуют в базе РСА. По текущему полису класс 8, а мне теперь предлагают страховать по 3 классу. КЛАСС!!! Все что предложила девушка по телефону страховой-это написать жалобу на сайте Росгосстраха. Жалобу написала, но никаких регистрационных данных о жалобе от сайта не получено.Потом доказывай что ты писал, когда писал, кому писал… Срок рассмотрения жалобы 30 дней (по инфо по тел.), а полис то заканчивается через две недели… «И теперь это уже ваши проблемы»-так мне ответили по телефону.И да, девушка по телефону отвечая на вопрос о том, почему такое случилось, просто тупо прочитала мне уже заранее заготовленный текст. Проверяла, звонила 2 раза, текст один и тот же))) Так что храните свои все предыдущие страховые полисы, ибо в нашей стране без бумажки-ты… ну сами знаете кто… Видимо это касается всех страховых компаний. т.к отзывов подобных достаточно и по другим конторкам, но тут просто убило отношение…
Ах, да еще интересно отсутствие логики в подобных ситуациях.То что полис текущий с 8 классом-это оказывается не является никаким основание для продления полиса со скидкой.Основанием является только база РСА, в которой данных почему-то нет…
ВСЕ!
Полис ОСАГО виновника ДТП отсутствует в базе РСА
Ярослав, добрый день.
Сведения о выписанном полисе ОСАГО
должны быть занесены в АИС РСА не позднее одного рабочего дня с момента оформления полиса.
7. При заключении договора обязательного страхования страховщик вручает страхователю страховой полис, являющийся документом, удостоверяющим осуществление обязательного страхования, или выдает лицу, обратившемуся к нему за заключением договора обязательного страхования, мотивированный отказ в письменной форме о невозможности заключения такого договора, о чем также информирует Банк России и профессиональное объединение страховщиков. Страховщик не позднее одного рабочего дня со дня заключения договора обязательного страхования вносит сведения, указанные в заявлении о заключении договора обязательного страхования и (или) представленные при заключении этого договора, в автоматизированную информационную систему обязательного страхования, созданную в соответствии со статьей 30 настоящего Федерального закона. Бланк страхового полиса обязательного страхования является документом строгой отчетности.
То обстоятельство, что полис не внесен в АИС РСА, не умаляет его действительность и не может служить основанием для отказа в выплате страхового возмещения.
Здесь стоит учесть, что исходя из требований ст. 15 ФЗ «Об ОСАГО»
7.1. Страховщик обеспечивает контроль за использованием бланков страховых полисов обязательного страхования страховыми брокерами и страховыми агентами и несет ответственность за их несанкционированное использование. Для целей настоящего Федерального закона под несанкционированным использованием бланков страховых полисов обязательного страхования понимается возмездная или безвозмездная передача чистого или заполненного бланка страхового полиса владельцу транспортного средства без отражения в установленном порядке факта заключения договора обязательного страхования, а также искажение представляемых страховщику сведений об условиях договора обязательного страхования, отраженных в бланке страхового полиса, переданного страхователю.
В случае причинения вреда жизни, здоровью или имуществу потерпевшего владельцем транспортного средства, обязательное страхование гражданской ответственности которого удостоверено страховым полисом обязательного страхования, бланк которого несанкционированно использован, страховщик, которому принадлежал данный бланк страхового полиса, обязан выплатить за счет собственных средств компенсацию в счет возмещения причиненного потерпевшему вреда в размере, определенном в соответствии со статьей 12 настоящего Федерального закона,за исключением случаев хищения бланков страховых полисов обязательного страхования при условии, что до даты наступления страхового случая страховщик, страховой брокер или страховой агент обратился в уполномоченные органы с заявлением о хищении бланков. Выплата указанной компенсации осуществляется в порядке, установленном настоящим Федеральным законом для осуществления страховой выплаты. Принадлежность бланка страхового полиса обязательного страхования страховщику подтверждается профессиональным объединением страховщиков в соответствии с правилами профессиональной деятельности, предусмотренными подпунктом «п» пункта 1 статьи 26 настоящего Федерального закона.
Неполное и (или) несвоевременное перечисление страховщику страховой премии, полученной страховым брокером или страховым агентом, не освобождает страховщика от необходимости исполнения обязательств по договору обязательного страхования, в том числе в случаях несанкционированного использования бланков страхового полиса обязательного страхования.
В пределах суммы компенсации, выплаченной страховщиком потерпевшему в соответствии с настоящим пунктом, а также понесенных расходов на рассмотрение требования потерпевшего страховщик имеет право требования к лицу, ответственному за несанкционированное использование бланка страхового полиса обязательного страхования, принадлежавшего страховщику.
Поэтому, чтобы Вам представитель СК — не уверял, но на производство выплаты отведены законом 20 дней и в течение этих сроков она должна быть осуществлена. Если срок нарушен, то Вы вправе осуществлять защиту своих интересов в судебном порядке, дополнительно требуя взыскания со страховой компании финансовых санкций.
PCA с использованием Python (scikit-learn). Мой последний урок касался логистики… | автор: Майкл Галарник.
Исходное изображение (слева) с сохраненной разной величиной дисперсииВ моем последнем руководстве я рассмотрел логистическую регрессию с использованием Python. Одна из полученных вещей заключалась в том, что вы можете ускорить настройку алгоритма машинного обучения, изменив алгоритм оптимизации. Более распространенный способ ускорить алгоритм машинного обучения — использовать анализ главных компонентов (PCA). Если ваш алгоритм обучения слишком медленный из-за слишком высокого размера входных данных, то использование PCA для его ускорения может быть разумным выбором.Вероятно, это наиболее распространенное применение PCA. Еще одно распространенное применение PCA — визуализация данных.
Чтобы понять ценность использования PCA для визуализации данных, в первой части этого учебного поста рассматривается базовая визуализация набора данных IRIS после применения PCA. Вторая часть использует PCA для ускорения алгоритма машинного обучения (логистической регрессии) для набора данных MNIST.
Итак, приступим! Если вы заблудились, рекомендую открыть видео ниже в отдельной вкладке.
PCA с использованием Python VideoКод, используемый в этом руководстве, доступен ниже
PCA для визуализации данных
PCA для ускорения алгоритмов машинного обучения
Для многих приложений машинного обучения это помогает визуализировать данные. Визуализировать двух- или трехмерные данные не так сложно. Однако даже набор данных Iris, используемый в этой части руководства, является четырехмерным. Вы можете использовать PCA, чтобы уменьшить эти четырехмерные данные до двух или трех измерений, чтобы вы могли построить график и, надеюсь, лучше понять данные.
Загрузить набор данных Iris
Набор данных Iris — это один из наборов данных, которые поставляются с scikit-learn, которые не требуют загрузки какого-либо файла с какого-либо внешнего веб-сайта. Приведенный ниже код загрузит набор данных радужной оболочки.
импортировать панды как pdurl = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"# загрузить набор данных в Pandas DataFrameИсходные Pandas df (функции + цель)
df = pd.read_csv (url, names = ['длина чашелистника', 'ширина чашелистника', 'длина лепестка', 'ширина лепестка', 'цель'])
Стандартизация данных
PCA выполняется по масштабу, поэтому вам нужно для масштабирования функций в ваших данных перед применением PCA.Используйте StandardScaler , чтобы помочь вам стандартизировать функции набора данных в единичном масштабе (среднее значение = 0 и дисперсия = 1), что является требованием для оптимальной производительности многих алгоритмов машинного обучения. Если вы хотите увидеть негативный эффект, который может иметь отсутствие масштабирования ваших данных, в scikit-learn есть раздел о последствиях нестандартизации ваших данных.
из sklearn.preprocessing import StandardScalerfeatures = ['длина чашелистника', 'ширина чашелистика', 'длина лепестка', 'ширина лепестка'] # Разделение элементовМассив x (визуализируется фреймом данных pandas) до и после стандартизации
x = df.loc [:, features] .values # Разделение цели
y = df.loc [:, ['target']]. values # Стандартизация функций
x = StandardScaler (). fit_transform (x)
Проекция PCA в 2D
Исходные данные имеют 4 столбца (длина чашелистика, ширина чашелистика, длина лепестка и ширина лепестка). В этом разделе код проецирует исходные данные, которые являются четырехмерными, в двухмерные. Я должен отметить, что после уменьшения размерности каждому главному компоненту обычно не присваивается конкретное значение.Новые компоненты — это всего лишь два основных аспекта вариации.
из sklearn.decomposition import PCApca = PCA (n_components = 2) PrincipalComponents = pca.fit_transform (x) PrincipalDf = pd.DataFrame (data = PrincipalComponentsPCA и сохранение двух верхних основных компонентов
, columns = ['основной компонент 1', 'основной компонент 2'])
finalDf = pd.concat ([PrincipalDf, df [['target']]], axis = 1)
Объединение DataFrame по оси = 1. finalDf — это последний DataFrame перед построением графика данные.
Объединение фреймов данных по столбцам для создания finalDf перед построением графикаВизуализация 2D-проекции
В этом разделе просто отображаются двухмерные данные. Обратите внимание на графике ниже, что классы кажутся хорошо отделенными друг от друга.
fig = plt.figure (figsize = (8,8))2 График PCA компонентов
ax = fig.add_subplot (1,1,1)
ax.set_xlabel ('Главный компонент 1', fontsize = 15)
ax.set_ylabel (' Основной компонент 2 ', fontsize = 15)
ax.set_title (' 2-компонентный PCA ', fontsize = 20) target = [' Iris-setosa ',' Iris-versicolor ',' Iris-virginica ']
colors = [' r ',' g ',' b ']
для цели, цвет в zip (цели, цвета):
indexToKeep = finalDf [' target '] == target
ax.scatter (finalDf.loc [indexToKeep, 'главный компонент 1']
, finalDf.loc [indexToKeep, 'главный компонент 2']
, c = color
, s = 50)
ax.legend (цели)
ax.grid ()
Объясненное отклонение
Объясненное отклонение показывает, сколько информации (отклонения) можно отнести к каждому из основных компонентов. Это важно, поскольку, хотя вы можете преобразовать 4-мерное пространство в 2-мерное пространство, при этом вы теряете часть дисперсии (информации).Используя атрибут объясненная_вариантность_ , вы можете увидеть, что первый главный компонент содержит 72,77% дисперсии, а второй главный компонент содержит 23,03% дисперсии. Вместе эти два компонента содержат 95,80% информации.
pca.explained_variance_ratio_
Одно из наиболее важных приложений PCA — ускорение алгоритмов машинного обучения. Использование набора данных IRIS здесь было бы непрактичным, поскольку набор данных содержит только 150 строк и только 4 столбца функций.База данных рукописных цифр MNIST более подходит, поскольку она имеет 784 столбца характеристик (784 измерения), обучающий набор из 60 000 примеров и тестовый набор из 10 000 примеров.
Загрузка и загрузка данныхВы также можете добавить параметр data_home в fetch_mldata , чтобы изменить место загрузки данных.
из sklearn.datasets import fetch_openmlmnist = fetch_openml ('mnist_784') Изображения, которые вы загрузили, содержатся в mnist.data и имеет форму (70000, 784), что означает 70 000 изображений с 784 размерами (784 объекта).
Метки (целые числа 0–9) содержатся в mnist.target . Элементы имеют 784 размера (изображения 28 x 28), а надписи представляют собой простые числа от 0 до 9.
Разделение данных на наборы для обучения и тестированияКак правило, разделение обучающего теста составляет 80% обучения и 20% теста. В этом случае я выбрал 6/7 данных для обучения и 1/7 данных для тестового набора.
из sklearn.model_selection import train_test_split # test_size: какая часть исходных данных используется для тестового набораСтандартизация данных
train_img, test_img, train_lbl, test_lbl = train_test_split (mnist.data, mnist.target, test_size = 1 / 7.0, random_state = 0)
Текст в этом абзаце является почти точной копией того, что было написано ранее. PCA зависит от масштаба, поэтому вам необходимо масштабировать функции в данных перед применением PCA. Вы можете преобразовать данные в единицу измерения (среднее значение = 0 и дисперсия = 1), что является требованием для оптимальной производительности многих алгоритмов машинного обучения. StandardScaler помогает стандартизировать функции набора данных. Обратите внимание, что вы подходите для обучающего набора и трансформируете обучающий и тестовый набор. Если вы хотите увидеть негативный эффект, который может иметь отсутствие масштабирования ваших данных, в scikit-learn есть раздел о последствиях нестандартизации ваших данных.
из sklearn.preprocessing import StandardScalerИмпорт и применение PCA
scaler = StandardScaler () # Подходит только для обучающего набора.
scaler.fit (train_img) # Применить преобразование как к набору обучения, так и к набору тестов.
train_img = scaler.transform (train_img)
test_img = scaler.transform (test_img)
Обратите внимание, что в коде ниже 0,95 для параметра количества компонентов. Это означает, что scikit-learn выбирает минимальное количество основных компонентов, чтобы сохранить 95% дисперсии.
из sklearn.decomposition import PCA # Создайте экземпляр модели
pca = PCA (.95)
Установите PCA в обучающий набор. Примечание: вы устанавливаете PCA только на тренировочном наборе.
pca.fit (train_img)
Примечание. Вы можете узнать, сколько компонентов PCA выберет после подбора модели, используя pca.n_components_ . В этом случае 95% дисперсии составляют 330 основных компонентов.
Примените отображение (преобразование) как к обучающему набору, так и к набору тестов.train_img = pca.transform (train_img)Применить логистическую регрессию к преобразованным данным
test_img = pca.transform (test_img)
Шаг 1: Импортируйте модель, которую хотите использовать
В sklearn, все модели машинного обучения реализованы как классы Python
из sklearn.linear_model import LogisticRegression
Шаг 2: Создайте экземпляр модели.
# для всех неуказанных параметров установлены значения по умолчанию
# решатель по умолчанию невероятно медленный, поэтому он был изменен на 'lbfgs'
logisticRegr = LogisticRegression (solver = 'lbfgs')
Шаг 3: Обучение модели на данных, хранящих информацию, полученную из данных
Модель изучает взаимосвязь между цифрами и метками
logisticRegr.fit (train_img, train_lbl)
Шаг 4: Предсказание меток новых данных (новых изображений)
Использует информацию, полученную моделью в процессе обучения модели
Код ниже предсказывает для одного наблюдения
# Predict для одного наблюдения (изображение)
logisticRegr.predict (test_img [0] .reshape (1, -1))
Приведенный ниже код прогнозирует сразу несколько наблюдений
# Прогноз для одного наблюдения (изображение)
logisticRegr .прогноз (test_img [0:10])
Измерение производительности модели
Хотя точность не всегда является лучшим показателем для алгоритмов машинного обучения (точность, отзыв, оценка F1, кривая ROC и т. здесь для простоты.
logisticRegr.score (test_img, test_lbl)
Сроки подгонки логистической регрессии после PCA
Весь смысл этого раздела руководства состоял в том, чтобы показать, что вы можете использовать PCA для ускорения подбора алгоритмов машинного обучения.В приведенной ниже таблице показано, сколько времени потребовалось для соответствия логистической регрессии на моем MacBook после использования PCA (каждый раз сохраняя разную величину дисперсии).
Время, необходимое для подгонки логистической регрессии после PCA с различными долями сохраняемой дисперсииВ более ранних частях руководства было продемонстрировано использование PCA для сжатия данных большой размерности в данные меньшей размерности. Я хотел вкратце упомянуть, что PCA может также возвращать сжатое представление данных (данные более низкой размерности) к приближению исходных данных большой размерности.Если вас интересует код, который создает изображение ниже, посмотрите мой github.
Исходное изображение (слева) и приближения (справа) исходных данных после PCAЗаключительные мысли
Это сообщение, над которым я мог бы писать намного дольше, поскольку PCA имеет много разных применений. Надеюсь, этот пост поможет вам во всем, над чем вы работаете. В моем следующем руководстве по машинному обучению я расскажу о деревьях принятия решений для классификации (Python). Если у вас есть какие-либо вопросы или мысли по поводу учебника, не стесняйтесь обращаться в комментариях ниже или через Twitter.Если вы хотите узнать о других алгоритмах, рассмотрите возможность прохождения моего курса «Машинное обучение с помощью Scikit-Learn LinkedIn Learning».
.Визуализация многомерных наборов данных с использованием PCA и t-SNE в Python | Автор: Луук Дерксен
Обновление: 29 апреля 2019 г. Некоторые части кода обновлены, чтобы не использовать ggplot , а вместо этого использовать seaborn и matplotlib . Я также добавил пример для 3D-графика. Я также изменил синтаксис для работы с Python3.
Первый шаг к решению любой проблемы, связанной с данными, — это начать с изучения самих данных.Это можно сделать, например, путем изучения распределений определенных переменных или выявления потенциальных корреляций между переменными.
В настоящее время проблема заключается в том, что большинство наборов данных содержат большое количество переменных. Другими словами, они имеют большое количество измерений, по которым распределяются данные. Визуальное изучение данных может стать затруднительным и в большинстве случаев практически невозможно выполнить вручную. Однако такое визуальное исследование невероятно важно в любой проблеме, связанной с данными.Поэтому важно понимать, как визуализировать многомерные наборы данных. Это может быть достигнуто с помощью методов, известных как уменьшение размерности. Этот пост будет посвящен двум методам, которые позволят нам это сделать: PCA и t-SNE.
Об этом позже. Давайте сначала получим некоторые (многомерные) данные для работы.
В этой статье мы будем использовать набор данных MNIST. Нет необходимости загружать набор данных вручную, так как мы можем получить его с помощью Scikit Learn.
Сначала давайте разместим все библиотеки.
из __future__ import print_function
import timeimport numpy as np
import pandas as pdfrom sklearn.datasets import fetch_mldata
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE% matplotlib inline
import matplotlib as plt_py. mplot3d импортирует Axes3Dimport seaborn как sns
и давайте затем начнем с загрузки данных
mnist = fetch_mldata ("MNIST original")
X = mnist.data / 255.0
y = mnist.targetprint (X.shape, y.shape) [out] (70000, 784) (70000,) Мы собираемся преобразовать матрицу и вектор в DataFrame Pandas. Это очень похоже на DataFrames, используемые в R, и облегчит нам построение графика позже.
feat_cols = ['pixel' + str (i) for i in range (X.shape [1])] df = pd.DataFrame (X, columns = feat_cols)
df ['y'] = y
df [ 'label'] = df ['y']. apply (lambda i: str (i)) X, y = None, Noneprint ('Размер фрейма данных: {}'. format (df.shape)) [out] Размер фрейма данных: (70000, 785)
Поскольку мы не хотим использовать 70 000 цифр в некоторых вычислениях, мы возьмем случайное подмножество цифр.Рандомизация важна, поскольку набор данных сортируется по его метке (то есть первые семь тысяч или около того — нули и т. Д.). Чтобы гарантировать рандомизацию, мы создадим случайную перестановку числа от 0 до 69 999, которая позволит нам позже выбрать первые пять или десять тысяч для наших расчетов и визуализаций.
# Для воспроизводимости результатов
np.random.seed (42) rndperm = np.random.permutation (df.shape [0])
Теперь у нас есть фрейм данных и вектор рандомизации.Давайте сначала проверим, как на самом деле выглядят эти числа. Для этого мы сгенерируем 30 графиков случайно выбранных изображений.
plt.gray ()
fig = plt.figure (figsize = (16,7))
для i в диапазоне (0,15):
ax = fig.add_subplot (3,5, i + 1, title = "Цифра: {}". Формат (str (df.loc [rndperm [i], 'label'])))
ax.matshow (df.loc [rndperm [i], feat_cols] .values.reshape ((28 , 28)). Astype (float))
plt.show ()
Теперь мы можем начать думать о том, как на самом деле отличить нули от единиц, двоек и так далее.Если бы вы были, например, почтовым отделением, такой алгоритм мог бы помочь вам читать и сортировать рукописные конверты с помощью машины, а не людей. Очевидно, что в настоящее время у нас есть очень продвинутые методы для этого, но этот набор данных по-прежнему является очень хорошей площадкой для тестирования, чтобы увидеть, как работают конкретные методы уменьшения размерности и насколько хорошо они работают.
Все изображения по существу представляют собой изображения размером 28 на 28 пикселей и, следовательно, имеют в общей сложности 784 «размера», каждое из которых содержит значение одного конкретного пикселя.
Что мы можем сделать, так это резко сократить количество измерений, пытаясь сохранить как можно больше «вариаций» в информации. Здесь мы подходим к уменьшению размерности. Давайте сначала взглянем на нечто, известное как анализ основных компонентов .
PCA — это метод уменьшения количества измерений в наборе данных при сохранении большей части информации. Он использует корреляцию между некоторыми измерениями и пытается предоставить минимальное количество переменных, которые сохраняют максимальное количество вариаций или информацию о том, как распределяются исходные данные.Он делает это не с помощью догадок, а с использованием точной математики и того, что известно как собственные значения и собственные векторы матрицы данных. Эти собственные векторы ковариационной матрицы обладают тем свойством, что они указывают на основные направления изменения данных. Это направления максимальных вариаций в наборе данных.
Я не собираюсь вдаваться в фактический вывод и вычисление основных компонентов — если вы хотите углубиться в математику, посмотрите эту замечательную страницу — вместо этого мы воспользуемся реализацией Scikit-Learn PCA.
Поскольку мы, люди, любим наши двух- и трехмерные графики, давайте начнем с них и сгенерируем из исходных 784 измерений первые три основных компонента. И мы также увидим, сколько вариаций в общем наборе данных они действительно учитывают.
pca = PCA (n_components = 3)
pca_result = pca.fit_transform (df [feat_cols] .values) df ['pca-one'] = pca_result [:, 0]
df ['pca-two'] = pca_result [:, 1]
df ['pca-three'] = pca_result [:, 2] print ('Объясненная вариация для основного компонента: {}'.формат (pca.explained_variance_ratio _)) Объясненная вариация по главному компоненту: [0,09746116 0,07155445 0,06149531]
Теперь, учитывая, что первые два компонента составляют около 25% вариации во всем наборе данных, давайте посмотрим, достаточно ли этого, чтобы визуально установить разные цифры. Что мы можем сделать, так это создать диаграмму рассеяния первого и второго главных компонентов и раскрасить каждый из различных типов цифр разным цветом. Если нам повезет, будут расположены цифры того же типа (т.е., сгруппированы) вместе в группы, что означало бы, что первые два основных компонента на самом деле многое говорят нам о конкретных типах цифр.
plt.figure (figsize = (16,10))
sns.scatterplot (
x = "pca-one", y = "pca-two",
hue = "y",
palette = sns.color_palette ( "hls", 10),
data = df.loc [rndperm ,:],
legend = "full",
alpha = 0.3
)
Из графика мы видим, что два компонента определенно содержат некоторую информацию, особенно для конкретных цифр, но явно недостаточно, чтобы их все можно было разделить.К счастью, есть еще один метод, который мы можем использовать для уменьшения количества измерений, который может оказаться более полезным. В следующих нескольких абзацах мы рассмотрим эту технику и выясним, дает ли она нам лучший способ уменьшения размеров для визуализации. Метод, который мы будем исследовать, известен как t-SNE (t-распределенные стохастические соседние объекты).
Для 3d-версии того же сюжета
ax = plt.figure (figsize = (16,10)). Gca (projection = '3d')
ax.scatter (
xs = df.loc [rndperm,:] ["pca-one"],
ys = df.loc [rndperm,:] ["pca-two"],
zs = df.loc [rndperm,:] ["pca-three" ],
c = df.loc [rndperm,:] ["y"],
cmap = 'tab10'
)
ax.set_xlabel ('pca-one')
ax.set_ylabel ('pca-two')
ax.set_zlabel ('pca-three')
plt.show ()
Распределенное стохастическое соседнее встраивание (t-SNE) — это еще один метод уменьшения размерности, который особенно хорошо подходит для визуализации многомерных наборов данных. В отличие от PCA, это не математический метод, а вероятностный.Исходная статья описывает работу t-SNE как:
«t-Распределенное стохастическое вложение соседей (t-SNE) минимизирует расхождение между двумя распределениями: распределение, которое измеряет попарное сходство входных объектов, и распределение, которое измеряет попарно. подобия соответствующих точек малой размерности вложения ».
По сути, это означает, что он смотрит на исходные данные, которые вводятся в алгоритм, и смотрит, как лучше всего представить эти данные с использованием меньших измерений путем сопоставления обоих распределений.Способ, которым он это делает, довольно сложен в вычислительном отношении, и поэтому существуют некоторые (серьезные) ограничения на использование этого метода. Например, одна из рекомендаций заключается в том, что в случае данных очень высокой размерности вам может потребоваться применить другой метод уменьшения размерности перед использованием t-SNE:
| Настоятельно рекомендуется использовать другое уменьшение размерности.
| метод (например, PCA для плотных данных или TruncatedSVD для разреженных данных)
| уменьшить количество измерений до разумного количества (например,г. 50)
| если количество функций очень велико.
Другой ключевой недостаток состоит в том, что он:
«Поскольку t-SNE квадратично масштабируется по количеству объектов N, его применимость ограничена наборами данных с несколькими тысячами входных объектов; кроме того, обучение становится слишком медленным, чтобы быть практичным (и требования к памяти становятся слишком большими) ».
Мы будем использовать реализацию алгоритма Scikit-Learn в оставшейся части этой статьи.
Вопреки приведенной выше рекомендации мы сначала попробуем запустить алгоритм на фактических размерах данных (784) и посмотрим, как это работает.Чтобы не перегружать нашу машину памятью и мощностью / временем, мы будем использовать только первые 10 000 выборок для запуска алгоритма. Для сравнения позже я также снова запущу PCA на подмножестве.
N = 10000df_subset = df.loc [rndperm [: N] ,:]. Copy () data_subset = df_subset [feat_cols] .valuespca = PCA (n_components = 3)
pca_result = pca.fit_transform (data_subset) df_subset) df_subset -one '] = pca_result [:, 0]
df_subset [' pca-two '] = pca_result [:, 1]
df_subset [' pca-three '] = pca_result [:, 2] print (' Разъясненное изменение для каждого участника составная часть: {}'.формат (pca.explained_variance_ratio _)) [out] Объясненная вариация по главному компоненту: [0,09730166 0,07135901 0,06183721]
x
time_start = time.time ()
tsne = TSNE (n_components = 2, verbose = 1, perplexity = n_iter = 300)
tsne_results = tsne.fit_transform (data_subset) print ('t-SNE done! Истекшее время: {} секунд'.format (time.time () - time_start)) [out] [t-SNE] Вычисления 121 ближайшие соседи ...
[t-SNE] Проиндексировано 10000 выборок за 0,564 с ...
[t-SNE] Вычисленные соседи для 10000 выборок в 121.191 с ...
[t-SNE] Вычисленные условные вероятности для выборки 1000/10000
[t-SNE] Вычисленные условные вероятности для выборки 2000/10000
[t-SNE] Вычисленные условные вероятности для выборки 3000/10000
[t- SNE] Вычисленные условные вероятности для выборки 4000/10000
[t-SNE] Вычисленные условные вероятности для выборки 5000/10000
[t-SNE] Вычисленные условные вероятности для выборки 6000/10000
[t-SNE] Вычисленные условные вероятности для выборки 7000 / 10000
[t-SNE] Вычисленные условные вероятности для выборки 8000/10000
[t-SNE] Вычисленные условные вероятности для выборки 9000/10000
[t-SNE] Вычисленные условные вероятности для выборки 10000/10000
[t-SNE] Средняя сигма: 2.129023
[t-SNE] Расхождение KL после 250 итераций с ранним преувеличением: 85.957787
[t-SNE] Расхождение KL после 300 итераций: 2,823509
t-SNE выполнено! Истекшее время: 157,3975932598114 секунды
Теперь, когда у нас есть два результирующих измерения, мы можем снова визуализировать их, создав диаграмму рассеяния двух измерений и раскрасив каждый образец соответствующей меткой.
df_subset ['tsne-2d-one'] = tsne_results [:, 0]
df_subset ['tsne-2d-two'] = tsne_results [:, 1] plt.figure (figsize = (16,10))
sns.scatterplot (
x = "tsne-2d-one", y = "tsne-2d-two",
hue = "y",
palette = sns.color_palette ( "hls", 10),
data = df_subset,
legend = "full",
alpha = 0.3
)
Это уже значительное улучшение по сравнению с визуализацией PCA, которую мы использовали ранее. Мы можем видеть, что цифры очень четко сгруппированы в свои собственные подгруппы. Если бы мы теперь использовали алгоритм кластеризации для выделения отдельных кластеров, мы, вероятно, могли бы довольно точно назначить новые точки метке.Просто для сравнения PCA и T-SNE:
plt.figure (figsize = (16,7)) ax1 = plt.subplot (1, 2, 1)PCA (слева) vs T-SNE (справа)
sns.scatterplot (
x = "pca-one", y = "pca-two",
hue = "y",
palette = sns.color_palette ("hls", 10),
data = df_subset,
legend = "full",
alpha = 0.3,
ax = ax1
) ax2 = plt.subplot (1, 2, 2)
sns.scatterplot (
x = "tsne-2d-one", y = "tsne-2d-two",
hue = "y",
palette = sns .color_palette ("hls", 10),
data = df_subset,
legend = "full",
alpha = 0.3,
ax = ax2
)
Примите рекомендации близко к сердцу и фактически уменьшите количество измерений, прежде чем вводить данные в алгоритм t-SNE.Для этого мы снова воспользуемся PCA. Сначала мы создадим новый набор данных, содержащий пятьдесят измерений, сгенерированных алгоритмом редукции PCA. Затем мы можем использовать этот набор данных для выполнения t-SNE для
pca_50 = PCA (n_components = 50)
pca_result_50 = pca_50.fit_transform (data_subset) print ('Кумулятивная объясненная вариация для 50 основных компонентов: {}'. Format (np .sum (pca_50.explained_variance_ratio _))) [out] Кумулятивная объясненная вариация для 50 основных компонентов: 0,8267618822147329
Удивительно, но первые 50 компонентов составляют примерно 85% общей вариации данных.
Теперь давайте попробуем передать эти данные в алгоритм t-SNE. На этот раз мы используем 10 000 сэмплов из 70 000, чтобы убедиться, что алгоритм не занимает слишком много памяти и ЦП. Поскольку код, используемый для этого, очень похож на предыдущий код t-SNE, я переместил его в раздел «Приложение: код» внизу этого сообщения. Полученный график выглядит следующим образом:
PCA (слева) vs T-SNE (в центре) vs T-SNE на PCA50 (справа)На этом графике мы можем ясно видеть, как все образцы хорошо разнесены и сгруппированы их соответствующие цифры.Это может быть отличной отправной точкой для последующего использования алгоритма кластеризации и попытки идентифицировать кластеры или фактически использовать эти два измерения в качестве входных данных для другого алгоритма (например, чего-то вроде нейронной сети).
Итак, мы исследовали использование различных методов уменьшения размерности для визуализации данных большой размерности с использованием двухмерной диаграммы рассеяния. Мы не вдавались в фактическую математику, а вместо этого полагались на реализации всех алгоритмов Scikit-Learn.
Прежде чем закончить с приложением…
Вместе с друзьями-единомышленниками мы рассылаем еженедельные информационные бюллетени с некоторыми ссылками и заметками, которыми мы хотим поделиться между собой (почему бы не позволить другим читать их?).
Код: t-SNE на данных с сокращенным PCA
time_start = time.time () tsne = TSNE (n_components = 2, verbose = 0, perplexity = 40, n_iter = 300)
tsne_pca_results = tsne.fit_transform (pca_result_50) print ('t-SNE done! Прошло времени: {} секунд'.format (time.time () - time_start)) [out] t-SNE готово! Истекшее время: 42,01495909690857 секунд
А для визуализации
df_subset ['tsne-pca50-one'] = tsne_pca_results [:, 0].
df_subset ['tsne-pca50-two'] = tsne_pca 1_results [.: figure (figsize = (16,4)) ax1 = plt.subplot (1, 3, 1)
sns.scatterplot (
x = "pca-one", y = "pca-two",
hue = "y" ,
palette = sns.color_palette ("hls", 10),
data = df_subset,
legend = "full",
alpha = 0.3,
ax = ax1
) ax2 = plt.subplot (1, 3, 2)
sns.scatterplot (
x = "tsne-2d-one", y = "tsne-2d-two",
hue = "y",
palette = sns.color_palette ("hls ", 10),
data = df_subset,
legend =" full ",
alpha = 0.3,
ax = ax2
) ax3 = plt.subplot (1, 3, 3)
sns.scatterplot (
x =" tsne -pca50-one ", y =" tsne-pca50-two ",
hue =" y ",
palette = sns.color_palette (" hls ", 10),
data = df_subset,
legend =" full ",
альфа = 0,3,
ax = ax3
)
Основы баз данных — Access
В этой статье дается краткий обзор баз данных — что это такое, почему вы можете захотеть ее использовать и что делают разные части базы данных. Терминология ориентирована на базы данных Microsoft Access, но концепции применимы ко всем продуктам баз данных.
В этой статье
Что такое база данных?
Части базы данных Access
Что такое база данных?
База данных — это инструмент для сбора и систематизации информации.Базы данных могут хранить информацию о людях, товарах, заказах или о чем-либо еще. Многие базы данных начинаются со списка в текстовом редакторе или электронной таблице. По мере того, как список становится больше, в данных начинают появляться повторяющиеся и несогласованные данные. Данные в форме списка становятся трудными для понимания, а способы поиска или извлечения подмножеств данных для проверки ограничены. Как только эти проблемы начинают появляться, рекомендуется перенести данные в базу данных, созданную системой управления базами данных (СУБД), такой как Access.
Компьютеризированная база данных — это контейнер объектов. Одна база данных может содержать более одной таблицы. Например, система отслеживания запасов, использующая три таблицы, — это не три базы данных, а одна база данных, содержащая три таблицы. Если база данных Access не была специально разработана для использования данных или кода из другого источника, она хранит свои таблицы в одном файле вместе с другими объектами, такими как формы, отчеты, макросы и модули. Базы данных, созданные в формате Access 2007 (который также используется в Access, 2016, Access 2013 и Access 2010), имеют расширение файла.accdb, а базы данных, созданные в более ранних форматах Access, имеют расширение файла .mdb. Вы можете использовать Access 2016, Access 2013, Access 2010 или Access 2007 для создания файлов в более ранних форматах файлов (например, Access 2000 и Access 2002-2003).
Используя Access, вы можете:
Добавить новые данные в базу данных, например новый товар в инвентаре
Редактирование существующих данных в базе данных, например изменение текущего местоположения элемента
Удалить информацию, возможно, если предмет продан или выброшен
Различные способы организации и просмотра данных
Делитесь данными с другими через отчеты, сообщения электронной почты, интранет или Интернет
Части базы данных Access
В следующих разделах представлены краткие описания частей типичной базы данных Access.
Столы
Формы
Отчеты
Запросы
Макросы
Модули
Таблицы
Таблица базы данных похожа на электронную таблицу, поскольку данные хранятся в строках и столбцах.В результате обычно довольно просто импортировать электронную таблицу в таблицу базы данных. Основное различие между хранением ваших данных в электронной таблице и их хранением в базе данных заключается в том, как они организованы.
Чтобы получить максимальную гибкость от базы данных, данные должны быть организованы в таблицы, чтобы не возникало избыточности. Например, если вы храните информацию о сотрудниках, каждого сотрудника нужно ввести только один раз в таблицу, которая настроена только для хранения данных о сотрудниках.Данные о продуктах будут храниться в отдельной таблице, а данные о филиалах — в другой таблице. Этот процесс называется нормализацией .
Каждая строка в таблице называется записью. Записи — это место, где хранятся отдельные фрагменты информации. Каждая запись состоит из одного или нескольких полей. Поля соответствуют столбцам в таблице. Например, у вас может быть таблица с именем «Сотрудники», где каждая запись (строка) содержит информацию о разных сотрудниках, а каждое поле (столбец) содержит информацию другого типа, такую как имя, фамилия, адрес и т. Д. на.Поля должны быть обозначены как определенный тип данных, будь то текст, дата или время, число или какой-либо другой тип.
Другой способ описать записи и поля — это визуализировать библиотечный карточный каталог старого образца. Каждой карте в шкафу соответствует запись в базе данных. Каждая часть информации на отдельной карточке (автор, название и т. Д.) Соответствует полю в базе данных.
Дополнительные сведения о таблицах см. В статье Введение в таблицы.
Формы
Формы позволяют создавать пользовательский интерфейс, в котором вы можете вводить и редактировать свои данные. Формы часто содержат командные кнопки и другие элементы управления, которые выполняют различные задачи. Вы можете создать базу данных без использования форм, просто отредактировав свои данные в таблицах. Однако большинство пользователей баз данных предпочитают использовать формы для просмотра, ввода и редактирования данных в таблицах.
Вы можете запрограммировать командные кнопки, чтобы определять, какие данные будут отображаться в форме, открывать другие формы или отчеты или выполнять множество других задач.Например, у вас может быть форма под названием «Форма клиента», в которой вы работаете с данными клиентов. В форме клиента может быть кнопка, которая открывает форму заказа, в которой вы можете ввести новый заказ для этого клиента.
Forms также позволяют контролировать, как другие пользователи взаимодействуют с данными в базе данных. Например, вы можете создать форму, которая отображает только определенные поля и позволяет выполнять только определенные операции. Это помогает защитить данные и обеспечить правильный ввод данных.
Дополнительные сведения о формах см. В статье Введение в формы.
Отчеты
Отчеты — это то, что вы используете для форматирования, обобщения и представления данных. Отчет обычно отвечает на конкретный вопрос, например, «Сколько денег мы получили от каждого клиента в этом году?» или «В каких городах находятся наши клиенты?» Каждый отчет можно отформатировать так, чтобы информация была представлена в наиболее удобочитаемом виде.
Отчет можно запустить в любое время, и он всегда будет отражать текущие данные в базе данных.Отчеты обычно форматируются для распечатки, но их также можно просматривать на экране, экспортировать в другую программу или отправлять в виде вложения к сообщению электронной почты.
Дополнительные сведения об отчетах см. В статье Общие сведения об отчетах в Access.
запросов
Запросы могут выполнять множество различных функций в базе данных. Их наиболее распространенная функция — извлекать определенные данные из таблиц. Данные, которые вы хотите просмотреть, обычно распределены по нескольким таблицам, а запросы позволяют просматривать их в одной таблице.Кроме того, поскольку обычно вы не хотите видеть все записи сразу, запросы позволяют добавлять критерии для «фильтрации» данных только до тех записей, которые вам нужны.
Некоторые запросы являются «обновляемыми», то есть вы можете редактировать данные в базовых таблицах с помощью таблицы запроса. Если вы работаете с обновляемым запросом, помните, что ваши изменения фактически вносятся в таблицы, а не только в таблицу данных запроса.
Запросыбывают двух основных типов: запросы выбора и запросы действия.Запрос на выборку просто извлекает данные и делает их доступными для использования. Вы можете просмотреть результаты запроса на экране, распечатать его или скопировать в буфер обмена. Или вы можете использовать выходные данные запроса в качестве источника записей для формы или отчета.
Запрос действия, как следует из названия, выполняет задачу с данными. Запросы действий могут использоваться для создания новых таблиц, добавления данных в существующие таблицы, обновления данных или удаления данных.
Дополнительные сведения о запросах см. В статье Введение в запросы.
Макросы
Макросы в Access можно рассматривать как упрощенный язык программирования, который можно использовать для добавления функций в базу данных. Например, вы можете прикрепить макрос к командной кнопке в форме, чтобы макрос запускался при каждом нажатии кнопки. Макросы содержат действия, которые выполняют задачи, такие как открытие отчета, выполнение запроса или закрытие базы данных. Большинство операций с базой данных, которые вы выполняете вручную, можно автоматизировать с помощью макросов, поэтому они могут отлично сэкономить время.
Дополнительные сведения о макросах см. В статье «Введение в программирование в Access».
Модули
Модули, как и макросы, — это объекты, которые вы можете использовать для добавления функциональности в свою базу данных. В то время как вы создаете макросы в Access, выбирая макрокоманды из списка, вы пишете модули на языке программирования Visual Basic для приложений (VBA). Модуль — это набор объявлений, операторов и процедур, которые хранятся вместе как единое целое.Модуль может быть либо модулем класса, либо стандартным модулем. Модули класса прикрепляются к формам или отчетам и обычно содержат процедуры, относящиеся к форме или отчету, к которым они прикреплены. Стандартные модули содержат общие процедуры, не связанные ни с какими другими объектами. Стандартные модули перечислены в разделе Модули в области навигации, тогда как модули классов — нет.
Дополнительные сведения о модулях см. В статье Введение в программирование в Access.
Верх страницы
.Что такое база данных? Определение, значение, типы, пример
- Home
Тестирование
- Back
- Agile Testing
- BugZilla
- Cucumber
- Тестирование базы данных
- 9000 J27 Тестирование базы данных
- 9000 J27
- JUnit
- LoadRunner
- Ручное тестирование
- Мобильное тестирование
- Mantis
- Почтальон
- QTP
- Назад
- Центр контроля качества (ALM)
- 000
- RPA Управление тестированием
- TestLink
SAP
- Назад
- ABAP 900 03 APO
- Новичок
- Basis
- BODS
- BI
- BPC
- CO
- Назад
- CRM
- Crystal Reports
- MMO
HAN
- Назад
- PI / PO
- PP
- SD
- SAPUI5
- Безопасность
- Менеджер решений
- Successfactors
- SAP Tutorials
- Назад
- Java
- JSP
- Kotlin
- Linux
- Linux
- Kotlin
- Linux js
- Perl
- Назад
- PHP
- PL / SQL
- PostgreSQL
- Python
- ReactJS
- Ruby & Rails
- Scala
- SQL 000
- SQL 000 0003 SQL 000 0003 SQL 000
- UML
- VB.Net
- VBScript
- Веб-службы
- WPF
Обязательно учите!
- Назад
- Бухгалтерский учет
- Алгоритмы
- Android
- Блокчейн
- Business Analyst
- Создание веб-сайта
- Облачные вычисления
- COBOL
- Встроенные системы
- 0003 Эталон
- 9000 Дизайн 900 Ethical
9009
- Назад
- Prep
- PM Prep
- Управление проектом Salesforce
- SEO
- Разработка программного обеспечения
- VBA
Большие данные
- Назад
- AWS
- BigData
- Cassandra
- Cognos
- Хранилище данных
- DevOps Back
- DevOps Back
- HBase
- HBase2
- MongoDB
SQL и NoSQL: в чем разница?
Посмотрите базы данных SQL и NoSQL, их отличия и какой вариант лучше всего подходит для вашей ситуации.
Разработчики приложений в двадцать первом веке сталкиваются с головокружительной массой решений, связанных с базами данных. На выбор доступны сотни различных баз данных, и хотя не все из них относятся к категории «никого не увольняли за это», многие из них являются надежными частями универсальной технологии.С другой стороны, почти каждая коммерчески поддерживаемая база данных может претендовать на некоторых важных клиентов в качестве ссылок, независимо от того, насколько нишевой является сама база данных.
Чтобы иметь некоторое представление о ландшафте, полезно иметь под рукой таксономию. Хорошо это или плохо, но самая популярная таксономия за последние 10 лет делит ландшафт на два класса: SQL (реляционные базы данных) и NoSQL (все остальное).
Это жесткое различие, похожее на разделение продуктового магазина на «производить» и «не производить», но оно имеет важные последствия для создания и поддержки программного обеспечения.Давайте глубже посмотрим, что означают эти два названия, и посмотрим, что они на самом деле значат для разработчиков приложений.
Что такое база данных SQL?
Короче говоря, базы данных SQL поддерживают SQL — предметно-ориентированный язык для запросов и управления данными в реляционной базе данных. Термин «реляционный» в реляционной базе данных относится к «реляционной модели» управления данными, разработанной исследователем IBM Э. Ф. Коддом в начале 1970-х годов и популяризированной в ряде последующих систем баз данных, начиная с System R.
Ключ к реляционной модели — абстрагирование данных как набора кортежей, организованных в отношения, что позволяет абстрагироваться от физического представления данных и путей доступа. Хотя SQL — не единственный возможный язык для реализации запросов по реляционной модели — на самом деле он не соответствует строго исходной конструкции Кодда — он, безусловно, самый популярный.
SQL и реляционные базы данных были отраслевым стандартом с конца 1970-х годов, хотя их так называемые «навигационные» предшественники, такие как IMS эпохи Apollo, в некоторых случаях все еще находятся в активной разработке.Большинство популярных «корпоративных» систем являются прямыми потомками System R и унаследовали большую часть ее конструктивных ограничений.
«NewSQL» и «Распределенный SQL»
В ответ на проблемы «выбросить ребенка с водой в ванну» с NoSQL (см. Ниже) в начале 2010-х годов, несколько организаций начали создавать системы на основе реляций / SQL, которые пошли на разные компромиссы, особенно в отношении горизонтальной масштабируемости. Это привело к двум в значительной степени различным путям:
- NewSQL: Игра на NoSQL, эти системы обычно используют существующие реляционные базы данных и логику, распределенную по уровням, с разной степенью прозрачности для пользователя.Citus и Vitess — два ярких примера распределенных движков в стиле «NewSQL».
- Распределенный SQL: В этих системах используется подход «с нуля» при создании горизонтально масштабируемых реляционных механизмов. CockroachDB и Google Spanner — хорошие тому примеры. Эти движки обычно стремятся выше, чем их аналоги в NewSQL. Однако важно отметить, что одной из мотиваций для NoSQL и NewSQL является тот факт, что создание полноценной реляционной базы данных очень дорого, и зрелость коммерчески доступных распределенных систем SQL часто отражает это.
Базы данных SQL: плюсы и минусы
Плюсы
- Уменьшение объема хранилища данных за счет нормализации и других возможностей оптимизации. Часто приводит к повышению производительности и более эффективному использованию ресурсов.
- Сильная и понятная семантика целостности данных через ACID (атомарность, согласованность, изоляция, надежность).
- Стандартный доступ к данным через SQL.
- Обычно более гибкая поддержка запросов, способная обрабатывать более широкий диапазон рабочих нагрузок.SQL абстрагируется от базовой реализации и позволяет механизму оптимизировать запросы в соответствии с их представлением на диске.
Минусы
- Жесткие модели данных, требующие тщательного предварительного проектирования для обеспечения адекватной производительности и сопротивления эволюции — изменение схемы часто приводит к простоям.
- Горизонтальное масштабирование является сложной задачей — оно либо полностью не поддерживается, либо поддерживается специальным образом, либо поддерживается только относительно незрелыми технологиями.
- Нераспределенные механизмы обычно представляют собой «единую точку отказа», которую необходимо смягчать с помощью методов репликации и аварийного переключения; нет иллюзий бесконечной масштабируемости
Примеры баз данных SQL
Что такое база данных NoSQL?
К сожалению, не очень понятно! В какой-то момент «NoSQL» означал, что база данных не поддерживает SQL.Это было достаточно бесполезно — если он не поддерживает SQL, что он поддерживает? — но, что еще хуже, в конечном итоге он превратился в обозначение «не только SQL», к большому огорчению разработчиков, которые на самом деле пытаются выполнить работу.
В то время как это движение явно имело корни в хранилищах графиков, документов и ключей и значений, восходящих к началу 1990-х годов, NoSQL действительно начал набирать обороты в середине 2000-х. Вдохновленный публикацией отраслевых исследовательских работ по нереляционным системам, таким как Google BigTable и Amazon Dynamo, кустарная индустрия стартапов и проектов с открытым исходным кодом возникла в результате разработки систем баз данных, которые исследовали пространство дизайна за пределами реляционной модели.Это было в значительной степени направлено на решение двух предполагаемых проблем с существующими системами:
- Отсутствие горизонтальной масштабируемости
- Жесткость конструкции стола в реляционных системах
Обратите внимание, что ни одна из этих проблем не имеет большого отношения к SQL, но вместо этого отражает проектные решения и ограничения популярных реляционных баз данных. Хотя сообщество реляционных баз данных отчасти ответило на этот вызов (см. Выше о «NewSQL»), как только ворота были открыты, так сказать, новые базы данных начали появляться очень быстро.Результатом является распространение систем, каждая из которых решает фундаментальную проблему — хранение некоторых битов и предоставление их позже — немного по-другому.
Во многих отношениях это благо для разработчиков. Конечно, верно, что не все приложения имеют проблемы, связанные с реляционными базами данных, или им нужно идти на компромиссы, которые реляционные базы данных навязывают моделям данных и доступности. Однако за эту свободу приходится платить — для того, чтобы принять хорошее технологическое решение между базами данных NoSQL, разработчик должен быть вооружен доскональным пониманием всего пространства проектирования, чтобы компромиссы, допускаемые конкретной системой, были очевидны.Другими словами, вы не хотите случайно отказываться от изоляции согласованности, когда она действительно требуется вашему приложению.
Базы данных NoSQL: плюсы и минусы
Именно по этой причине сложно обобщить плюсы и минусы NoSQL. Пространство хорошо исследовано, и диапазон доступных опций огромен. Некоторые общие плюсы и минусы, которые могут не относиться ко всем хранилищам NoSQL, включают следующее:
Плюсы
- Масштабируемость и высокая доступность — многие базы данных NoSQL обычно предназначены для поддержки бесшовной горизонтальной масштабируемости в оперативном режиме без значительных единичных точек отказа.
- Гибкие модели данных — большинство нереляционных систем не требуют от разработчиков предварительных обязательств по моделям данных; Какие схемы действительно существуют, часто можно изменить на лету.
- Высокая производительность — ограничивая диапазон возможностей базы данных (например, ослабляя гарантии долговечности), многие системы NoSQL могут достичь чрезвычайно высокого уровня производительности.
- Абстракции данных высокого уровня — выходя за рамки модели данных «значение в ячейке», системы NoSQL могут предоставлять высокоуровневые API-интерфейсы для мощных структур данных.Redis, например, включает абстракцию набора с собственной сортировкой
Минусы
- Расплывчатые интерпретации ограничений ACID — несмотря на широко распространенные утверждения о поддержке ACID для систем NoSQL, интерпретация ACID часто делается настолько широкой, что мало что можно сделать о семантике рассматриваемой базы данных. Например, что означает «изоляция» без транзакций?
- Распределенные системы имеют проблемы с распределенными системами. Хотя это и не является уникальным явлением для систем NoSQL, это скорее норма, чем исключение, для разработчиков, программирующих против NoSQL, чтобы глубоко понять, e.g., Теорема CAP и ее интерпретация в рассматриваемой базе данных.
- Отсутствие гибкости в шаблонах доступа — реляционная абстракция / SQL дает ядру базы данных широкие возможности для оптимизации запросов к базовым данным; без этой абстракции представление данных на диске попадает в запросы приложения и не оставляет места для оптимизации движку.
Примеры баз данных NoSQL
SQL против NoSQL: когда использовать каждый
Когда использовать SQL
Когда у вас есть реляционные данные, это, конечно, естественное совпадение.Но вы можете спросить себя, как определить «мифическое» естественное соответствие. Что ж, когда вы смотрите на свои данные, видите ли вы отдельные объекты с четко определенными отношениями друг с другом, которые должны быть строго соблюдены и / или доступны для навигации? Если да, то у нас есть совпадение!
Когда вы сосредоточены на целостности данных, лучше всего положиться на проверенные и надежные реляционные базы данных. Если вам нужен гибкий доступ к вашим данным, реляционная модель и SQL позволяют значительно расширить поддержку специальных запросов. Кроме того, в такие базы данных, как PostgreSQL, добавлена отличная поддержка рабочих нагрузок в стиле NoSQL с такими функциями, как собственные типы данных JSON.Если вам не нужны возможности горизонтального масштабирования хранилищ данных NoSQL, они также могут хорошо подойти для некоторых нереляционных рабочих нагрузок. Это делает их отличным швейцарским армейским ножом, когда у вас есть некоторые реляционные данные и некоторые неструктурированные данные, но вы не хотите покупать сложность работы с различными типами хранилищ данных.
Хотя многие люди смотрят на NoSQL из-за простоты, важно понимать значение этих хранилищ данных при создании приложения. Хотя это правда, что с ними легко начать, важно понимать последствия согласованности записи (или ее отсутствия), конечной согласованности и влияния сегментирования на способ доступа к данным в будущем.На реляционных базах данных может быть проще построить надежное приложение, поскольку они избавляют вас от беспокойства о таких проблемах.
Когда использовать NoSQL
NoSQL привлекателен, когда у вас есть очень гибкие модели данных или очень специфические потребности, которые не вписываются в реляционную модель. Если вы принимаете много неструктурированных данных, база данных документов, такая как MongoDB или CouchDB, может вам подойти. Если вам нужен очень быстрый доступ к данным «ключ-значение», но вы можете жить без надежных гарантий целостности, Redis отлично подойдет.Сложный или гибкий поиск по большому количеству данных? Elasticsearch отлично подходит.
Хранилища данныхNoSQL обычно хорошо масштабируются, и масштабирование является основным принципом многих из этих систем. Встроенный сегментирование значительно упрощает масштабирование операций чтения и записи по сравнению с реляционной базой данных. Соответственно, системы NoSQL часто могут соответствовать очень высоким требованиям доступности. Базы данных, такие как Cassandra, не имеют единой точки отказа, и ваши приложения могут тривиально реагировать на базовые отказы отдельных членов.
Заключение и следующие шаги
Выбор или рекомендация базы данных — нетривиальное занятие даже для экспертов по базам данных. Разделение SQL и NoSQL — полезный критерий, помогающий обосновать это решение, но, в конечном счете, ничто не может заменить тщательного обдумывания потребностей вашего приложения в данных и компромиссов, которые вы готовы принять для достижения целей производительности или времени безотказной работы.
По крайней мере, тот факт, что NoSQL существует, является благом для систем — это повод исследовать пространство дизайна и найти «сладкие места», которые решают проблемы реальных приложений.Тем не менее, в 2020 году есть бесчисленное множество причин продолжать выбирать SQL.
IBM Cloud поддерживает размещенные в облаке версии ряда баз данных SQL и NoSQL через предложения IBM Cloud Databases. Дополнительную информацию о том, как выбрать подходящий вариант, можно найти в разделах «Краткий обзор ландшафта базы данных» и «Как выбрать базу данных в IBM Cloud».
.CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 100%
Последнее обновление 2 апреля 2019 г., автор Admin
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 100%
Разработчик сети должен предоставить заказчику обоснование для проекта, который переместит предприятие от плоской топологии сети к иерархической топологии сети. Какие две особенности иерархического дизайна делают его лучшим выбором? (Выберите два.)
- более низкие требования к пропускной способности
- снижение затрат на оборудование и обучение пользователей
- проще обеспечить резервные ссылки для обеспечения более высокой доступности На
- меньше необходимого оборудования для обеспечения того же уровня производительности
- Более простое развертывание для дополнительного коммутационного оборудования
Пояснение: Иерархическая структура коммутаторов помогает администраторам сети при планировании и развертывании расширения сети, выполнении изоляции сбоев при возникновении проблемы и обеспечении отказоустойчивости при высоком уровне трафика.Хорошая иерархическая структура имеет избыточность, когда она может быть предоставлена так, чтобы один коммутатор не приводил к отключению всех сетей.
Что такое свернутое ядро в конструкции сети?
- сочетание функциональности уровней доступа и распределения
- сочетание функциональности распределительного и основного уровней
- сочетание функциональных возможностей уровня доступа и ядра
- комбинация функциональных возможностей уровней доступа, распределения и ядра
Пояснение: Конструкция с разрушенным сердечником подходит для небольшого индивидуального строительного бизнеса.В этом типе дизайна используются два уровня (свернутые уровни ядра и распределения, объединенные в один уровень, и уровень доступа). Более крупные предприятия используют традиционную модель трехуровневого коммутатора.
Каково определение двухуровневой сети LAN?
- Уровни доступа и ядра свернуты на один уровень, а уровень распределения на отдельный уровень
- уровней доступа и распределения свернуты на один уровень, а основной уровень на отдельный уровень
- уровни распределения и ядра свернуты в один уровень, а уровень доступа — на отдельный уровень
- уровней доступа, распределения и ядра свернуты в один уровень с отдельным уровнем магистрали
Пояснение: Поддержание трех отдельных уровней сети не всегда требуется или экономически эффективно.Для всех сетевых проектов требуется уровень доступа, но двухуровневый дизайн может свести уровни распределения и ядра в один уровень, чтобы удовлетворить потребности небольшого местоположения с небольшим количеством пользователей.
Какова основная функция уровня распространения архитектуры без границ Cisco?
- действует как магистраль
- , объединяющие все блоки кампуса
- агрегация границ маршрутизации уровня 3
- предоставление доступа к устройствам конечных пользователей
Пояснение: Одна из основных функций уровня распределения архитектуры Cisco Borderless Architecture — выполнение маршрутизации между различными VLAN.Действуя в качестве основы и агрегирование кампуса блоков являются функциями базового уровня. Предоставление доступа к устройствам конечного пользователя является функцией уровня доступа.
Какие две ранее независимые технологии следует попытаться объединить сетевому администратору после перехода на конвергентную сетевую инфраструктуру? (Выберите два.)
- трафик пользовательских данных
- Телефонный трафик VoIP
- сканеры и принтеры
- трафик сотовой связи
- электрическая система
Пояснение: Конвергентная сеть обеспечивает единую инфраструктуру, объединяющую голос, видео и данные.Аналоговые телефоны, пользовательские данные и двухточечный видеотрафик — все это содержится в единой сетевой инфраструктуре конвергентной сети.
Какой тип сети использует одну общую инфраструктуру для передачи голоса, данных и видеосигналов?
- переключено
- без полей
- конвергентный
- управляемый
Пояснение: Конвергентная сеть требует установки и управления только одной физической сетью.Это приводит к существенной экономии на установке и управлении отдельными сетями для передачи голоса, видео и данных.
Местная юридическая фирма модернизирует сеть компании, чтобы все 20 сотрудников могли быть подключены к локальной сети и Интернету. Юридическая фирма предпочла бы дешевое и простое решение для проекта. Какой тип переключателя выбрать?
- фиксированная конфигурация
- модульная конфигурация
- штабелируемая конфигурация
- StackPower
- StackWise
Пояснение: Глядя на график в 1.1.2.2 № 2 и № 3 и сравнивая эти фотографии с графикой, использованной в модели проектирования коммутатора Cisco, показанной в 1.1.1.5 № 2, вы можете видеть, что коммутатор фиксированной конфигурации меньшего блока стойки используется в качестве коммутатора уровня доступа. Переключатель модульной конфигурации будет использоваться на уровне распределения и ядра.
Каковы два преимущества модульных коммутаторов по сравнению с коммутаторами фиксированной конфигурации? (Выберите два.)
- более низкая стоимость переключателя
- повышенная масштабируемость
- более низкие тарифы на экспедирование
- Требуется меньшее количество розеток
- наличие нескольких портов для агрегирования полосы пропускания
Пояснение: Коммутаторы с фиксированной конфигурацией, хотя и дешевле, имеют определенное количество портов и не имеют возможности добавлять порты.Они также обычно предоставляют меньше высокоскоростных портов. Чтобы масштабировать коммутацию в сети, состоящей из коммутаторов с фиксированной конфигурацией, необходимо приобрести больше коммутаторов. Это увеличивает количество розеток, которые необходимо использовать. Модульные коммутаторы можно масштабировать, просто приобретая дополнительные линейные карты. Агрегирование полосы пропускания также упрощается, поскольку объединительная плата шасси может обеспечить полосу пропускания, необходимую для линейных карт портов коммутатора.
Какой тип адреса коммутатор использует для построения таблицы MAC-адресов?
- IP-адрес назначения
- IP-адрес источника
- MAC-адрес назначения
- MAC-адрес источника
Пояснение: Когда коммутатор получает кадр с исходным MAC-адресом, которого нет в таблице MAC-адресов, коммутатор добавит этот MAC-адрес в таблицу и сопоставит этот адрес с конкретным портом.Коммутаторы не используют IP-адресацию в таблице MAC-адресов.
Какое сетевое устройство можно использовать для устранения конфликтов в сети Ethernet?
- межсетевой экран
- ступица
- роутер
- переключатель
- Навигация
Пояснение: Коммутатор обеспечивает микросегментацию, чтобы никакое другое устройство не конкурировало за ту же полосу пропускания сети Ethernet.
Какие два критерия используются коммутатором Cisco LAN для принятия решения о пересылке кадров Ethernet? (Выберите два.)
- Стоимость пути
- выходной порт
- входной порт
- IP-адрес назначения
- MAC-адрес назначения
Пояснение: Коммутаторы Cisco LAN используют таблицу MAC-адресов для принятия решений о пересылке трафика. Решения основываются на входном порту и MAC-адресе назначения кадра.Информация о входном порте важна, поскольку она передает VLAN, к которой принадлежит порт.
См. Выставку. Считайте, что основное питание только что восстановили. ПК3 выдает широковещательный запрос DHCP IPv4. На какой порт SW1 перенаправит этот запрос?
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 01
- только по Fa0 / 1
- только для Fa0 / 1 и Fa0 / 2
- только для Fa0 / 1, Fa0 / 2 и Fa0 / 3
- — Fa0 / 1, Fa0 / 2, Fa0 / 3 и Fa0 / 4
- только для Fa0 / 1, Fa0 / 2 и Fa0 / 4
Пояснение: Поскольку это широковещательный кадр, SW1 отправит его на все порты, кроме входящего (порт, в котором был получен запрос).
Какова одна функция коммутатора уровня 2?
- пересылает данные на основе логической адресации
- дублирует электрический сигнал каждого кадра на каждый порт
- изучает порт, назначенный хосту, проверяя MAC-адрес назначения
- определяет, какой интерфейс используется для пересылки кадра на основе MAC-адреса назначения
Объяснение: Коммутатор создает таблицу MAC-адресов из MAC-адресов и связанных номеров портов, исследуя MAC-адрес источника, обнаруженный во входящих кадрах.Для пересылки кадра вперед коммутатор проверяет MAC-адрес назначения, ищет в MAC-адресе номер порта, связанный с этим MAC-адресом назначения, и отправляет его на определенный порт. Если MAC-адрес назначения отсутствует в таблице, коммутатор пересылает кадр на все порты, кроме входящего порта, из которого был создан кадр.
См. Выставку. Как кадр, отправленный из PCA, пересылается в PCC, если таблица MAC-адресов на коммутаторе SW1 пуста?
CCNA 2 RSE 6.0 Глава 4 Экзамен Ответы 2018 2019 02
- SW1 лавинно рассылает фрейм по всем портам коммутатора, за исключением взаимосвязанного порта для коммутатора SW2 и порта, через который фрейм поступил в коммутатор.
- SW1 лавинно рассылает фрейм по всем портам SW1, за исключением порта, через который фрейм поступил в коммутатор.
- SW1 пересылает рамку прямо на SW2. SW2 рассылает фрейм всем портам, подключенным к SW2, за исключением порта, через который фрейм поступил в коммутатор.
- SW1 отбрасывает кадр, потому что ему неизвестен MAC-адрес назначения.
Пояснение: Когда коммутатор включается, таблица MAC-адресов пуста. Коммутатор создает таблицу MAC-адресов, проверяя исходный MAC-адрес входящих кадров. Коммутатор выполняет переадресацию на основе MAC-адреса назначения, указанного в заголовке кадра. Если коммутатор не имеет записей в таблице MAC-адресов или если MAC-адрес назначения отсутствует в таблице коммутаторов, коммутатор перенаправит кадр на все порты, кроме порта, который доставил кадр в коммутатор.
У небольшой издательской компании есть такая структура сети, что, когда широковещательная передача отправляется по локальной сети, 200 устройств принимают передаваемую широковещательную передачу. Как администратор сети может уменьшить количество устройств, получающих широковещательный трафик?
- Добавьте больше коммутаторов, чтобы на одном коммутаторе было меньше устройств.
- Замените коммутаторы коммутаторами с большим количеством портов на коммутатор. Это позволит использовать больше устройств на определенном коммутаторе.
- Сегментируйте локальную сеть на меньшие локальные сети и маршрутизируйте между ними.
- Замените по крайней мере половину коммутаторов концентраторами, чтобы уменьшить размер широковещательного домена.
Пояснение: Разделив одну большую сеть на две меньшие сети, сетевой администратор создал два меньших широковещательных домена. Когда широковещательная рассылка отправляется по сети сейчас, широковещательная рассылка будет отправлена только на устройства в той же локальной сети Ethernet. Другая локальная сеть не получит широковещательную передачу.
См. Выставку. Сколько отображается широковещательных доменов?
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 03
- 1
- 4
- 8
- 16
- 55
Пояснение: Маршрутизатор определяет границу широковещательной рассылки, поэтому каждое соединение между двумя маршрутизаторами является широковещательным доменом. На выставке 4 канала между маршрутизаторами составляют 4 широковещательных домена.Кроме того, каждая локальная сеть, подключенная к маршрутизатору, является широковещательным доменом. 4 LAN на выставке приводят к появлению еще 4 широковещательных доменов, то есть всего 8 широковещательных доменов.
Какое решение поможет колледжу уменьшить перегрузку сети из-за коллизий?
- межсетевой экран, который подключается к двум интернет-провайдерам
- коммутатор с высокой плотностью портов
- роутер с двумя портами Ethernet
- маршрутизатор с тремя портами Ethernet
Пояснение: Коммутаторы обеспечивают микросегментацию, так что одно устройство не конкурирует за одну и ту же полосу пропускания сети Ethernet с другим сетевым устройством, что практически исключает конфликты.Коммутатор с высокой плотностью портов обеспечивает очень быстрое подключение многих устройств.
Какое сетевое устройство может служить границей для разделения широковещательного домена уровня 2?
- маршрутизатор
- Мост Ethernet
- Концентратор Ethernet
- точка доступа
Пояснение: Устройства уровня 1 и 2 (коммутатор LAN и концентратор Ethernet) и устройства точек доступа не фильтруют широковещательные кадры MAC.Только устройство уровня 3, такое как маршрутизатор, может разделить домен вещания уровня 2.
Какой адрес назначения в заголовке широковещательного кадра?
- 0,0.0.0
- 255.255.255.255
- 11-11-11-11-11-11
- FF-FF-FF-FF-FF-FF
Пояснение: В кадре широковещательной передачи уровня 2 MAC-адрес назначения (содержащийся в заголовке кадра) устанавливается на все двоичные единицы, поэтому формат FF-FF-FF-FF-FF-FF.Двоичный формат 11 в шестнадцатеричном формате — 00010001. 255.255.255.255 и 0.0.0.0 — это IP-адреса.
Какое утверждение описывает результат после соединения нескольких коммутаторов Cisco LAN?
- Широковещательный домен распространяется на все коммутаторы.
- Для каждого коммутатора существует один домен конфликтов.
- Число коллизий кадров увеличивается на сегментах, соединяющих переключатели.
- Для каждого коммутатора существует один домен широковещательной рассылки и один домен конфликтов.
Пояснение: В коммутаторах Cisco LAN микросегментация позволяет каждому порту представлять отдельный сегмент, и, таким образом, каждый порт коммутатора представляет отдельный домен конфликтов. Этот факт не изменится при соединении нескольких коммутаторов. Однако коммутаторы LAN не фильтруют широковещательные кадры. Кадр широковещательной рассылки рассылается по всем портам. Подключенные коммутаторы образуют один большой широковещательный домен.
Что означает термин «плотность портов» для коммутатора Ethernet?
- пространство памяти, выделенное каждому порту коммутатора
- количество доступных портов
- количество хостов, которые подключены к каждому порту коммутатора
- скорость каждого порта
Пояснение: Термин «плотность портов» обозначает количество портов, доступных в коммутаторе.Коммутатор доступа к одной стойке может иметь до 48 портов. Более крупные коммутаторы могут поддерживать сотни портов.
По каким двум причинам сетевой администратор сегментирует сеть с помощью коммутатора уровня 2? (Выберите два.)
- для создания меньшего количества коллизионных доменов
- для увеличения пропускной способности пользователя
- для создания дополнительных широковещательных доменов
- для исключения виртуальных цепей
- для изоляции трафика между сегментами
- для изоляции сообщений запроса ARP от остальной сети
Пояснение: Коммутатор имеет возможность создавать временные двухточечные соединения между напрямую подключенными передающими и принимающими сетевыми устройствами.Два устройства имеют полнодуплексное соединение с полной полосой пропускания во время передачи.
Сопоставьте описание рекомендаций по коммутируемой сети без границ с принципом. (Используются не все варианты.)
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 001
Сопоставьте функции с соответствующими слоями. (Используются не все варианты.)
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 002
Сопоставьте характеристику пересылки с ее типом.(Используются не все варианты.)
CCNA 2 RSE 6.0 Глава 4 Ответы на экзамен 2018 2019 003
Почему для шифрования RSA используется заполнение, учитывая, что это не блочный шифр?
RSA требует заполнения по совершенно другим причинам, чем шифрование в режиме CBC.
Блочные шифры, такие как AES и (тройной) DES, могут использоваться только для перестановки одного блока открытого текста на один блок зашифрованного текста. Это не очень полезно, поскольку обычно мы хотели бы зашифровать несколько сообщений переменного размера.
Кроме того, режим работы должен иметь какой-то вектор инициализации, чтобы результирующий шифр не был детерминированным.Если результат будет детерминированным, злоумышленник сможет легко проверить, идентичны ли два входных сообщения.
Только несколько режимов работы блочных шифров требуют заполнения. Однако режим работы CBC используется довольно часто и требует либо заполнения, либо кражи зашифрованного текста. Для блочных шифров, которые в основном состоят из побитовых операций и операций переупорядочения, заполнение используется только для заполнения последнего блока данных, предпочтительно таким образом, чтобы сообщение могло содержать любое байтовое значение.
RSA не является блочным шифром, как DES или AES. Основная операция RSA — это модульное возведение числа в степень. Это число является числовым представлением входящего сообщения с использованием заполнения. Однако не все числа одинаково хорошо подходят для RSA. Например, если число равно нулю или единице, RSA потерпит неудачу. По этой и многим другим причинам RSA требует, чтобы схема заполнения была безопасной. Эта схема заполнения должна соответствовать определенным требованиям для обеспечения безопасности; просто возможность кодировать / декодировать сообщение до определенного размера — лишь одно из многих требований.
Использование слова padding для RSA к настоящему времени довольно некорректно — оно в основном по-прежнему называется «padding» по историческим причинам. Схемы заполнения для RSA просто расширяли сообщение перед преобразованием числа. Но более новые схемы фактически изменяют и само сообщение; сообщение не может быть напрямую идентифицировано в номере до возведения в степень с помощью RSA. OAEP — это одна из схем, в которой все сообщение случайным образом преобразуется перед модульным возведением в степень RSA.
Если сообщение напрямую зашифровано RSA, тогда да, сообщение должно быть в определенных пределах.Поскольку используется модульное возведение в степень, требуется, чтобы сообщение + заполнение находилось в пределах модуля. Таким образом, размер сообщения зависит от размера модуля, а также от накладных расходов, связанных с заполнением.
Для старой небезопасной (но более простой для демонстрационных целей) схемы RSA, использующей заполнение PKCS # 1 v1.5, максимальный размер сообщения — это размер модуля в байтах, минус 11 для служебных данных заполнения. Таким образом, для шифрования можно использовать 2048-битный ключ RSA (2048/8) — 11 = 245 байт.Минимума нет, поэтому размер сообщения, которое можно зашифровать, составляет от нуля до 245 байт.
Однако на практике используются гибридные схемы шифрования вместо схем, в которых данные напрямую шифруются RSA. В этом случае симметричный шифр, такой как AES (с определенным режимом работы, таким как CBC), используется для шифрования фактического сообщения. Затем RSA используется для шифрования / дешифрования симметричного ключа. В этом случае размер сообщения зависит только от режима работы симметричного шифра (обычно несколько гигабайт или больше для AES в любом режиме работы).Ключ AES (-256) всегда должен легко вписываться в любые вычисления RSA для безопасного размера модуля, независимо от используемой схемы заполнения.
Другой метод — использовать RSA KEM, когда RSA вообще не зашифровывает ни один ключ или сообщение. RSA KEM используется для получения симметричного ключа для гибридного шифрования.
Что такое шифрование RSA и как оно работает?
ШифрованиеRSA — это система, которая решает то, что когда-то было одной из самых больших проблем в криптографии: Как вы можете отправить кому-либо закодированное сообщение , не имея возможности предварительно поделиться с ним кодом?
Эта статья расскажет вам все, что вам нужно знать о , как было разработано шифрование RSA , , как оно работает , математика, лежащая в основе этого , что он используется для , а также некоторые из самых серьезных проблем безопасности что он стоит перед .Изучение RSA даст вам некоторые фундаментальные знания, которые помогут вам понять, сколько частей нашей онлайн-жизни находится в безопасности.
Что такое шифрование RSA?Допустим, вы хотите рассказать другу секрет. Если ты рядом с ними, можешь просто прошептать это. Если вы находитесь на противоположных концах страны, это явно не сработает. Вы можете записать его и отправить им по почте или воспользоваться телефоном, но каждый из этих каналов связи небезопасен, и любой, у кого есть достаточно сильная мотивация, может легко перехватить сообщение.
Если секрет был достаточно важным, вы не рискнули бы записать его обычным образом — шпионы или мошенник почтовый служащий могли просматривать вашу почту. Точно так же кто-то может прослушивать ваш телефон без вашего ведома и регистрировать каждый ваш звонок.
Одно из решений для предотвращения доступа злоумышленников к содержимому сообщения — это зашифровать его . Это в основном означает добавление кода к сообщению, который превращает его в беспорядочный беспорядок. Если ваш код достаточно сложен, то единственные люди, которые смогут получить доступ к исходному сообщению, — это те, у кого есть доступ к коду.
Если у вас была возможность поделиться кодом с другом заранее, то любой из вас может отправить зашифрованное сообщение в любое время , зная, что вы двое — единственные, у кого есть возможность читать содержимое сообщения. Но что, если у вас не было возможности поделиться кодом заранее?
Это одна из фундаментальных проблем криптографии, которая решается с помощью схем шифрования с открытым ключом (также известных как асимметричное шифрование), таких как RSA .
При шифровании RSA сообщения шифруются с помощью кода, называемого открытым ключом , которым можно открыто делиться. Из-за некоторых отличных математических свойств алгоритма RSA после того, как сообщение было зашифровано с помощью открытого ключа, оно может быть расшифровано только другим ключом, известным как закрытый ключ . У каждого пользователя RSA есть пара ключей, состоящая из их открытого и закрытого ключей. Как следует из названия, закрытый ключ должен храниться в секрете.
Схемы шифрования с открытым ключомотличаются от шифрования с симметричным ключом , где и в процессе шифрования, и в процессе дешифрования используется один и тот же закрытый ключ .Эти различия делают шифрование с открытым ключом, такое как RSA, полезным для связи в ситуациях, когда не было возможности безопасно распространить ключи заранее.
Алгоритмыс симметричным ключом имеют свои собственные приложения, такие как шифрование данных для личного использования или для случаев, когда есть безопасные каналы, по которым можно передавать частные ключи.
См. Также: Криптография с открытым ключом
Где используется шифрование RSA? ШифрованиеRSA часто используется в комбинации с другими схемами шифрования или для цифровых подписей , которые могут подтвердить подлинность и целостность сообщения.Обычно он не используется для шифрования сообщений или файлов целиком, поскольку он менее эффективен и требует больше ресурсов, чем шифрование с симметричным ключом.
Чтобы сделать вещи более эффективными, файл обычно будет зашифрован с помощью алгоритма с симметричным ключом, а затем симметричный ключ будет зашифрован с помощью шифрования RSA. В рамках этого процесса только объект, имеющий доступ к закрытому ключу RSA, сможет расшифровать симметричный ключ.
Не имея доступа к симметричному ключу, исходный файл нельзя расшифровать .Этот метод можно использовать для защиты сообщений и файлов, не занимая слишком много времени и не потребляя слишком много вычислительных ресурсов.
ШифрованиеRSA может использоваться в различных системах. Его можно реализовать в OpenSSL, wolfCrypt, cryptlib и ряде других криптографических библиотек.
Как одна из первых широко используемых схем шифрования с открытым ключом, RSA заложила основу для большей части наших безопасных коммуникаций. Он был , который традиционно использовался в TLS , а также был исходным алгоритмом, используемым в шифровании PGP.RSA по-прежнему используется в ряде веб-браузеров, электронной почты, VPN, чата и других каналов связи.
RSA также часто используется для создания безопасных соединений между VPN-клиентами и VPN-серверами. В таких протоколах, как OpenVPN, рукопожатия TLS могут использовать алгоритм RSA для обмена ключами и установления безопасного канала.
Основы шифрования RSAКак мы упоминали в начале этой статьи, до шифрования с открытым ключом было сложно обеспечить безопасную связь, если не было возможности заранее безопасно обменяться ключами.Если бы не было возможности поделиться кодом заранее или безопасным каналом, через который можно было бы распространять ключи, не было бы возможности общаться без угрозы того, что враги смогут перехватить и получить доступ к содержимому сообщения.
Только в 1970-х все по-настоящему начали меняться. Первое крупное развитие того, что мы сейчас называем криптографией с открытым ключом, было опубликовано в начале десятилетия Джеймсом Х. Эллисом. Эллис не смог найти способ реализовать свою работу, но его коллега Клиффорд Кокс расширил ее до того, что мы теперь знаем как шифрование RSA .
Последний кусок головоломки — это то, что мы теперь называем обмен ключами Диффи-Хеллмана . Малкольм Дж. Уильямсон, другой сотрудник, придумал схему, которая позволяла двум сторонам использовать общий ключ шифрования, даже если канал контролировался злоумышленниками.
Вся эта работа была проведена в британском разведывательном управлении, в Управлении правительственной связи (GCHQ), которое держало открытие под классификацией . Частично из-за технологических ограничений GCHQ не видел в то время применения криптографии с открытым ключом, поэтому разработка стояла без дела на полке и пылялась. Только в 1997 году работа была рассекречена, и первоначальные изобретатели RSA были признаны .
Несколько лет спустя аналогичные концепции начали развиваться в публичной сфере. Ральф Меркл создал раннюю форму криптографии с открытым ключом , которая повлияла на Уитфилда Диффи и Мартина Хеллмана при разработке обмена ключами Диффи-Хеллмана.
В идеях Диффи и Хеллмана не хватало одного важного аспекта, который сделал бы их работу основой криптографии с открытым ключом.Это была односторонняя функция , которую было бы трудно инвертировать . В 1977 году Рон Ривест, Ади Шамир и Леонард Адлеман , фамилии которых образуют аббревиатуру RSA, после года работы над проблемой пришли к решению.
Ученые из Массачусетского технологического института совершили прорыв после пасхальной вечеринки в 1977 году. После ночи выпивки Ривест пошел домой, но вместо того, чтобы спать, он провел весь вечер, лихорадочно записывая документ, в котором формализовалась его идея о необходимой односторонней функции .
Идея была запатентована Массачусетским технологическим институтом в 1983 году, но только на заре Интернета алгоритм RSA получил широкое распространение в качестве важного инструмента безопасности.
Как работает шифрование RSA?Следующее будет немного упрощением, потому что слишком многие читатели, вероятно, были травмированы своим школьным учителем математики. Чтобы математика не выходила из-под контроля, мы упростим некоторые концепции и будем использовать гораздо меньшие числа .В действительности, шифрование RSA использует простые числа, которые намного больше по величине, и есть несколько других сложностей.
Есть несколько различных концепций, которые вам нужно обдумать, прежде чем мы сможем объяснить, как все это сочетается друг с другом. К ним относятся функции лазейки, генерация простых чисел, общая функция Кармайкла и отдельные процессы, задействованные в вычислении открытого и закрытого ключей , используемых в процессах шифрования и дешифрования.
Функции люка ШифрованиеRSA работает при условии, что алгоритм легко вычислить в одном направлении, но почти невозможно в обратном .Например, если бы вам сказали, что 701111 — произведение двух простых чисел, смогли бы вы выяснить, что это за два числа?
Даже имея калькулятор или компьютер, большинство из нас не будет иметь никакого представления о том, с чего начать, не говоря уже о том, чтобы найти ответ. Но если все перевернуть, становится намного проще. Что в результате:
907 х 773
Если бы вам было достаточно скучно, вы бы вытащили свой телефон или, возможно, вычислили его в своей голове, чтобы обнаружить, что ответ — ранее упомянутый 701 111.Эти 907 и 773 — простые числа, которые отвечают на наш первый вопрос, который показывает нам, что некоторые уравнения можно легко вычислить одним способом, но, по-видимому, невозможно наоборот.
Еще один интересный аспект этого уравнения заключается в том, что одно из простых чисел легко вычислить, если у вас уже есть другое, а также произведение. Если вам сказали, что 701111 — это результат умножения 907 на другое простое число, вы можете вычислить это другое простое число с помощью следующего уравнения:
701111 ÷ 907 = 773
Поскольку соотношение между этими числами просто вычислить в одном направлении, но невероятно сложно в обратном, уравнение известно как функция ловушки .Имейте в виду, что, хотя людям сложно разобраться в приведенном выше примере, компьютеры могут выполнить операцию за минимальное время.
Из-за этого RSA использует гораздо большие числа. Размер простых чисел в реальной реализации RSA варьируется, но в 2048-битном RSA они объединяются, чтобы получить ключи длиной 617 цифр. Чтобы облегчить вам визуализацию этого, ключом может быть число такого размера:
.99999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999999
Генерация простых чиселУпомянутые выше функции лазейки составляют основу работы схем шифрования с открытым и закрытым ключом. Их свойства позволяют обмениваться открытыми ключами, не подвергая опасности сообщение или не раскрывая закрытый ключ. . Они также позволяют зашифровать данные одним ключом таким образом, чтобы их можно было расшифровать только другим ключом из пары.
Первый шаг шифрования сообщения с помощью RSA — это сгенерировать ключи . Для этого нам нужны два простых числа ( p и q ) , которые выбираются с помощью теста на простоту.Тест на простоту — это алгоритм, который эффективно находит простые числа, например, тест на простоту Рабина-Миллера.
Простые числа в RSA должны быть очень большими и относительно далеко друг от друга. Маленькие или близкие друг к другу числа гораздо легче взломать. Несмотря на это, в нашем примере будут использоваться меньшие числа, чтобы упростить отслеживание и вычисления.
Предположим, что тест на простоту дает нам простые числа, которые мы использовали выше, 907 и 773. Следующий шаг — определить модуль ( n ), используя следующую формулу:
n = p x q
Где p = 907 и q = 773
Следовательно:
n = 907 x 773
n = 701,111
Тотализатор КармайклаКогда у нас есть n , мы используем общую функцию Кармайкла :
λ ( n ) = л · см ( p — 1, q — 1)
Если вы давно не читали учебники по математике, то приведенное выше может показаться немного устрашающим.Вы можете пропустить эту часть и просто поверить, что математика работает, в противном случае оставайтесь с нами для еще нескольких вычислений. Все будет объяснено максимально подробно, чтобы помочь вам разобраться в основах.
Для тех, кто не в курсе, λ (n) представляет собой совокупность Кармайкла для n , а lcm означает наименьшее общее кратное , которое является наименьшим числом, которое одновременно p и q можно разделить на.Есть несколько разных способов выяснить это, но самый простой — довериться онлайн-калькулятору, который сделает уравнение за вас. Итак, давайте представим наши числа в уравнении:
λ ( 701,111 ) = л · см ( 907 — 1, 773 — 1)
λ ( 701,111 ) = л · см ( 906, 772 )
Используя калькулятор, указанный выше, мы получаем:
λ ( 701111 ) = 349,716
Генерация открытого ключаТеперь, когда у нас есть набор простых чисел Кармайкла, настало время , чтобы вычислить наш открытый ключ. В рамках RSA открытые ключи состоят из простого числа e , а также модуля n (мы объясним, что означает модуль, в нескольких абзацах). Число e может быть любым от 1 до значения λ ( n ), которое в нашем примере равно 349 716.
Поскольку открытый ключ является открытым, не так важно, чтобы e было случайным числом. На практике e обычно устанавливается равным 65 537 , потому что, когда случайным образом выбираются гораздо большие числа, это делает шифрование гораздо менее эффективным.В сегодняшнем примере мы будем держать числа небольшими, чтобы вычисления были эффективными. Скажем:
e = 11
Наши окончательные зашифрованные данные называются зашифрованным текстом ( c ). Мы получаем его из нашего открытого текстового сообщения ( m ), применяя открытый ключ по следующей формуле:
c = м e мод n
Как мы уже упоминали, e mod n — это открытый ключ.Мы уже разработали e , и мы также знаем n . Единственное, что нам нужно объяснить, это mod . Это немного выходит за рамки этой статьи, но это относится к операции по модулю , что по сути означает остаток, оставшийся при делении одной стороны на другую. Например:
10 мод 3 = 1
Это потому, что 3 трижды переходит в 10, а остаток равен 1.
Вернемся к нашему уравнению. Для простоты предположим, что сообщение ( m ), которое мы хотим зашифровать и сохранить в секрете, представляет собой всего лишь одно число: 4 .Подключим все:
c = м e мод n
c = 4 11 мод 701111
c = 4,194,304 мод 701,111
Опять же, чтобы упростить операцию по модулю , мы будем использовать онлайн-калькулятор, но вы можете выяснить это сами. Введя 4 194 304 в онлайн-калькулятор, мы получим:
c = 688,749
Следовательно, когда мы используем RSA для шифрования нашего сообщения, 4 , с нашим открытым ключом, он дает нам зашифрованный текст 688 749 .Предыдущие шаги могут показаться слишком сложными с математикой, но важно повторить то, что произошло на самом деле.
У нас было сообщение о 4 , которое мы хотели сохранить в секрете. Мы применили к нему открытый ключ, который дал нам зашифрованный результат 688 749 . Теперь, когда он зашифрован, мы можем безопасно отправить число 688 749 владельцу пары ключей . Они — единственный человек, который сможет расшифровать его своим закрытым ключом. Когда они его расшифруют, они увидят сообщение, которое мы действительно отправляли, 4 .
Создание закрытого ключаПри шифровании RSA, как только данные или сообщение были преобразованы в зашифрованный текст с открытым ключом, они могут быть дешифрованы только закрытым ключом из той же пары ключей. Закрытые ключи состоят из d и n . Мы уже знаем n, , и для нахождения d используется следующее уравнение:
d = 1/ e mod λ ( n )
В приведенном выше разделе « Создание открытого ключа » мы уже решили, что в нашем примере e будет равно 11.Точно так же мы знаем, что λ ( n ) равняется 349 716 из нашей более ранней работы в рамках общей функции Кармайкла . Все становится немного сложнее, когда мы сталкиваемся с этим разделом формулы:
1/ e мод
Это уравнение может выглядеть так, как будто оно просит вас разделить 1 на 11, но это не так. Вместо этого это просто символизирует то, что нам нужно вычислить модульное обратное значение для e (которое в данном случае равно 11) и λ ( n ) (которое в данном случае равно 349 716).
По сути, это означает, что вместо стандартной операции по модулю мы будем использовать обратную . Обычно это можно найти с помощью расширенного алгоритма Евклида, но это немного выходит за рамки этой статьи, поэтому мы просто обманем и воспользуемся онлайн-калькулятором. Теперь, когда мы понимаем все, что происходит, давайте подставим полученную информацию в формулу:
d = 1/ 11 мод 349,716
Чтобы выполнить эту операцию, просто введите 11 (или любое значение, которое вы можете иметь для e , если вы пытаетесь это сделать в своем собственном примере), где указано Integer и 349,716 (или любое значение, которое вы можете иметь для λ ( n ), если вы пытаетесь это сделать на своем собственном примере), где указано Modulo в онлайн-калькуляторе, ссылка на который была указана выше.Если вы все сделали правильно, вы должны получить результат где:
д = 254, 339
Теперь, когда у нас есть значение d , мы можем расшифровать сообщения, зашифрованные с помощью нашего открытого ключа, используя следующую формулу:
м = c d мод n
Теперь мы можем вернуться к зашифрованному тексту, который мы зашифровали в разделе Создание закрытого ключа . Когда мы зашифровали сообщение с помощью открытого ключа, он дал нам значение для c из 688 749 .Из вышесказанного мы знаем, что d равно 254 339 . Мы также знаем, что n равно 701111 . Это дает нам:
м = 688,749 254,339 мод 701,111.
Как вы могли заметить, для большинства обычных калькуляторов попытка довести число до 254 339 степени может оказаться непосильной задачей. Вместо этого мы будем использовать онлайн-калькулятор расшифровки RSA. Если бы вы хотели использовать другой метод, вы бы применили полномочия, как обычно, и выполнили бы операцию модуля так же, как мы делали в разделе Создание открытого ключа .
В калькуляторе, указанном выше, введите 701111, где указано Модуль поставки: N , 254,399, где указано Ключ дешифрования: D , и 688,749, где указано Сообщение зашифрованного текста в числовой форме , как показано ниже:
После того, как вы ввели данные, нажмите Расшифровать , чтобы ввести числа в формулу дешифрования, указанную выше. Это даст вам исходное сообщение в поле ниже. Если вы все сделали правильно, вы должны получить ответ 4 , это было исходное сообщение, которое мы зашифровали с помощью нашего открытого ключа.
Как работает шифрование RSA на практикеПриведенные выше разделы должны дать вам разумное представление о том, как работает математика, лежащая в основе шифрования с открытым ключом. Это может немного сбивать с толку, но даже те, кто не разбирался в тонкостях уравнений, надеюсь, могут унести некоторую важную информацию о процессе.
В шагах, перечисленных выше, мы показали, как два объекта могут безопасно взаимодействовать без предварительного совместного использования кода.Во-первых, каждый из них должен установить свои собственные пары ключей и совместно использовать открытый ключ друг с другом . Эти два объекта должны хранить свои закрытые ключи в секрете, чтобы их обмен данными оставался безопасным.
Когда у отправителя есть открытый ключ получателя, он может использовать его для шифрования данных, которые они хотят сохранить в безопасности. После того, как он был зашифрован открытым ключом, его можно расшифровать только закрытым ключом из той же пары ключей . Даже один и тот же открытый ключ нельзя использовать для расшифровки данных.Это происходит из-за свойств функции люка , о которых мы упоминали выше.
Когда получатель получает зашифрованное сообщение, он использует свой закрытый ключ для доступа к данным. Если получатель хочет вернуть сообщения безопасным способом, , он может затем зашифровать свое сообщение открытым ключом стороны, с которой он общается . Опять же, после того, как он был зашифрован открытым ключом, единственный способ получить доступ к информации — через соответствующий закрытый ключ.
Таким образом, шифрование RSA может использоваться ранее неизвестными сторонами для безопасной передачи данных между собой. Значительная часть каналов связи, которые мы используем в нашей онлайн-жизни, были построены на этом фундаменте.
Как более сложные сообщения шифруются с помощью RSA?В нашем примере мы значительно упростили ситуацию, чтобы облегчить понимание, поэтому мы зашифровали только сообщение «4». Возможность шифрования числа 4 не кажется особенно полезной, поэтому вам может быть интересно, как можно зашифровать более сложный набор данных , например симметричный ключ (который является наиболее распространенным использованием RSA) или даже сообщение.
Некоторые люди могут быть озадачены тем, как ключ типа «n38cb29fkbjh238g7fqijnf3kaj84f8b9f…» или сообщение типа «купи мне бутерброд» можно зашифровать с помощью такого алгоритма, как RSA, который работает с числами, а не с буквами. Реальность такова, что вся информация, которую обрабатывают наши компьютеры, хранится в двоичном формате (единицы и нули), и мы используем стандарты кодирования, такие как ASCII или Unicode , чтобы представить их понятным людям способом (буквы).
Это означает, что ключа типа «n38cb29fkbjh238g7fqijnf3kaj84f8b9f…» и сообщения типа «купи мне бутерброд» уже существуют как числа , которые можно легко вычислить в алгоритме RSA.Числа, которыми они представлены, намного больше, и нам труднее управлять, поэтому мы предпочитаем иметь дело с буквенно-цифровыми символами, а не с беспорядком двоичных символов.
Если вы хотите зашифровать более длинный сеансовый ключ или более сложное сообщение с помощью RSA, просто потребуется гораздо большее число .
НабивкаКогда реализован RSA, он использует что-то, называемое заполнением , чтобы помочь предотвратить ряд атак . Чтобы объяснить, как это работает, мы начнем с примера.Допустим, вы отправляли закодированное сообщение другу:
Уважаемая Карен,
Надеюсь, у вас все хорошо. Мы все еще обедаем завтра?
С уважением,
Джеймс
Допустим, вы закодировали сообщение простым способом, заменив каждую букву на ту, которая следует за ней в алфавите . Это изменит сообщение на:
Efbs Lbsfo,
J ipqf zpv bsf xfmm.Bsf xf tujmm ibwjoh ejoofs upnpsspx?
Zpvst tjodfsfmz,
Кбнфут
Если ваши враги перехватили это письмо, есть уловка, с помощью которой они могут попытаться взломать код. Они могли бы посмотреть на формат вашего письма и попытаться угадать, о чем могло быть сказано в сообщении. Они знают, что люди обычно начинают свои письма со слов «Привет», «Привет», «Дорогой» или ряда других условных обозначений.
Если бы они попытались применить «Привет» или «Привет» в качестве первого слова, они увидели бы, что оно не умещается в количестве символов. Затем они могли бы попробовать «Дорогой». Это подходит, но это не обязательно что-то значит. Злоумышленники просто попробуют и посмотрят, куда это их приведет. Таким образом, они заменили буквы «е», «f», «b» и «s» на «d», «e», «a» и «r» соответственно. Это даст им:
Уважаемый Laseo,
J ipqe zpv — xemm. Являются ли xe tujmm iawjoh djooes upnpsspx?
Zpvrt tjoderemz,
Канет
Это все еще выглядит довольно запутанным, поэтому злоумышленники могут попытаться взглянуть на некоторые другие соглашения, например , например, как мы завершаем наши письма .Люди часто добавляют в конце «От кого» или «С уважением», но ни один из них не подходит к формату. Вместо этого злоумышленники могут попробовать «Искренне Ваш» и заменить другие буквы, чтобы увидеть, где они их получат. Заменив «z», «p», «v», «t», «j», «o», «d» и «m» на «y», «o», «u», «s», « i »,« n »,« c »и« l »соответственно, они получат:
Уважаемый Lasen,
Я ioqe, ты xell. Являются ли xe tuill iawinh dinnes uonossox?
С уважением,
Канет
После этой модификации похоже, что злоумышленники уже куда-то попадают.Они нашли слова «я», «ты» и «есть» в дополнение к словам, из которых были сделаны их первоначальные предположения.
Видя, что слова расположены в правильном грамматическом порядке, злоумышленники могут быть уверены, что они движутся в правильном направлении. К настоящему времени они, вероятно, также поняли, что код включает в себя замену каждой буквы на ту, которая следует за ней в алфавите. Как только они это поймут, можно будет легко перевести остальное и прочитать исходное сообщение .
Приведенный выше пример был простым кодом, но, как вы можете видеть, структура сообщения может дать злоумышленникам подсказки о его содержании . Конечно, было сложно понять сообщение, исходя только из его структуры, и потребовались некоторые обоснованные предположения, но вы должны иметь в виду, что компьютеры делают это намного лучше, чем мы. Это означает, что их можно использовать для вычисления гораздо более сложных кодов за гораздо более короткое время. , основываясь на подсказках, которые исходят из структуры и других элементов.
Если структура может привести к взлому кода и раскрытию содержимого сообщения, то нам нужен способ скрыть структуру, чтобы сохранить сообщение в безопасности. Это подводит нас к , заполнение .
Когда сообщение дополняется, добавляются рандомизированные данные , чтобы скрыть исходные подсказки форматирования, которые могут привести к взлому зашифрованного сообщения . С RSA все немного сложнее, потому что зашифрованный ключ не имеет очевидного форматирования письма, которое помогло нам дать подсказки в нашем примере выше.
Несмотря на это, злоумышленники могут использовать ряд атак для использования математических свойств кода и взлома зашифрованных данных. Из-за этой угрозы реализации RSA используют схемы заполнения, такие как OAEP, для встраивания дополнительных данных в сообщение . Добавление этого заполнения до того, как сообщение будет зашифровано, делает RSA намного более безопасным.
Подписание сообщенийRSA можно использовать не только для шифрования данных. Его свойства также делают его полезной системой для , подтверждающей, что сообщение было отправлено субъектом, который утверждает, что он его отправил, а также доказательства того, что сообщение не было изменено или подделано с помощью .
Когда кто-то хочет доказать подлинность своего сообщения, он может вычислить хэш (функция, которая принимает данные произвольного размера и превращает их в значение фиксированной длины) открытого текста, а затем подписать его своим закрытым ключом. . Они подписывают хэш, применяя ту же формулу, которая используется при расшифровке ( m = c d mod n ). После того, как сообщение было подписано, они отправляют эту цифровую подпись получателю вместе с сообщением.
Если получатель получает сообщение с цифровой подписью, он может использовать подпись , чтобы проверить, было ли сообщение подлинно подписано закрытым ключом человека, который утверждает, что отправил его . Они также могут видеть, было ли сообщение изменено злоумышленниками после его отправки.
Для проверки цифровой подписи получатель сначала использует ту же хеш-функцию, чтобы найти хеш-значение полученного сообщения. Затем получатель применяет открытый ключ отправителя к цифровой подписи, , используя формулу шифрования ( c = m e mod n), , чтобы дать им хэш цифровой подписи.
По , сравнивая хэш сообщения, которое было получено, с хешем от зашифрованной цифровой подписи , получатель может определить, является ли сообщение подлинным. Если два значения совпадают, сообщение не было изменено, так как оно было подписано первоначальным отправителем. Если бы сообщение было изменено хотя бы одним символом, хеш-значение было бы совершенно другим.
Защита RSA и атакиКак и большинство криптосистем, безопасность RSA зависит от того, как он реализован и используется.Одним из важных факторов является размер ключа. Чем больше количество битов в ключе (по сути, какова длина ключа), тем труднее взломать атаки , такие как перебор и факторинг.
Поскольку алгоритмы с асимметричным ключом, такие как RSA, могут быть нарушены целочисленной факторизацией, в то время как алгоритмы с симметричным ключом, такие как AES, не могут, ключи RSA должны быть намного длиннее, чтобы достичь того же уровня безопасности.
В настоящее время наибольший размер ключа , который был разложен на множители, составляет 768 битов .Это было сделано группой ученых в течение двух лет с использованием сотен машин.
Поскольку факторинг был завершен к концу 2009 года и вычислительная мощность с тех пор значительно выросла, можно предположить, что попытка аналогичной интенсивности теперь могла бы разложить на множитель гораздо больший ключ RSA .
Несмотря на это, время и ресурсы, необходимые для такого рода атак, делают их недоступными для большинства хакеров и доступными для национальных государств. Оптимальная длина ключа будет зависеть от вашей индивидуальной модели угрозы.Национальный институт стандартов и технологий рекомендует минимальный размер ключа 2048-бит , но также используются 4096-битные ключи в некоторых ситуациях, когда уровень угрозы выше.
Факторинг — это лишь один из способов взлома RSA. Ряд других атак может взломать шифрование с меньшим объемом ресурсов, но они зависят от реализации и других факторов, не обязательно самого RSA. Некоторые из них включают:
Действительно ли простые числа случайны?Некоторые реализации RSA используют слабые генераторы случайных чисел для получения простых чисел.Если эти числа не являются достаточно случайными, злоумышленникам будет намного проще их факторизовать и взломать шифрование. Этой проблемы можно избежать, используя криптографически безопасный генератор псевдослучайных чисел.
Плохая генерация ключа Для обеспечения безопасности ключиRSA должны соответствовать определенным параметрам. Если простые числа p и q расположены слишком близко друг к другу, ключ может быть легко обнаружен .Точно так же номер d , составляющий часть закрытого ключа, не может быть слишком маленьким . Низкое значение упрощает решение. Важно, чтобы эти номера имели достаточную длину, чтобы ваш ключ был в безопасности.
Атаки по побочному каналуЭто тип атак, который не нарушает RSA напрямую, а вместо этого использует информацию о его реализации, чтобы дать злоумышленникам подсказки о процессе шифрования. Эти атаки могут включать в себя такие вещи, как анализ используемой мощности или анализ предсказания ветвления , который использует измерения времени выполнения для обнаружения закрытого ключа.
Другой тип атаки по побочному каналу известен как временная атака. Если злоумышленник имеет возможность измерить время дешифрования на компьютере своей цели для ряда различных зашифрованных сообщений, эта информация может позволить злоумышленнику установить закрытый ключ цели.
Большинство реализаций RSA избегают этой атаки, добавляя одноразовое значение в процессе шифрования, которое устраняет эту корреляцию. Этот процесс называется криптографическим ослеплением .
Безопасно ли в будущем шифрование RSA?Хорошая новость заключается в том, что RSA в настоящее время считается безопасным для использования, несмотря на эти возможные атаки. Предостережение заключается в том, что необходимо правильно реализовать и использовать ключ, который соответствует правильным параметрам. Как мы только что обсуждали, реализации, в которых не используются отступы, используются простые числа недостаточного размера или есть другие уязвимости, не могут считаться безопасными.
Если вы хотите использовать шифрование RSA, убедитесь, что вы используете ключ не менее 1024 бит .Тем, у кого есть более высокие модели угроз, следует придерживаться ключей длиной 2048 или 4096 бит, если они хотят уверенно использовать RSA.
Если вы осознаёте слабые стороны RSA и правильно его используете, вы должны чувствовать себя в безопасности при использовании RSA для совместного использования ключей и других подобных задач, требующих шифрования с открытым ключом.
Хотя RSA пока безопасен, ожидается, что развитие квантовых вычислений вызовет некоторые проблемы в будущем.
Повлияют ли квантовые вычисления на RSA?
Область квантовых вычислений продолжает неуклонно совершенствоваться, но пройдут еще несколько лет, прежде чем они найдут широкое применение вне исследовательского контекста.Хотя квантовые компьютеры обладают огромным потенциалом для расширения наших возможностей, они также внесут некоторые сложности в мир криптографии.
Это связано с тем, что квантовые компьютеры могут легко решать определенные проблемы, которые в настоящее время считаются чрезвычайно сложными, и эта трудность часто является тем, что делает наши криптографические системы безопасными. В случае алгоритмов с симметричным ключом, таких как AES, мощные квантовые компьютеры, на которых работает алгоритм Гровера, смогут значительно ускорить атаки.
Хотя это, безусловно, представляет угрозу для наших текущих криптографических механизмов, это также относительно легко исправить. Все, что нам нужно сделать, это удвоить размер ключа, чтобы защитить эти алгоритмы с симметричным ключом.
Когда дело доходит до криптографии с открытым ключом, такой как RSA, мы сталкиваемся с гораздо большей проблемой. Как только квантовые компьютеры станут достаточно мощными, чтобы эффективно выполнять алгоритм Шора, можно будет решить следующие три математические задачи:
Это плохая новость, потому что безопасность наших наиболее часто используемых алгоритмов с открытым ключом основана на предпосылке, что в настоящее время их невозможно решить с использованием текущих вычислительных ресурсов.В случае RSA это проблема целочисленной факторизации.
Хотя квантовые вычисления и алгоритм Шора, безусловно, представляют собой будущую угрозу для RSA, хорошей новостью является то, что у нас есть время изменить нашу криптографическую инфраструктуру, чтобы обеспечить нашу безопасность в будущем.
Хотя трудно сказать, когда именно квантовые компьютеры смогут взломать RSA, значительные исследования и разработки уже ведутся. Национальный институт стандартов и технологий США (NIST) в настоящее время занимается поиском и оценкой различных алгоритмов с открытым ключом, которые будут безопасными в постквантовом мире.
На момент написания NIST находится в третьем раунде и в настоящее время оценивает 15 кандидатов как для криптографии с открытым ключом, так и для цифровых подписей. Стандартизация — медленный процесс, поэтому до выбора окончательных алгоритмов пройдет еще несколько лет. А пока нам не о чем беспокоиться, потому что угрозы со стороны квантовых вычислений еще дальше.
См. Также: Объяснение распространенных типов шифрования
AES vs.Шифрование RSA: в чем разница?
Одна вещь, которая стала совершенно очевидной в эпоху Интернета, заключается в том, что предотвратить несанкционированный доступ к данным, хранящимся в компьютерных системах с доступом в Интернет, чрезвычайно сложно. Все, что требуется, — это щелкнуть неправильную ссылку в электронном письме или неосторожно ответить на кажущийся законным запрос информации, и злоумышленник может получить полный доступ ко всем вашим данным. В сегодняшней нормативно-правовой среде и связях с общественностью подобное нарушение может иметь катастрофические последствия.
Но что, если бы вы могли быть уверены, что даже если злоумышленник получит доступ к вашей информации, он не сможет ее использовать? В этом роль шифрования данных.
Как работает шифрование
Основная идея шифрования состоит в том, чтобы преобразовать данные в форму, в которой первоначальное значение замаскировано, и только те, кто должным образом авторизован, могут его расшифровать. Это делается путем скремблирования информации с использованием математических функций на основе числа, называемого ключом . Обратный процесс с использованием того же или другого ключа используется для расшифровки (или дешифрования) информации.Если для шифрования и дешифрования используется один и тот же ключ, процесс называется симметричным . Если используются разные ключи, процесс определяется как асимметричный .
Двумя наиболее широко используемыми сегодня алгоритмами шифрования являются AES и RSA. Оба они очень эффективны и безопасны, но обычно используются по-разному. Давайте посмотрим, как они сравниваются.
AES шифрование
AES (Advanced Encryption Standard) стал предпочтительным алгоритмом шифрования для правительств, финансовых учреждений и предприятий, заботящихся о безопасности, по всему миру.Агентство национальной безопасности США (NSC) использует его для защиты «совершенно секретной» информации страны.
Алгоритм AES последовательно применяет серию математических преобразований к каждому 128-битному блоку данных. Поскольку вычислительные требования этого подхода невысоки, AES можно использовать с потребительскими вычислительными устройствами, такими как ноутбуки и смартфоны, а также для быстрого шифрования больших объемов данных. Например, серия мэйнфреймов IBM z14 использует AES для включения повсеместного шифрования, при котором зашифровываются все данные во всей системе, будь то в состоянии покоя или в пути.
AES — это симметричный алгоритм, который использует один и тот же 128, 192 или 256-битный ключ как для шифрования, так и для дешифрования (безопасность системы AES увеличивается экспоненциально с увеличением длины ключа). Даже с 128-битным ключом задача взлома AES путем проверки каждого из 2 128 возможных значений ключа (атака методом «грубой силы») настолько вычислительно трудоемка, что даже самый быстрый суперкомпьютер потребует в среднем более 100 триллионов лет на это. Фактически, AES никогда не подвергался взлому, и, исходя из текущих технологических тенденций, ожидается, что он останется безопасным на долгие годы.
Прочтите нашу электронную книгу
Эта электронная книга представляет собой введение в шифрование, включая передовые методы шифрования IBM i.
RSA шифрование
RSA назван в честь ученых Массачусетского технологического института (Ривест, Шамир и Адлеман), которые впервые описали его в 1977 году. Это асимметричный алгоритм, который использует общеизвестный ключ для шифрования, но требует другого ключа, известного только предполагаемому получателю. для расшифровки. В этой системе, соответственно называемой криптографией с открытым ключом (PKC), открытый ключ является результатом умножения двух огромных простых чисел вместе.Публикуется только этот продукт длиной 1024, 2048 или 4096 бит. Но расшифровка RSA требует знания двух основных факторов этого продукта. Поскольку не существует известного метода вычисления простых множителей таких больших чисел, только создатель открытого ключа может также сгенерировать закрытый ключ, необходимый для дешифрования.
RSA требует больших вычислительных ресурсов, чем AES, и намного медленнее. Обычно он используется для шифрования небольших объемов данных.
Как AES и RSA работают вместе
Основная проблема с AES заключается в том, что как симметричный алгоритм он требует, чтобы и шифровальщик, и дешифратор использовали один и тот же ключ.Это порождает важную проблему управления ключами — как можно распространить этот важнейший секретный ключ, возможно, среди сотен получателей по всему миру, не подвергаясь огромному риску того, что он будет небрежно или намеренно скомпрометирован где-то в процессе? Ответ — объединить сильные стороны шифрования AES и RSA.
Во многих современных средах связи, включая Интернет, большая часть передаваемых данных шифруется быстрым алгоритмом AES. Чтобы получить секретный ключ, необходимый для расшифровки этих данных, авторизованные получатели публикуют открытый ключ, сохраняя связанный закрытый ключ, который знают только они.Затем отправитель использует этот открытый ключ и RSA для шифрования и передачи каждому получателю своего секретного ключа AES, который можно использовать для расшифровки данных.
Подробнее о шифровании читайте в нашей электронной книге: IBM i Encryption 101
.net — Как использовать RSA для расшифровки (не проверки) данных с помощью открытого ключа?
У меня есть приложение .Net и я работаю над модулем лицензирования. Моя лицензия должна выглядеть следующим образом: «от: 01.01.2014: по: 01.01.2016» Это означает, что лицензия позволяет использовать мое приложение с января 2014 года по январь 2016 года.
Чтобы уменьшить (а не исключить) риск того, что мое приложение будет легко взломано, я использую алгоритм RSA, чтобы зашифровать строку лицензии с помощью закрытого ключа (недоступного на уровне приложения) и расшифровать ее с помощью открытого ключа, который будет храниться где-нибудь в приложении.
Покопавшись подробнее в классе RSAServeProvider, я вижу, что только проверка данных может выполняться с открытым ключом (не дешифрованием). Однако некоторая информация недоступна в приложении для проверки.
Пример:
В моем приложении предположим следующий алгоритм:
1- Прочитать файл лицензии
2- Расшифровать файл лицензии
3- Получить дату, хранящуюся в файле лицензии
4- Сравнить с текущей датой
5- Если текущая дата раньше даты в лицензии, продолжайте, иначе выйдите из
Шаг 3 фактически невозможен, потому что RSA позволяет только проверку лицензии со значением, которое уже доступно в приложении: например: проверка идентичности файла лицензии с января 2016 г. (и не получение значения файла лицензии, каким бы он ни был)
Кто-нибудь знает, как расшифровать данные, используя только открытый ключ RSA?
Вот код, который я использую из MSDN:
Dim ByteConverter как новый ASCIIEncoding
Dim dataString As String = "Данные для подписи"
'Создавать байтовые массивы для хранения исходных, зашифрованных и дешифрованных данных.Уменьшить исходные данные как байты () = ByteConverter.GetBytes (dataString)
Dim signedData () как байт
'Создать новый экземпляр класса RSACryptoServiceProvider
'и автоматически создаст новую пару ключей.
Dim RSAalg как новый RSACryptoServiceProvider
Dim PrivateKey As RSAParameters = RSAalg.ExportParameters (True)
Dim PublicKey как RSAParameters = RSAalg.ExportParameters (False)
'Хешируйте и подпишите данные.
signedData = HashAndSignBytes (исходные данные, PrivateKey)
'Проверить данные и отобразить результат в консоли
Если VerifySignedHash (originalData, signedData, PublicKey), то
Приставка.WriteLine («Данные проверены.»)
Еще
Console.WriteLine («Данные не соответствуют подписи.»)
Конец, если
А если сделаю
RSA = Новый RSACryptoServiceProvider
RSA.ImportParameters (PublicKey)
Dim DecryptedData As Byte () = RSA.Decrypt (Данные, Ложь)
Получаю сообщение об ошибке: Дополнительная информация: Ключ не существует.
Заранее спасибо
RSA шифрование | Britannica
RSA encryption , в полном объеме Rivest-Shamir-Adleman encryption , тип криптографии с открытым ключом, широко используемый для шифрования данных электронной почты и других цифровых транзакций через Интернет.RSA названа в честь его изобретателей, Рональда Л. Ривеста, Ади Шамира и Леонарда М. Адлемана, которые создали его, когда учились на факультете Массачусетского технологического института.
Британская викторина
Коды, секреты и шифры: Викторина
Какой самый известный криптоалгоритм схемы с открытым ключом? Кто были изобретателями первого транспозиционного шифра? Проверьте свои знания.Пройдите викторину.
В системе RSA пользователь тайно выбирает пару простых чисел p и q настолько большой, что разложение произведения на множители n = p q выходит далеко за рамки прогнозируемых вычислительных возможностей на время жизни шифров. С 2000 года стандарты безопасности правительства США требуют, чтобы модуль имел размер 1024 бита, то есть p и q каждый должен иметь размер около 155 десятичных цифр, поэтому n — это примерно 310-значное число. .Поскольку наибольшие точные числа, которые в настоящее время могут быть разложены на множители, составляют лишь половину этого размера, и поскольку сложность факторизации примерно удваивается для каждых дополнительных трех цифр в модуле, считается, что модули из 310 знаков безопасны от факторизации в течение нескольких десятилетий.
Выбрав p и q , пользователь выбирает произвольное целое число e , меньшее n и относительно простое с p — 1 и q — 1, то есть так, что 1 является единственный общий множитель между e и произведением ( p — 1) ( q — 1).Это гарантирует, что существует другое число d , для которого произведение e d оставит остаток 1 при делении на наименьшее общее кратное p — 1 и q — 1. При знании p и q , число d можно легко вычислить с помощью алгоритма Евклида. Если кто-то не знает p и q , одинаково трудно найти e или d с учетом другого коэффициента n , который является основой криптобезопасности алгоритма RSA.
Обозначения d и e будут использоваться для обозначения функции, для которой назначена клавиша, но, поскольку клавиши полностью взаимозаменяемы, это только удобство для демонстрации. Чтобы реализовать секретный канал с использованием стандартной двухключевой версии криптосистемы RSA, пользователь A опубликует e и n в аутентифицированном общедоступном каталоге, но сохранит в секрете d . Любой, кто хочет отправить личное сообщение на номер A , закодирует его в числа меньше n , а затем зашифрует его с помощью специальной формулы, основанной на e и n . A может расшифровать такое сообщение на основе знания d , но предположение — и пока что свидетельство — состоит в том, что почти для всех шифров никто другой не может расшифровать сообщение, если он также не может разложить на .
Получите подписку Britannica Premium и получите доступ к эксклюзивному контенту. Подпишитесь сейчасАналогичным образом, чтобы реализовать канал аутентификации, A будет публиковать d и n и хранить в секрете e . При простейшем использовании этого канала для проверки личности B может проверить, что он находится на связи с A , просмотрев каталог, чтобы найти ключ дешифрования A d и отправив ему сообщение для шифрования. .Если он получит обратно шифр, который расшифровывает его сообщение с вызовом, используя d для его расшифровки, он будет знать, что он, по всей вероятности, был создан кем-то, знающим e , и, следовательно, другой коммуникант, вероятно, A . Цифровая подпись сообщения — более сложная операция, требующая криптобезопасной функции «хеширования». Это широко известная функция, которая отображает любое сообщение в сообщение меньшего размера, называемое дайджестом, в котором каждый бит дайджеста зависит от каждого бита сообщения таким образом, что изменение даже одного бита в сообщении может изменить , криптобезопасным способом половина битов в дайджесте.Под криптобезопасностью подразумевается , что для кого-либо с вычислительной точки зрения невозможно найти сообщение, которое будет создавать заранее назначенный дайджест, и так же сложно найти другое сообщение с тем же дайджестом, что и известное. Чтобы подписать сообщение — которое, возможно, даже не нужно держать в секрете — A шифрует дайджест секретом e , который он добавляет к сообщению. Затем любой может расшифровать сообщение, используя открытый ключ d , чтобы восстановить дайджест, который он также может вычислить независимо от сообщения.Если они согласны, он должен сделать вывод, что A является источником шифра, поскольку только A знал e и, следовательно, мог зашифровать сообщение.
На данный момент все предложенные двухключевые криптосистемы требуют очень высокой платы за отделение канала конфиденциальности или секретности от канала аутентификации или подписи. Значительно увеличенный объем вычислений, задействованных в процессе асимметричного шифрования / дешифрования, значительно сокращает пропускную способность канала (количество бит в секунду передаваемой информации сообщения).Примерно за 20 лет для сравнительно безопасных систем удавалось достичь пропускной способности в 1000–10 000 раз выше для алгоритмов с одним ключом, чем для алгоритмов с двумя ключами. В результате основное применение двухключевой криптографии находится в гибридных системах. В такой системе двухключевой алгоритм используется для аутентификации и цифровых подписей или для обмена случайно сгенерированным сеансовым ключом, который будет использоваться с одноключевым алгоритмом на высокой скорости для основной связи. В конце сеанса этот ключ сбрасывается.
Обмен ключами Диффи-Хеллмана и шифрование RSA | Venafi
Какой алгоритм вам подходит?
Шифрование не следует рассматривать как окончательный ответ на любую проблему информационной безопасности, а только как часть уравнения безопасности. Эту концепцию всегда следует учитывать при выборе алгоритма открытого ключа. Однако, прежде чем углубляться в какой-либо проект по шифрованию, проведите тщательный анализ рисков ваших данных и систем, чтобы определить, что вам нужно. Очевидно, что данные с высоким уровнем риска, такие как конфиденциальные данные клиентов, нуждаются в лучшем шифровании, чем маркетинговые планы, которые в случае разглашения окажут гораздо меньшее влияние на бизнес.
Во-вторых, с точки зрения производительности, тщательный анализ сетевой архитектуры и нагрузки, которую она может выдерживать, поможет решить, какой маршрут шифрования выбрать. В общем, шифрование с открытым ключом или асимметричное шифрование примерно в 10 000 раз медленнее, чем шифрование с закрытым ключом. Это связано с тем, что при асимметричном шифровании создаются и обмениваются два ключа по сравнению с одним ключом при частном или симметричном шифровании.
Обмен ключами Диффи-Хеллмана и RSA (названный в честь его изобретателей Ривест-Шамир-Адлеман) — два самых популярных алгоритма шифрования.Чем они отличаются друг от друга? Какой из них следует использовать организации? Чтобы дать ответ, давайте кратко рассмотрим как
Обмен ключами Диффи-Хеллмана
Обмен ключами Диффи-Хеллмана, также называемый экспоненциальным обменом ключами, представляет собой метод цифрового шифрования, который использует числа, возведенные в определенную степень, для создания ключей дешифрования на основе компонентов, которые никогда не передаются напрямую, что делает задачу предполагаемого взломщика кода математически ошеломляюще.Обмен ключами Диффи-Хеллмана устанавливает общий секрет между двумя сторонами, который может использоваться для секретной связи для обмена данными по общедоступной сети, и фактически использует методы открытого ключа, позволяющие обмениваться частным ключом шифрования.
Чтобы упростить объяснение того, как работает алгоритм, мы будем использовать небольшие положительные целые числа. На самом деле алгоритм использует большие числа. Кроме того, вы можете найти довольно простые объяснения в Википедии и Академии Хана.
Общаясь открыто, Алиса и Боб договариваются о двух положительных целых числах, простом числе и генераторе.Генератор — это число, которое при возведении в степень целого положительного числа, меньшего, чем простое число, никогда не дает одинаковый результат для любых двух таких целых чисел. Предположим, что Алиса будет использовать простое число 17, а Боб — генератор 3. Затем Алиса выбирает частное случайное число, скажем 15, и вычисляет 3 15 mod17 , что равно 6, и отправляет результат Бобу публично.
Затем Боб выбирает свое частное случайное число, скажем 13, вычисляет 3 13 mod17 и отправляет результат (который равен 12) публично Алисе.Суть уловки — это следующее вычисление. Алиса берет публичный результат Боба (= 12) и вычисляет 12 15 mod17 . Результат (= 10) — их общий секретный ключ. С другой стороны, Боб берет публичный результат Алисы (= 6) и вычисляет 6 13 mod17 , что снова приводит к тому же общему секрету. Теперь Алиса и Боб могут общаться, используя симметричный алгоритм по своему выбору и общий секретный ключ, который никогда не передавался по незащищенной цепи.
Если третья сторона прослушивает обмен, для этой стороны будет сложно определить секретный ключ с вычислительной точки зрения. Фактически, при использовании больших чисел это действие требует больших вычислительных ресурсов для современных суперкомпьютеров, чтобы выполнить его за разумное время.
RSA
RSA — это криптосистема для шифрования с открытым ключом, которая широко используется для защиты конфиденциальных данных, особенно при передаче по незащищенной сети, такой как Интернет. RSA был впервые описан в 1977 году Роном Ривестом, Ади Шамиром и Леонардом Адлеманом из Массачусетского технологического института.Криптография с открытым ключом, также известная как асимметричная криптография, использует два разных, но математически связанных ключа, один открытый и один закрытый. Открытый ключ может быть передан всем, а закрытый ключ должен храниться в секрете. В криптографии RSA как открытый, так и закрытый ключи могут шифровать сообщение; ключ, противоположный тому, который использовался для шифрования сообщения, используется для его расшифровки. Этот атрибут является одной из причин, по которой RSA стал наиболее широко используемым асимметричным алгоритмом: он обеспечивает метод обеспечения конфиденциальности, целостности, подлинности и неуверенности электронных коммуникаций и хранения данных.
RSA обусловлена сложностью факторизации больших целых чисел, являющихся произведением двух больших простых чисел. Умножить эти два числа легко, но определение исходных простых чисел из общей суммы, то есть факторинг, считается невозможным из-за того, что на это потребуется время даже при использовании современных суперкомпьютеров. Алгоритм RSA включает четыре этапа: генерация ключа, распределение ключей, шифрование и дешифрование. Алгоритмы генерации открытого и закрытого ключей являются наиболее сложной частью криптографии RSA и выходят за рамки этой статьи.Вы можете найти пример на Tech Target.
Какие отличия?
И RSA, и алгоритм Диффи-Хеллмана являются алгоритмами шифрования с открытым ключом, достаточно сильными для коммерческих целей, поскольку они оба основаны на предположительно неразрешимых проблемах, сложности факторизации больших чисел и возведения в степень и модульной арифметики соответственно. Минимальная рекомендуемая длина ключа для систем шифрования составляет 128 бит, и обе они превышают длину своих 1024-битных ключей. Оба они были тщательно изучены математиками и криптографами, но при правильной реализации ни один из них не является значительно менее безопасным, чем другой.
Однако характер обмена ключами Диффи-Хеллмана делает его уязвимым для атак «человек посередине» (MITM), поскольку он не аутентифицирует ни одну из сторон, участвующих в обмене. Маневр MITM также может создавать пару ключей и ложные сообщения между двумя сторонами, которые думают, что они оба общаются друг с другом. Вот почему метод Диффи-Хеллмана используется в сочетании с дополнительным методом аутентификации, обычно с цифровыми подписями.
В отличие от алгоритма Диффи-Хеллмана, алгоритм RSA может использоваться для подписания цифровых подписей, а также для обмена симметричным ключом, но он требует предварительного обмена открытым ключом.Однако недавнее исследование показало, что даже 2048-битные ключи RSA могут быть эффективно понижены с помощью атак «человек в браузере» или «дополнения» оракула. В отчете говорится, что самой безопасной контрмерой является отказ от обмена ключами RSA и переход на обмен ключами Диффи-Хеллмана (эллиптическая кривая).
Заключение
Какой из них лучший? На этот вопрос сложно ответить, и на различных форумах было много дискуссий. Итак, ответ, как обычно, — «смотря по обстоятельствам».Обычно вы предпочитаете RSA, а не Диффи-Хеллмана, или Диффи-Хеллмана, а не RSA, в зависимости от ограничений взаимодействия и в зависимости от контекста. Производительность редко имеет значение, а что касается безопасности, с точки зрения высокого уровня, 1024-битный ключ Диффи-Хеллмана так же устойчив к криптоанализу, как 1024-битный ключ RSA. Выбор остается за вами.
Подробнее о защите личных данных машины. Исследуй сейчас.
Похожие сообщения
Серьезно, прекратите использовать RSA | Блог Trail of Bits
Здесь, в Trail of Bits, мы просматриваем много кода.Мы видели все, от крупных проектов с открытым исходным кодом до новых захватывающих проприетарных программ. Но одним общим знаменателем для всех этих систем является то, что по какой-то необъяснимой причине люди все еще считают RSA хорошей криптосистемой для использования. Позвольте мне сэкономить вам немного времени и денег и прямо скажу: если вы придете к нам с кодовой базой, использующей RSA, вы заплатите за час времени, необходимый нам, чтобы объяснить, почему вам следует прекратить ее использовать.
RSA — это по своей сути хрупкая криптосистема, содержащая бесчисленные ножные пушки, которых нельзя ожидать, что средний инженер-программист избежит их.Слабые параметры может быть трудно, если не невозможно, проверить, а его низкая производительность вынуждает разработчиков идти на рискованные действия. Хуже того, атаки дополнительных оракулов продолжают развиваться через 20 лет после того, как они были обнаружены. Хотя теоретически возможно правильно реализовать RSA, десятилетия разрушительных атак доказали, что такой подвиг может оказаться недостижимым на практике.
Что такое RSA снова?
RSA — это криптосистема с открытым ключом, которая имеет два основных варианта использования.Первый — это шифрование с открытым ключом, которое позволяет пользователю, Алисе, публиковать открытый ключ, который позволяет любому отправить ей зашифрованное сообщение. Второй вариант использования — это цифровые подписи, которые позволяют Алисе «подписывать» сообщение, чтобы любой мог убедиться, что сообщение не было подделано. В RSA удобно то, что алгоритм подписи — это, по сути, просто алгоритм шифрования, выполняемый в обратном порядке. Поэтому в оставшейся части этого поста мы часто будем называть оба эти слова просто RSA.
Чтобы настроить RSA, Алисе нужно выбрать два простых числа p и q , которые будут генерировать группу целых чисел по модулю N = pq .Затем ей нужно выбрать публичный показатель e и частный показатель d , так что ed = 1 mod (p-1) (q-1) . По сути, e и d должны быть инвертированы друг друга.
После выбора этих параметров другой пользователь, Боб, может отправить Алисе сообщение M , вычислив C = M e (mod N) . Затем Алиса может расшифровать зашифрованный текст, вычислив M = C d (mod N) . И наоборот, если Алиса хочет подписать сообщение M , она вычисляет S = M d (mod N) , которое любой пользователь может проверить, было подписано ею, проверив M = S e (mod N). .
Это основная идея. Мы немного поговорим о заполнении — важном для обоих случаев использования — но сначала давайте посмотрим, что может пойти не так при выборе параметра.
Настройка на провал
RSA требует от разработчиков выбора множества параметров во время настройки. К сожалению, кажущиеся невинными методы выбора параметров незаметно снижают безопасность. Давайте пройдемся по каждому выбору параметра и посмотрим, какие неприятные сюрпризы ждут тех, кто выберет неудачно.
Прайм Выбор
БезопасностьRSA основана на том факте, что при (большом) числе N, которое является произведением двух простых чисел p и q, факторизация N затруднена для людей, которые не знают p и q.Разработчики несут ответственность за выбор простых чисел, составляющих модуль RSA. Этот процесс чрезвычайно медленный по сравнению с генерацией ключей для других криптографических протоколов, где достаточно простого выбора некоторых случайных байтов. Поэтому вместо генерации действительно случайного простого числа разработчики часто пытаются сгенерировать одно из определенной формы. Это почти всегда плохо кончается.
Есть много способов выбрать простые числа таким образом, чтобы разложить N на множители. Например, p и q должны быть глобально уникальными .Если p или q когда-либо будут повторно использоваться в другом модуле RSA, то оба могут быть легко учтены с помощью алгоритма GCD. Плохие генераторы случайных чисел делают этот сценарий довольно распространенным, и исследования показали, что примерно 1% трафика TLS в 2012 году был подвержен такой атаке. Причем p и q нужно выбирать независимо. Если p и q имеют примерно половину своих старших битов, то N можно разложить на множители с помощью метода Ферма. Фактически, даже выбор алгоритма проверки простоты может иметь последствия для безопасности.
Пожалуй, наиболее широко разрекламированная атака Prime selection — это уязвимость ROCA в RSALib, которая затронула многие смарт-карты, модули доверенных платформ и даже Yubikeys. Здесь при генерации ключей использовались только простые числа определенной формы для ускорения времени вычисления. Сгенерированные таким образом простые числа легко обнаружить с помощью хитрых приемов теории чисел. После распознавания слабой системы специальные алгебраические свойства простых чисел позволяют злоумышленнику использовать метод Копперсмита для разложения N.Более конкретно, это означает, что если человек, сидящий рядом со мной на работе, использует смарт-карту, предоставляющую ему доступ к личным документам, и оставляет ее на своем столе во время обеда, я могу клонировать смарт-карту и предоставить себе доступ ко всем их конфиденциальным файлам.
Важно понимать, что ни в одном из этих случаев не является интуитивно очевидным, что генерация простых чисел таким образом приводит к полному сбою системы. Действительно тонкие теоретико-числовые свойства простых чисел имеют существенное влияние на безопасность RSA.Ожидать, что среднестатистический разработчик преодолеет это математическое минное поле, серьезно подорвет безопасность RSA.
Частный экспонент
Поскольку использование большого закрытого ключа отрицательно влияет на время дешифрования и подписи, у разработчиков есть стимул выбирать малый частный показатель степени d, особенно в настройках с низким энергопотреблением, таких как смарт-карты. Однако злоумышленник может восстановить закрытый ключ, когда d меньше 4-го корня N. Вместо этого разработчикам рекомендуется выбирать большое d, чтобы можно было использовать китайские методы теоремы об остатках для ускорения дешифрования.Однако сложность этого подхода увеличивает вероятность незначительных ошибок реализации, которые могут привести к восстановлению ключа. Фактически, один из наших стажеров прошлым летом смоделировал этот класс уязвимостей с помощью нашего инструмента символического исполнения Manticore.
Люди могут позвонить мне сюда и указать, что обычно при настройке RSA вы сначала генерируете модуль, используете фиксированный публичный показатель степени, а затем решаете для частного показателя. Это предотвращает атаки с низким частным показателем, потому что, если вы всегда используете один из рекомендуемых публичных показателей (обсуждается в следующем разделе), вы никогда не получите маленький частный показатель.К сожалению, это предполагает, что разработчики действительно так поступают. В обстоятельствах, когда люди реализуют свой собственный RSA, все ставки с точки зрения использования стандартных процедур настройки RSA отключены, и разработчики часто делают странные вещи, например, сначала выбирают частный показатель, а затем решают для публичного показателя.
Общественный экспонент
Как и в случае с частным показателем, разработчики хотят использовать небольшие публичные экспоненты для экономии времени на шифрование и проверку. В этом контексте обычно используются простые числа Ферма, в частности e = 3, 17 и 65537.Несмотря на то, что криптографы рекомендуют использовать 65537, разработчики часто выбирают e = 3, что вносит множество уязвимостей в криптосистему RSA.
Разработчики даже использовали e = 1, который на самом деле не шифрует открытый текст.
Когда e = 3 или такое же небольшое число, многие вещи могут пойти не так. Низкие общедоступные показатели часто сочетаются с другими распространенными ошибками, чтобы позволить злоумышленнику расшифровать определенные зашифрованные тексты или фактор N. Например, атака Франклина-Рейтера позволяет злоумышленнику расшифровать два сообщения, которые связаны известным фиксированным расстоянием.Другими словами, предположим, что Алиса отправляет Бобу только «шоколад» или «ваниль». Эти сообщения будут связаны по известному значению и позволят атакующей Еве определить, какие из них «шоколадные», а какие «ванильные». Некоторые атаки с низкой публичной экспонентой даже приводят к восстановлению ключа. Если публичная экспонента мала (не только 3), злоумышленник, который знает несколько бит секретного ключа, может восстановить оставшиеся биты и взломать криптосистему. Хотя многие из этих атак e = 3 на шифрование RSA смягчаются с помощью заполнения, разработчики, реализующие собственный RSA, не могут использовать заполнение с угрожающе высокой скоростью.
ПодписиRSA одинаково хрупки при наличии низких публичных показателей. В 2006 году Блейхенбахер обнаружил атаку, которая позволяет злоумышленникам подделывать произвольные подписи во многих реализациях RSA, включая те, которые используются в Firefox и Chrome. Это означает, что любой сертификат TLS из уязвимой реализации может быть подделан. Эта атака использует тот факт, что многие библиотеки используют небольшую публичную экспоненту и пропускают простую проверку заполнения при обработке подписей RSA.Атака с подделкой подписи Блейхенбахера настолько проста, что часто используется на курсах криптографии.
Выбор параметра затруднен
Общим знаменателем всех этих атак на параметры является то, что область возможных вариантов выбора параметров намного больше, чем область выбора безопасных параметров. Ожидается, что разработчики будут самостоятельно ориентироваться в этом чреватом процессе выбора, поскольку все, кроме публичной экспоненты, должны генерироваться в частном порядке. Нет простых способов проверить безопасность параметров; вместо этого разработчикам нужны глубокие математические знания, которых не следует ожидать от некриптографов.Хотя использование RSA с заполнением может спасти вас при наличии плохих параметров, многие люди по-прежнему предпочитают использовать разорванное заполнение или вообще не использовать заполнение.
Заполнение атак оракула повсюду
Как мы упоминали выше, использование RSA из коробки не совсем работает. Например, схема RSA, изложенная во введении, создаст идентичные зашифрованные тексты, если один и тот же открытый текст когда-либо был зашифрован более одного раза. Это проблема, потому что это позволит злоумышленнику сделать вывод о содержимом сообщения из контекста, не имея возможности его расшифровать.Вот почему нам нужно дополнять сообщения некоторыми случайными байтами. К сожалению, наиболее широко используемая схема заполнения, PKCS # 1 v1.5, часто уязвима для так называемой атаки оракула с заполнением.
ОракулыPadding довольно сложны, но основная идея состоит в том, что добавление заполнения к сообщению требует от получателя выполнения дополнительной проверки — правильно ли заполнено сообщение. Когда проверка завершается неудачно, сервер выдает ошибку недопустимое заполнение . Этой единственной информации достаточно, чтобы медленно расшифровать выбранное сообщение.Процесс утомительный и включает в себя миллионы манипуляций с целевым шифротекстом, чтобы изолировать изменения, которые приводят к действительному заполнению. Но это одно сообщение об ошибке — это все, что вам нужно, чтобы в конечном итоге расшифровать выбранный зашифрованный текст. Эти уязвимости особенно опасны, потому что злоумышленники могут использовать их для восстановления секретов перед мастером для сеансов TLS. Чтобы узнать больше об атаке, ознакомьтесь с этим отличным объяснителем.
Первоначальная атака на PKCS # 1 v1.5 была обнаружена еще в 1998 году Даниэлем Блейхенбахером.Несмотря на то, что этой атаке более 20 лет, эта атака продолжает поражать многие системы реального мира. Современные версии этой атаки часто включают в себя дополнительный оракул, немного более сложный, чем тот, который первоначально описал Блейхенбахер, например, время отклика сервера или выполнение какого-либо понижения версии протокола в TLS. Одним из особенно шокирующих примеров была атака ROBOT, которая была настолько ужасной, что группа исследователей смогла подписать сообщения секретными ключами Facebook и PayPal. Кто-то может возразить, что это не вина RSA — лежащая в основе математика в порядке, люди просто испортили важный стандарт несколько десятилетий назад.Дело в том, что с 1998 года у нас есть стандартизированная схема заполнения со строгим доказательством безопасности, OAEP. Но почти никто ею не пользуется. Даже когда они это делают, OAEP, как известно, сложно реализовать, и он часто уязвим для атаки Мангера, которая представляет собой еще одну атаку оракула с заполнением , которую можно использовать для восстановления открытого текста.
Основная проблема здесь заключается в том, что при использовании RSA требуется заполнение , и эта дополнительная сложность открывает криптосистему для большой поверхности атаки.Тот факт, что один бит информации, независимо от того, было ли сообщение заполнено правильно, может иметь такое большое влияние на безопасность, делает разработку безопасных библиотек практически невозможной. TLS 1.3 больше не поддерживает RSA, поэтому мы можем ожидать, что в будущем таких атак будет меньше, но пока разработчики продолжат использовать RSA в своих собственных приложениях, атаки оракулов будут существовать.
Итак, что вы должны использовать вместо этого?
Люди часто предпочитают использовать RSA, потому что считают его концептуально проще, чем несколько запутанный протокол DSA или криптография на основе эллиптических кривых (ECC).Но хотя интуитивно понять RSA может быть проще, ему не хватает устойчивости к неправильному использованию, чем другие более сложные системы.
Во-первых, распространенное заблуждение состоит в том, что ECC очень опасна, потому что выбор плохой кривой может полностью вас утопить. Хотя верно то, что выбор кривой имеет большое влияние на безопасность, одним из преимуществ использования ECC является то, что выбор параметров может быть сделан публично. Криптографы делают выбор всех сложных параметров, поэтому разработчикам просто нужно генерировать случайные байты данных для использования в качестве ключей и одноразовых значений.Теоретически разработчики могут создать реализацию ECC с ужасными параметрами и не проверять такие вещи, как недопустимые точки кривой, но они, как правило, этого не делают. Вероятное объяснение состоит в том, что математика, лежащая в основе ECC, настолько сложна, что очень немногие люди чувствуют себя достаточно уверенно, чтобы на самом деле ее реализовать. Другими словами, он запугивает людей, заставляя их использовать библиотеки, созданные криптографами, которые знают, что делают. С другой стороны, RSA настолько прост, что его можно (плохо) реализовать за час.
Во-вторых, любая схема согласования ключей или подписи на основе Диффи-Хеллмана (включая варианты с эллиптической кривой) не требует заполнения и, следовательно, полностью избегает атак оракула с заполнением. Это большая победа, учитывая, что у RSA очень плохая репутация по предотвращению этого класса уязвимостей.
Trail of Bits рекомендует использовать Curve25519 для обмена ключами и цифровых подписей. Шифрование должно выполняться с использованием протокола ECIES, который сочетает обмен ключами эллиптической кривой с алгоритмом симметричного шифрования.Curve25519 был разработан, чтобы полностью предотвратить некоторые проблемы, которые могут пойти не так с другими кривыми, и очень эффективен. Более того, это реализовано в libsodium, которая имеет легко читаемую документацию и доступна для большинства языков.
Серьезно, прекратите использовать RSA
RSA стал важной вехой в развитии безопасных коммуникаций, но за последние два десятилетия криптографические исследования сделали его устаревшим. Алгоритмы эллиптических кривых как для обмена ключами, так и для цифровых подписей были стандартизированы еще в 2005 году и с тех пор интегрированы в интуитивно понятные и устойчивые к неправильному использованию библиотеки, такие как libsodium.Тот факт, что RSA все еще широко используется сегодня, указывает как на неспособность криптографов адекватно сформулировать риски, присущие RSA, так и на то, что разработчики переоценили свои возможности для его успешного развертывания.
Сообщество безопасности должно начать думать об этом как о проблеме коллективного иммунитета — хотя некоторые из нас могут справиться с чрезвычайно опасным процессом настройки или внедрения RSA, исключения сигнализируют разработчикам, что это в некотором роде все еще целесообразно. использовать RSA.Несмотря на множество предостережений и предупреждений в README на StackExchange и Github, очень немногие люди верят, что именно они испортят RSA, и поэтому действуют безрассудно. В конечном итоге пользователи будут за это платить.